Optimus
1.0.0

該存儲庫包含重現EMNLP 2020紙張Optimus中顯示的結果所需的源代碼:通過潛在空間的預訓練模型組織句子。
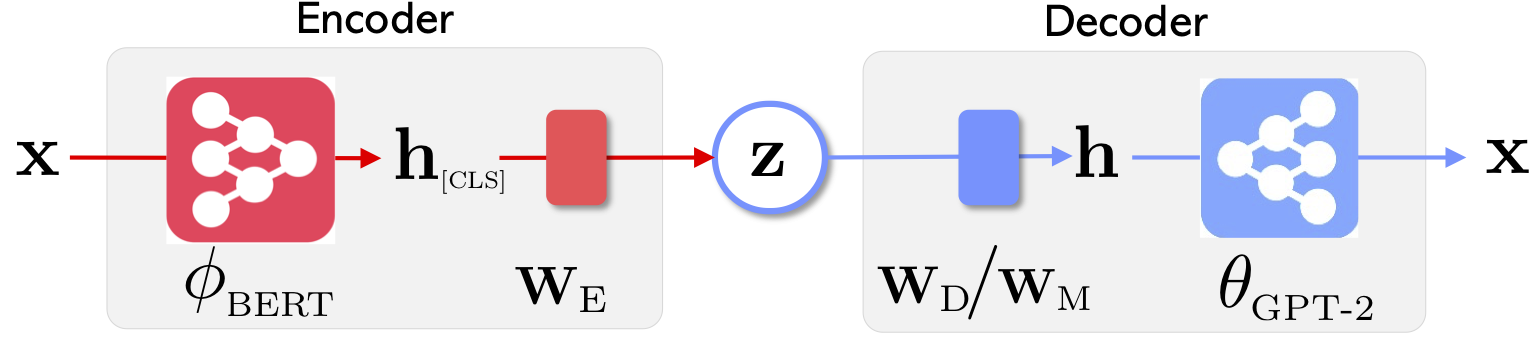 | 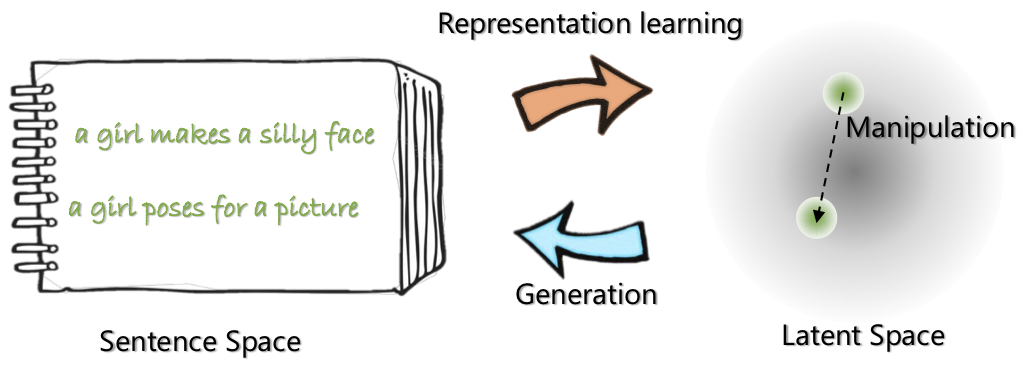 |
|---|---|
| Optimus的網絡體系結構:代表學習的編碼器和生成解碼器 | 句子是在預先訓練的緊湊和平穩的潛在空間中組織和操縱的 |
有關此項目的更多信息,請參見Microsoft研究博客文章。
2020年5月21日:釋放一個用於潛在空間操縱的demo ,包括句子插值和類比。查看website 。
2020年5月20日:清潔和釋放潛在的空間操縱代碼。請參閱optimius_for_snli.md的說明。
2020年5月13日:發布了Langauge建模的微調代碼。請參閱optimus_finetune_language_models.md上的說明
有四個步驟使用此代碼庫來重現論文中的結果。
從Docker Hub拉出Docker: chunyl/pytorch-transformers:v2 。請在doc/env.md上查看指令
該項目被組織到以下結構中,並且可視化了均勻的文件和文件夾。 output保存模型檢查點。
├── Optimus
└── code
├── examples
├── big_ae
├── modules
├── vae.py
└── ...
├── run_lm_vae_pretraining_phdist_beta.py
├── run_lm_vae_training.py
└── ...
├── pytorch_transformers
├── modeling_bert.py
├── modeling_gpt2.py
└── ...
├── scripts
├── scripts_docker
├── scripts_local
├── scripts_philly
└── data
└── datasets
├── wikipedia_json_64_filtered
└── ...
├── snli_data
└── ...
└── output
├── pretrain
├── LM
└── ...
請通過data/download_datasets.md下載或準備數據。
1。維基百科的設置預訓練
我們在Philly(Microsoft Internal Compute群集)上預先訓練了模型,該代碼專門用於該平台上的多節點多GPU計算。預訓練的主要python是run_lm_vae_pretraining_phdist_beta.py 。您可能需要調整分佈式培訓腳本。
2。 languange建模
為了與現有的Vae Languange模型進行公平的比較,我們考慮了一個具有潛在維度32的模型。預先訓練的模型在一個時期的四個通常數據集上進行了微調。請在doc/optimus_finetune_language_models.md上查看詳細信息
3。引導語言生成
為了確保良好的性能,我們考慮了一個具有潛在維度768的模型。預訓練的模型在SNLI數據集中進行了微調,其中句子顯示了相關的模式。請查看詳細信息,請參見doc/optimius_for_snli.md的詳細信息
4。低資源語言理解
一旦訓練網絡並保存了結果,我們就使用Python腳本提取了關鍵結果。可以使用隨附的ipython筆記本plots/main_plots.ipynb繪製結果。啟動ipython筆記本服務器:
$ cd plots
$ ipython notebook
選擇main_plots.ipynb筆記本並執行隨附的代碼。請注意,如果沒有修改,我們將提取的結果復製到了筆記本上,腳本將在論文中輸出數字。如果您進行了自己的培訓並希望繪製結果,則必須以相同格式組織結果。
如果您有任何疑問,請給我(Chunyuan)一行。
@inproceedings{li2020_Optimus,
title={Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space},
author={Li, Chunyuan and Gao, Xiang and Li, Yuan and Li, Xiujun and Peng, Baolin and Zhang, Yizhe and Gao, Jianfeng},
booktitle={EMNLP},
year={2020}
}


