Toucan LLM
1.0.0

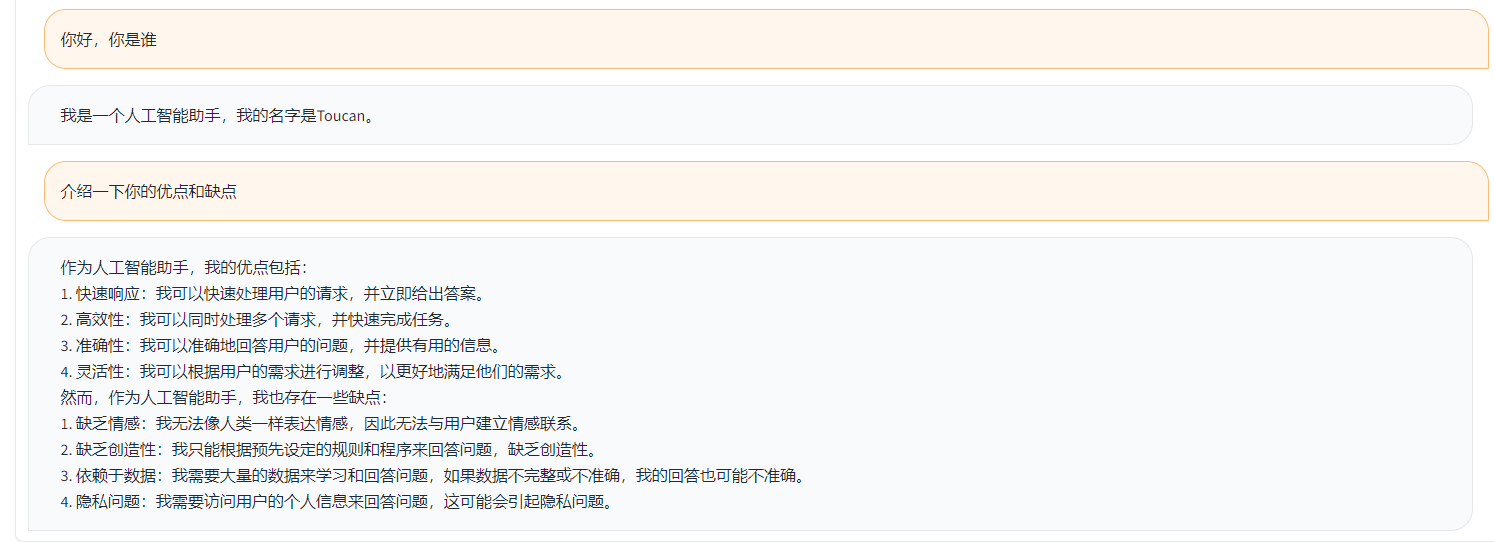
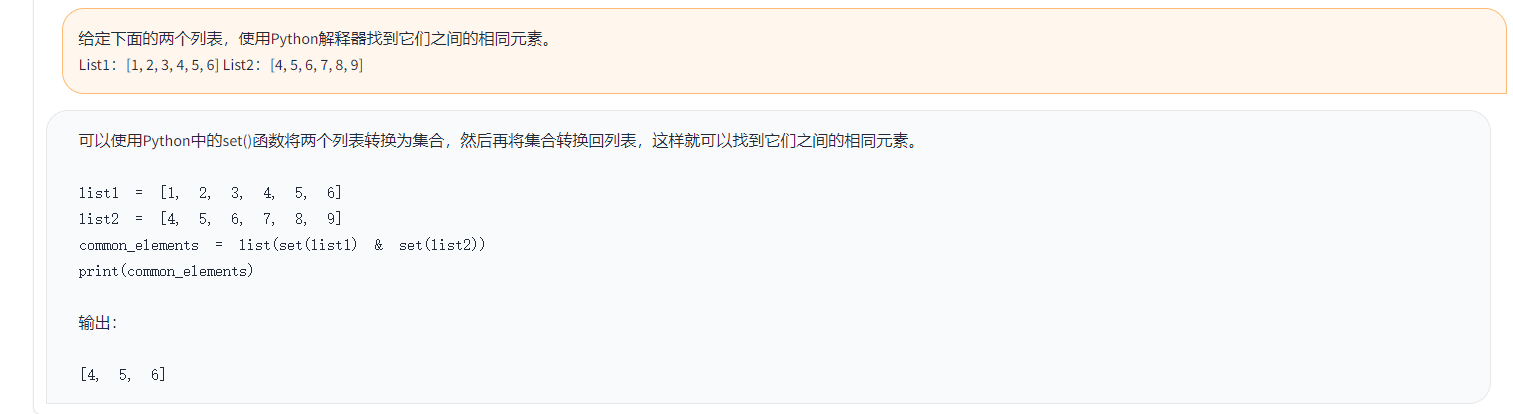
Toucan est un modèle de langue de dialogue open source, principalement soutenu par le chinois, basé sur l'architecture de Meta Ai (LLAMA) de [Meta, avec 7 milliards de paramètres. En combinant la technologie de quantification des modèles et la technologie clairsemée, il peut être déployé sur le côté final pour l'inférence à l'avenir. La conception du logo provient du site Web de conception du logo gratuit https://app.logo.com/
Le contenu fourni par ce projet comprend du code de formation final, du code d'inférence basé sur Gradio, du code de quantification 4 bits et du code de fusion du modèle, etc. Les poids du modèle peuvent être téléchargés dans le lien fourni, puis combinés à utiliser. Le Toucan-7B que nous fournissons est légèrement meilleur que le chatglm-6b. Le modèle quantifié à 4 bits est comparable au chatGLM-6B.
Le développement de ce modèle utilise le code open source et les ensembles de données open source. Ce projet n'assume aucun risque et responsabilités résultant de la sécurité des données, des risques d'opinion publique causés par les modèles et codes open source, ni les risques et responsabilités résultant de trompeurs, d'abus, de diffusion ou d'une mauvaise utilisation de tout modèle.
Les scores d'évaluation des objectifs sont principalement basés sur ce code open source https://github.com/lianjatech/belle/tree/main/eval
Les exemples sont les suivants:
{
"ChatGPT prompt" : "你是一个计算机科学老师,给定一道编程问题,你需要判断模型回答能否解决该问题,分数在0到1之间。标准答案仅作为参考。模型回答中的代码步骤可以和标准答案不同,但一定要是正确的。请按照"得分:"这样的形式输出分数",
"Problem prompt" : "具体的问题, 比如请你写出一个可以生成五个不同随机数的 Python 程序。 "
"class" : "有10类, 比如code " ,
"std_answer" : "数据集提供的标准答案"
"model_answer" : "被测模型(e.g. ChatGLM) 生成的答案"
"ChatGPT response" : " 得分: 0.5, 理由。。。 "
}Dans l'exemple ci-dessus, les réponses annotées fournies dans les données sont les suivantes.
标准回答:要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
下面是一个可以生成五个不同随机数的 Python 程序:
import random
# 定义一个空列表,用于存放随机数
nums = []
# 循环生成随机数,直到有五个不同的数
while len(nums) < 5:
a = random.randint(1, 10)
if a not in nums:
nums.append(a)
# 输出生成的随机数
print(nums)
程序生成的随机数在 1 到 10 之间,输出类似于这样:
[3, 2, 8, 10, 9]
这个程序首先导入了 random 模块,然后定义了一个空列表 nums。程序使用 while 循环,每次生成一个新的随机数 a,然后检查它是否已经存在于 nums 中。如果不存在,就把 a 加入到 nums 中。
循环结束后,列表 nums 中就包含了五个不同的随机数。程序使用 print() 函数将这些数输出到屏幕上。要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
Dans l'exemple ci-dessus, la réponse générée par Toucan comme exemple:
import random
random_numbers = []
for i in range ( 5 ):
random_numbers . append ( random . randint ( 1 , 100 ))
print ( random_numbers )Dans l'exemple ci-dessus, le résultat de la notation avec Chatgpt
得分: 0.5
理由:
模型回答中的代码可以生成五个不同的随机数,但是没有检查是否重复,因此有可能生成重复的数。标准答案中的代码使用了 while 循环和 if 语句来检查是否重复,保证了生成的随机数不会重复。因此,模型回答只能得到 0.5 分。
Selon la logique de test ci-dessus, nous avons testé près de 1 000 cas de test et les catégories sont résumées comme suit. Nous avons comparé les effets de test de différents modèles dans différentes catégories. L'effet de Toucan-7b est légèrement meilleur que celui de chatGLM-6B, mais est toujours plus faible que Chatgpt.
| Nom du modèle | Score moyen | mathématiques | code | Classification | extrait | QA ouvert | QA fermé | Génération | brainstorming | récrire | Récapitulation | Supprimer le score moyen des mathématiques et du code | Commentaires |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Phoenix-inst-chat-7b | 0,5017 | 0,275 | 0,675 | 0,329 | 0,19 | 0,54 | 0,35 | 0,825 | 0,81 | 0.8 | 0,27 | 0,514 | num_beams = 4, do_sample = false, min_new_tokens = 1, max_new_tokens = 512, |
| alpaca-7b | 0,4155 | 0,0455 | 0,535 | 0,52 | 0,2915 | 0.1962 | 0,5146 | 0,475 | 0,3584 | 0,8163 | 0,4026 | 0,4468 | |
| alpaca-7b-plus | 0,4894 | 0,1583 | 0.4 | 0,493 | 0.1278 | 0,3524 | 0,4214 | 0,9125 | 0,8571 | 0,8561 | 0,3158 | 0,542 | |
| Chatglm | 0,62 | 0,27 | 0,536 | 0,57 | 0,48 | 0,37 | 0.6 | 0,93 | 0.9 | 0,87 | 0,64 | 0,67 | |
| Toucan-7b | 0,6408 | 0,17 | 0,73 | 0.7 | 0,426 | 0,48 | 0,63 | 0,92 | 0,89 | 0,93 | 0,52 | 0,6886 | |
| Toucan-7b-4bit | 0,6225 | 0.1492 | 0,6826 | 0,6862 | 0,4139 | 0,4716 | 0,5711 | 0,9129 | 0,88 | 0,9088 | 0,5487 | 0,6741 | |
| Chatte | 0,824 | 0,875 | 0,875 | 0,813 | 0,767 | 0,69 | 0,751 | 0,971 | 0,944 | 0,861 | 0,795 | 0,824 |
Phoenix-inst-chat-7b: https://github.com/freedomintelligence/llmzoo
Alpaca-7b / alpaca-7b-aplus: https://github.com/ymcui/chinese-llama-alpaca
Chatglm: https://github.com/thudm/chatglm-6b
Comme le montre la figure ci-dessus, le Toucan-7B, nous fournissons des résultats légèrement meilleurs que le chatGLM-6B. Le modèle quantifié à 4 bits est comparable au chatGLM-6B.
Vous pouvez créer un environnement via Conda, puis installer les packages requis par PIP. Il existe des exigences.txt sous le fichier de train pour afficher les packages d'installation requis, Python version 3.10
conda crée -n toucan python = 3,10
Ensuite, exécutez la commande suivante à installer, il est recommandé d'installer d'abord la torche
pip install -r train / exigences.txt
La formation utilise principalement des données open source:
alpaca_gpt4_data.json
alpaca_gpt4_data_zh.json
Belle Data: Belle_cn
Parmi eux, moins de la moitié des données de Belle peuvent être sélectionnées de manière appropriée.
La taille du vocabulaire du modèle LLAMA original est de 32k, qui est principalement formée pour l'anglais, et la capacité de comprendre et de générer le chinois est limitée. Chinese-Llama-Alpaca a en outre élargi le vocabulaire chinois sur la base du lama d'origine et s'est produit avant la formation sur le corpus chinois. En raison des limites de la pré-formation en raison de conditions de ressources telles que les ressources, nous avons continué à effectuer des travaux de développement correspondants basés sur le modèle pré-entraîné chinois-llama-alpaca.
Le paramètre complet ajusté du modèle + Deeppeed, le script lancé par la formation est Train / Run.sh, et les paramètres peuvent être modifiés en fonction de la situation.
bash train/run.sh
torchrun --nproc_per_node=4 --master_port=8080 train.py
--model_name_or_path llama_to_hf_path
--data_path data_path
--bf16 True
--output_dir model_save_path
--num_train_epochs 2
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 4
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 2000
--save_total_limit 2
--learning_rate 8e-6
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed "./configs/deepspeed_stage3_param.json"
--tf32 True
——Model_name_or_path représente le modèle pré-formé, et le modèle de lama est au format de visage étreint - Data_path représente les données de formation - Output_Dir représente le journal de formation et le chemin enregistré par le modèle
1. S'il s'agit d'une formation à une seule carte, définissez nproc_per_node sur 1
2. Si l'environnement de course ne prend pas en charge profondément
Cette expérience se situe dans Nvidia GeForce RTX 3090, en utilisant des paramètres de configuration profonde de profondeur peut éviter efficacement les problèmes de l'OOM.
python scripts/demo.pyNous avons formé des poids delta open source et considérons les licences qui adhèrent aux modèles LLAMA. Vous pouvez utiliser la commande suivante pour répondre aux poids du modèle d'origine.
python scripts/apply_delta.py --base /path_to_llama/llama-7b-hf --target ./save_path/toucan-7b --delta /path_to_delta/toucan-7b-delta/ Diff-CKPT peut être téléchargé ici sur OneDrive
Téléchargez Baidu Netdisk ici
La figure ci-dessous montre l'utilisation de la mémoire vidéo mesurée après plusieurs cycles de conversations, qui ont toutes été testées sur la machine Nvidia GeForce RTX 3090. Le modèle 4 bits peut réduire efficacement l'utilisation de la mémoire.
toucan-16bit
Occupation initiale 
Longueur de jeton 1024 poutres de num = 4; La longueur du jeton 2048 sera oom; 
Longueur de jeton 2048 Num Beams = 1; 
toucan-4bit
Occupation initiale 
Longueur de jeton 2048 Num Beams = 4; 
Longueur de jeton 2048 Num Beams = 1; 
Une simple démo est illustrée à la figure ci-dessous.

La démo fait ici référence à l'implémentation dans chatGlm.