Optimus
1.0.0

이 저장소에는 EMNLP 2020 Paper Optimus에 제시된 결과를 재현하는 데 필요한 소스 코드가 포함되어 있습니다. 잠재 된 공간의 미리 훈련 된 모델링을 통해 문장 구성.
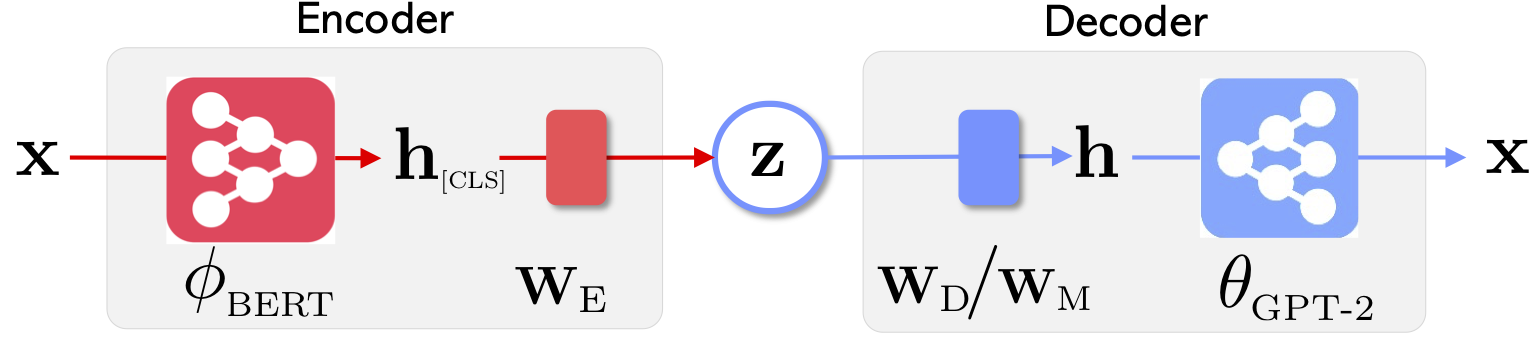 | 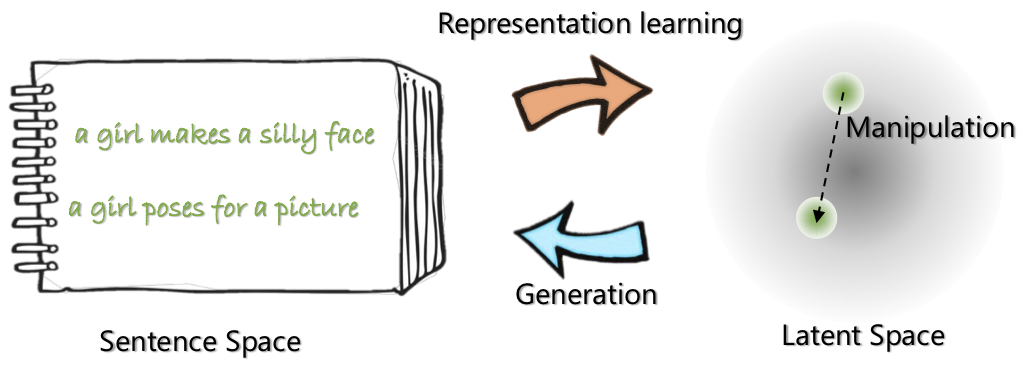 |
|---|---|
| Optimus의 네트워크 아키텍처 : 표현 학습을위한 인코더 및 세대를위한 디코더 | 문장은 미리 훈련 된 컴팩트하고 부드러운 잠복 공간으로 구성되고 조작됩니다. |
이 프로젝트에 대한 자세한 내용은 Microsoft Research 블로그 게시물을 참조하십시오.
2020 년 5 월 21 일 : 문장 보간 및 비유를 포함하여 잠재 우주 조작을위한 demo 공개. website 확인하십시오.
2020 년 5 월 20 일 : 잠재 우주 조작 코드가 정리 및 해제됩니다. optimius_for_snli.md 의 지침을 참조하십시오.
2020 년 5 월 13 일 : Langauge 모델링을위한 미세 조정 코드가 출시되었습니다. optimus_finetune_language_models.md 의 지침을 참조하십시오
이 코드베이스를 사용하여 논문의 결과를 재현하는 4 가지 단계가 있습니다.
Docker Hub에서 Docker를 당기십시오 : chunyl/pytorch-transformers:v2 . doc/env.md 의 지침을 참조하십시오
이 프로젝트는 다음 구조로 구성되며 enscipt files 및 폴더가 시각화되었습니다. output 모델 체크 포인트를 저장합니다.
├── Optimus
└── code
├── examples
├── big_ae
├── modules
├── vae.py
└── ...
├── run_lm_vae_pretraining_phdist_beta.py
├── run_lm_vae_training.py
└── ...
├── pytorch_transformers
├── modeling_bert.py
├── modeling_gpt2.py
└── ...
├── scripts
├── scripts_docker
├── scripts_local
├── scripts_philly
└── data
└── datasets
├── wikipedia_json_64_filtered
└── ...
├── snli_data
└── ...
└── output
├── pretrain
├── LM
└── ...
data/download_datasets.md 의 지침을 통해 데이터를 다운로드하거나 준비하십시오.
1. Wikipedia의 설정에 대한 사전 훈련
Philly (Microsoft 내부 컴퓨팅 클러스터)에서 모델을 미리 훈련 시켰으며,이 코드는이 플랫폼에서 멀티 노드 멀티 GPU 컴퓨팅을 위해 특화되어 있습니다. 사전 훈련 메인 파이썬은 run_lm_vae_pretraining_phdist_beta.py 입니다. 분산 교육 스크립트를 조정해야 할 수도 있습니다.
2. 언어 모델링
기존 VAE 언어 모델과 공정한 비교를 위해 잠재 차원 32의 모델을 고려합니다. 미리 훈련 된 모델은 하나의 에포크에 대한 4 개의 일반적인 데이터 세트에서 미세 조정됩니다. doc/optimus_finetune_language_models.md 의 세부 사항을 참조하십시오
3. 안내 언어 생성
잠재 우주 조작이 좋은 성능을 보장하기 위해 잠재 차원 768의 모델을 고려합니다. 미리 훈련 된 모델은 SNLI 데이터 세트에서 미세 조정되어 있으며 문장이 관련 패턴을 표시합니다. 세부 정보를 참조하십시오 doc/optimius_for_snli.md
4. 저주적 언어 이해
네트워크를 훈련하고 결과가 저장되면 Python 스크립트를 사용하여 주요 결과를 추출했습니다. 포함 된 IPYTHON 노트북 plots/main_plots.ipynb 사용하여 결과를 표시 할 수 있습니다. ipython 노트북 서버 시작 :
$ cd plots
$ ipython notebook
main_plots.ipynb 노트북을 선택하고 포함 된 코드를 실행하십시오. 수정없이 추출 된 결과를 노트에 복사했으며 스크립트는 용지의 수치를 출력합니다. 자신의 교육을 실행하고 결과를 플롯하려면 결과를 대신 동일한 형식으로 구성해야합니다.
궁금한 점이 있으면 저를 (Chunyuan) 라인으로 떨어 뜨리십시오.
@inproceedings{li2020_Optimus,
title={Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space},
author={Li, Chunyuan and Gao, Xiang and Li, Yuan and Li, Xiujun and Peng, Baolin and Zhang, Yizhe and Gao, Jianfeng},
booktitle={EMNLP},
year={2020}
}


