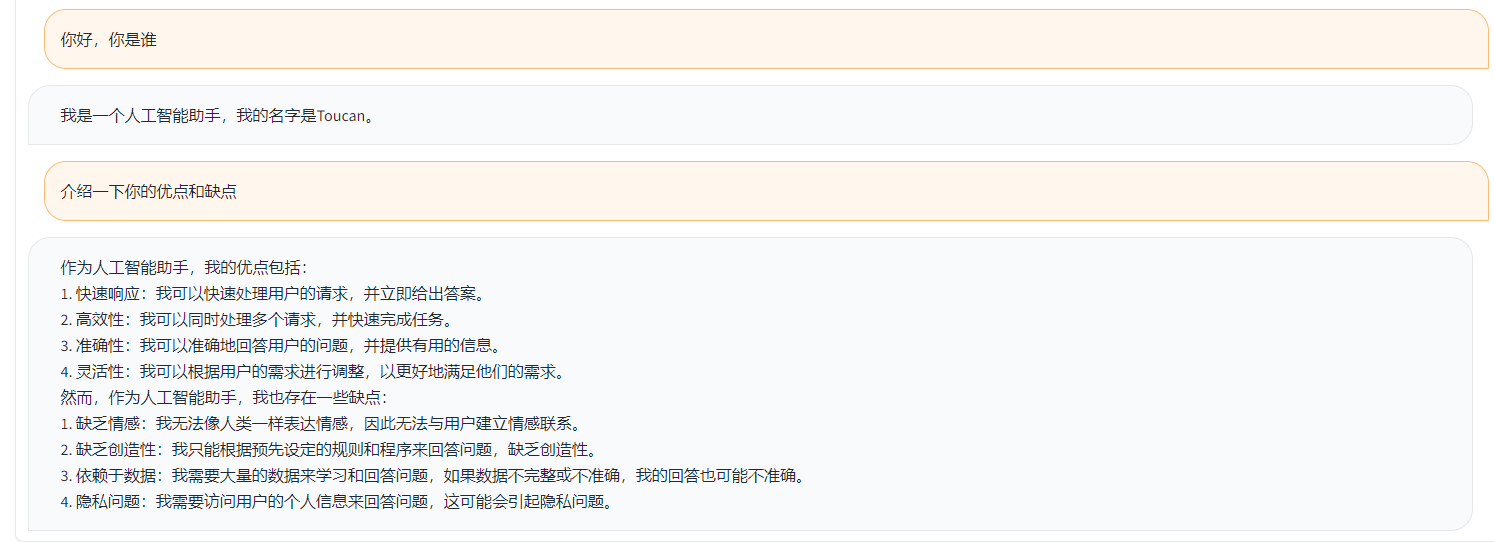
Toucan LLM
1.0.0

Toucan adalah open source, terutama model bahasa dialog yang didukung Cina berdasarkan arsitektur [model bahasa meta meta meta ai (llama)], dengan 7 miliar parameter. Menggabungkan teknologi kuantisasi model dan teknologi yang jarang, dapat digunakan di sisi akhir untuk inferensi di masa depan. Desain logo berasal dari situs web desain logo gratis https://app.logo.com/
Konten yang disediakan oleh proyek ini mencakup kode pelatihan penyempurnaan, kode inferensi berbasis gradio, kode kuantisasi 4bit dan kode penggabungan model, dll. Bobot model dapat diunduh dalam tautan yang disediakan dan kemudian digabungkan untuk digunakan. Toucan-7b yang kami berikan sedikit lebih baik daripada chatglm-6b. Model terukur 4-bit sebanding dengan chatglm-6b.
Pengembangan model ini menggunakan kode sumber terbuka dan set data sumber terbuka. Proyek ini tidak memikul risiko dan tanggung jawab yang timbul dari keamanan data, risiko opini publik yang disebabkan oleh model dan kode open source, atau risiko dan tanggung jawab yang timbul dari menyesatkan, penyalahgunaan, penyebaran, atau penggunaan model apa pun yang tidak tepat.
Skor evaluasi obyektif terutama didasarkan pada kode sumber terbuka ini https://github.com/lianjiatech/belle/tree/main/eval
Contohnya adalah sebagai berikut:
{
"ChatGPT prompt" : "你是一个计算机科学老师,给定一道编程问题,你需要判断模型回答能否解决该问题,分数在0到1之间。标准答案仅作为参考。模型回答中的代码步骤可以和标准答案不同,但一定要是正确的。请按照"得分:"这样的形式输出分数",
"Problem prompt" : "具体的问题, 比如请你写出一个可以生成五个不同随机数的 Python 程序。 "
"class" : "有10类, 比如code " ,
"std_answer" : "数据集提供的标准答案"
"model_answer" : "被测模型(e.g. ChatGLM) 生成的答案"
"ChatGPT response" : " 得分: 0.5, 理由。。。 "
}Dalam contoh di atas, jawaban beranotasi yang disediakan dalam data adalah sebagai berikut.
标准回答:要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
下面是一个可以生成五个不同随机数的 Python 程序:
import random
# 定义一个空列表,用于存放随机数
nums = []
# 循环生成随机数,直到有五个不同的数
while len(nums) < 5:
a = random.randint(1, 10)
if a not in nums:
nums.append(a)
# 输出生成的随机数
print(nums)
程序生成的随机数在 1 到 10 之间,输出类似于这样:
[3, 2, 8, 10, 9]
这个程序首先导入了 random 模块,然后定义了一个空列表 nums。程序使用 while 循环,每次生成一个新的随机数 a,然后检查它是否已经存在于 nums 中。如果不存在,就把 a 加入到 nums 中。
循环结束后,列表 nums 中就包含了五个不同的随机数。程序使用 print() 函数将这些数输出到屏幕上。要生成五个不同的随机数,可以使用 Python 的 random 模块中的 randint() 函数生成随机整数,然后检查是否重复,直到有五个不同的数为止。
Dalam contoh di atas, jawaban yang dihasilkan oleh Toucan sebagai contoh:
import random
random_numbers = []
for i in range ( 5 ):
random_numbers . append ( random . randint ( 1 , 100 ))
print ( random_numbers )Dalam contoh di atas, hasil dari penilaian dengan chatgpt
得分: 0.5
理由:
模型回答中的代码可以生成五个不同的随机数,但是没有检查是否重复,因此有可能生成重复的数。标准答案中的代码使用了 while 循环和 if 语句来检查是否重复,保证了生成的随机数不会重复。因此,模型回答只能得到 0.5 分。
Menurut logika uji di atas, kami menguji hampir 1.000 kasus uji, dan kategori dirangkum sebagai berikut. Kami membandingkan efek uji dari model yang berbeda di bawah kategori yang berbeda. Efek Toucan-7B sedikit lebih baik daripada chatglm-6b, tetapi masih lebih lemah dari chatgpt.
| Nama model | Skor rata -rata | Matematika | kode | Klasifikasi | ekstrak | Buka QA | QA tertutup | Generasi | Brainstorming | menulis kembali | Peringkasan | Hapus skor rata -rata matematika dan kode | Komentar |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Phoenix-inst-chat-7b | 0.5017 | 0.275 | 0.675 | 0.329 | 0.19 | 0,54 | 0.35 | 0.825 | 0.81 | 0.8 | 0.27 | 0,514 | num_beams = 4, do_sample = false, min_new_tokens = 1, max_new_tokens = 512, |
| Alpaca-7b | 0.4155 | 0,0455 | 0,535 | 0,52 | 0.2915 | 0.1962 | 0,5146 | 0.475 | 0.3584 | 0.8163 | 0.4026 | 0.4468 | |
| Alpaca-7b-plus | 0.4894 | 0.1583 | 0.4 | 0.493 | 0.1278 | 0.3524 | 0.4214 | 0.9125 | 0.8571 | 0.8561 | 0.3158 | 0,542 | |
| Chatglm | 0.62 | 0.27 | 0,536 | 0,57 | 0.48 | 0.37 | 0.6 | 0.93 | 0.9 | 0.87 | 0.64 | 0.67 | |
| Toucan-7b | 0.6408 | 0.17 | 0.73 | 0.7 | 0.426 | 0.48 | 0.63 | 0.92 | 0.89 | 0.93 | 0,52 | 0.6886 | |
| Toucan-7b-4bit | 0.6225 | 0.1492 | 0.6826 | 0.6862 | 0.4139 | 0.4716 | 0.5711 | 0.9129 | 0.88 | 0.9088 | 0,5487 | 0.6741 | |
| Chatgpt | 0.824 | 0.875 | 0.875 | 0.813 | 0.767 | 0.69 | 0.751 | 0.971 | 0.944 | 0.861 | 0.795 | 0.824 |
Phoenix-inst-crat-7b: https://github.com/freedomintelligence/llmzoo
Alpaca-7b/alpaca-7b-plus: https://github.com/ymcui/chinese-llama-alpaca
Chatglm: https://github.com/thudm/chatglm-6b
Seperti yang ditunjukkan pada gambar di atas, Toucan-7b kami memberikan hasil yang sedikit lebih baik daripada chatglm-6b. Model terukur 4-bit sebanding dengan chatglm-6b.
Anda dapat membuat lingkungan melalui Conda dan kemudian memasang paket yang diperlukan oleh PIP. Ada persyaratan.txt di bawah file kereta untuk melihat paket instalasi yang diperlukan, Python versi 3.10
conda create -n Toucan Python = 3.10
Kemudian jalankan perintah berikut untuk menginstal, disarankan untuk menginstal obor terlebih dahulu
PIP menginstal -r train/persyaratan.txt
Pelatihan terutama menggunakan data open source:
alpaca_gpt4_data.json
alpaca_gpt4_data_zh.json
Data Belle: Belle_cn
Di antara mereka, kurang dari setengah data Belle dapat dipilih dengan tepat.
Ukuran kosa kata dari model LLAMA asli adalah 32k, yang terutama dilatih untuk bahasa Inggris, dan kemampuan untuk memahami dan menghasilkan bahasa Mandarin terbatas. China-Llama-Alpaca lebih lanjut memperluas kosa kata Cina berdasarkan Llama asli dan melakukan pra-pelatihan pada korpus Cina. Karena keterbatasan pra-pelatihan karena kondisi sumber daya seperti sumber daya, kami terus melakukan pekerjaan pengembangan yang sesuai berdasarkan model pra-terlatih Cina-ALPACA.
Parameter lengkap fine-tuning dari model + Deepspeed, skrip yang dimulai oleh pelatihan adalah train/run.sh, dan parameter dapat dimodifikasi sesuai dengan situasinya.
bash train/run.sh
torchrun --nproc_per_node=4 --master_port=8080 train.py
--model_name_or_path llama_to_hf_path
--data_path data_path
--bf16 True
--output_dir model_save_path
--num_train_epochs 2
--per_device_train_batch_size 2
--per_device_eval_batch_size 2
--gradient_accumulation_steps 4
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 2000
--save_total_limit 2
--learning_rate 8e-6
--weight_decay 0.
--warmup_ratio 0.03
--deepspeed "./configs/deepspeed_stage3_param.json"
--tf32 True
——Model_name_or_path mewakili model pra-terlatih, dan model LLAMA sedang dalam memeluk format wajah-Data_Path mewakili data pelatihan-output_dir mewakili log pelatihan dan jalur yang disimpan oleh model tersebut
1. Jika itu pelatihan kartu tunggal, atur nproc_per_node ke 1
2. Jika lingkungan yang berjalan tidak mendukung kecepatan, lepaskan -kecepatan sedalam
Eksperimen ini adalah dalam NVIDIA GeForce RTX 3090, menggunakan parameter konfigurasi Deepspeed dapat secara efektif menghindari masalah OOM.
python scripts/demo.pyKami open source melatih bobot delta, dan mempertimbangkan lisensi yang mematuhi model llama. Anda dapat menggunakan perintah berikut untuk membalas bobot model asli.
python scripts/apply_delta.py --base /path_to_llama/llama-7b-hf --target ./save_path/toucan-7b --delta /path_to_delta/toucan-7b-delta/ diff-ckpt dapat diunduh di sini di OneDrive
Unduh Baidu Netdisk di sini
Gambar di bawah ini menunjukkan penggunaan memori video yang diukur setelah beberapa putaran percakapan, yang semuanya diuji inferensi pada mesin NVIDIA GeForce RTX 3090. Model 4bit dapat secara efektif mengurangi penggunaan memori.
Toucan-16bit
Pekerjaan awal 
Token Length 1024 Num Balok = 4; panjang token 2048 akan oom; 
Token Length 2048 Num Balok = 1; 
Toucan-4bit
Pekerjaan awal 
Token Length 2048 Num Balok = 4; 
Token Length 2048 Num Balok = 1; 
Demo sederhana ditunjukkan pada gambar di bawah ini.

Demo di sini mengacu pada implementasi di ChatGLM.