Optimus
1.0.0

Este repositorio contiene el código fuente necesario para reproducir los resultados presentados en el documento EMNLP 2020 Optimus: Organización de oraciones a través del modelado previamente capacitado de un espacio latente.
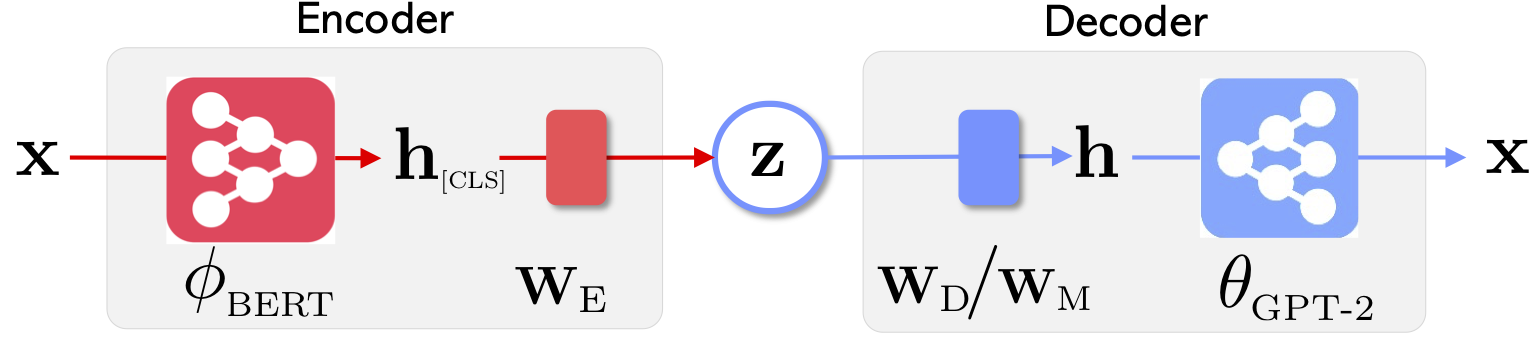 | 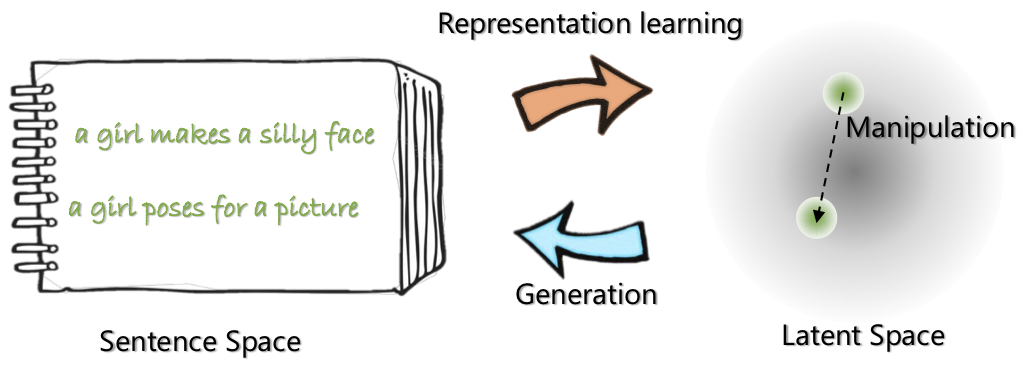 |
|---|---|
| La arquitectura de red de Optimus: codificador para el aprendizaje de representación y el decodificador para la generación | Las oraciones se organizan y manipulan en un espacio latente compacto y suave previamente capacitado y suave |
Para obtener más información sobre este proyecto, consulte la publicación del blog de Microsoft Research.
21 de mayo de 2020: Liberando una demo para la manipulación del espacio latente, incluida la interpolación y la analogía de las oraciones. Visite el website .
20 de mayo de 2020: el código de manipulación de espacio latente se limpia y libera. Consulte las instrucciones en optimius_for_snli.md .
13 de mayo de 2020: se lanza el código de ajuste fino para el modelado de Langauge. Consulte las instrucciones en optimus_finetune_language_models.md
Hay cuatro pasos para usar esta base de código para reproducir los resultados en el documento.
Tire de Docker desde Docker Hub en: chunyl/pytorch-transformers:v2 . Consulte las instrucciones en doc/env.md
El proyecto se organiza en las siguientes estructuras, con archivos y carpetas de forma, visualizada. output guarda los puntos de control de los modelos.
├── Optimus
└── code
├── examples
├── big_ae
├── modules
├── vae.py
└── ...
├── run_lm_vae_pretraining_phdist_beta.py
├── run_lm_vae_training.py
└── ...
├── pytorch_transformers
├── modeling_bert.py
├── modeling_gpt2.py
└── ...
├── scripts
├── scripts_docker
├── scripts_local
├── scripts_philly
└── data
└── datasets
├── wikipedia_json_64_filtered
└── ...
├── snli_data
└── ...
└── output
├── pretrain
├── LM
└── ...
Descargue o prepare los datos siguiendo las instrucciones en data/download_datasets.md .
1.
Pre-capacitamos nuestros modelos en Filadelfia (un clúster de cálculo interno de Microsoft), el código está especializado para un cómputo multi-GPU multi-nodo en esta plataforma. La pitón principal previa al entrenamiento es run_lm_vae_pretraining_phdist_beta.py . Es posible que deba ajustar los scripts de capacitación distribuida.
2. Modelado de lenguaje
Para tener una comparación justa con los modelos VAE Languange existentes, consideramos un modelo con la dimensión latente 32. El modelo previamente capacitado está ajustado en cuatro conjuntos de datos comúnmente para una época. Consulte los detalles en doc/optimus_finetune_language_models.md
3. Generación de idiomas guiados
Manipulación de espacio latente Para garantizar un buen rendimiento, consideramos un modelo con dimensión latente 768. El modelo previamente capacitado está ajustado en el conjunto de datos SNLI, donde las oraciones muestran patrones relacionados. Consulte los detalles en Consulte los detalles en doc/optimius_for_snli.md
4. Comprensión del lenguaje de baja recursos
Una vez que las redes están capacitadas y los resultados se guardan, extrajimos resultados clave utilizando el script de Python. Los resultados se pueden trazar utilizando los plots/main_plots.ipynb . Inicie el servidor del cuaderno de iPython:
$ cd plots
$ ipython notebook
Seleccione el cuaderno main_plots.ipynb y ejecute el código incluido. Tenga en cuenta que sin modificación, hemos copiado nuestros resultados extraídos en el cuaderno, y el script generará cifras en el documento. Si ha ejecutado su propia capacitación y desea trazar los resultados, tendrá que organizar sus resultados en el mismo formato.
Por favor, envíeme (Chunyuan) una línea si tiene alguna pregunta.
@inproceedings{li2020_Optimus,
title={Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space},
author={Li, Chunyuan and Gao, Xiang and Li, Yuan and Li, Xiujun and Peng, Baolin and Zhang, Yizhe and Gao, Jianfeng},
booktitle={EMNLP},
year={2020}
}


