Optimus
1.0.0

Repositori ini berisi kode sumber yang diperlukan untuk mereproduksi hasil yang disajikan dalam EMNLP 2020 Paper Optimus: Mengorganisir kalimat melalui pemodelan pra-terlatih dari ruang laten.
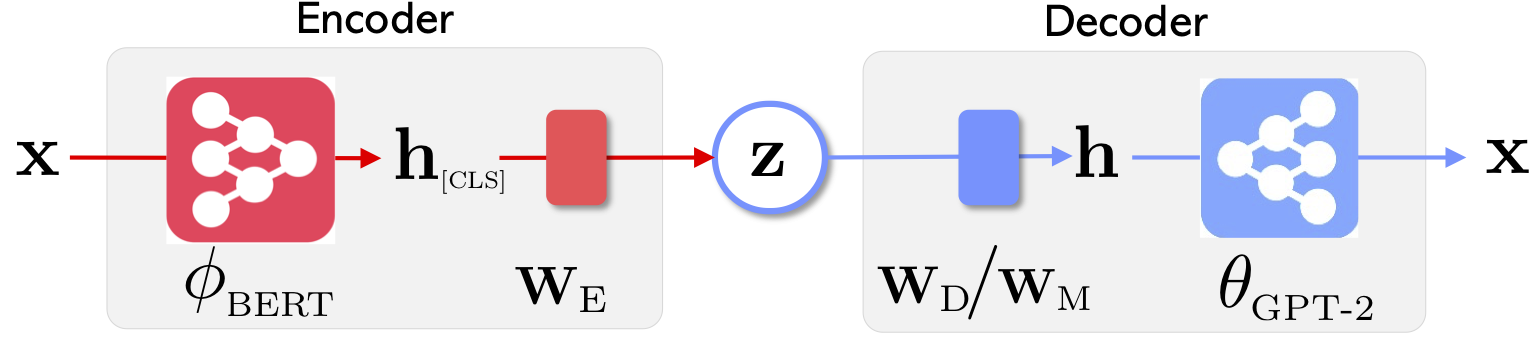 | 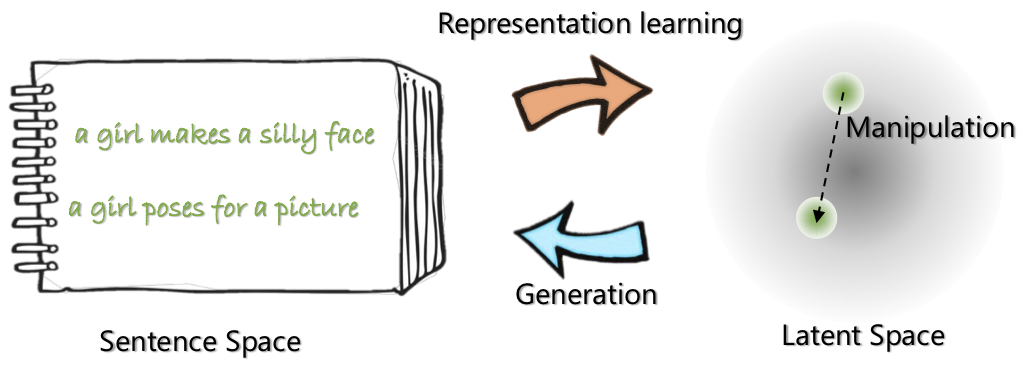 |
|---|---|
| Arsitektur Jaringan Optimus: Encoder untuk Pembelajaran Representasi dan Decoder untuk Generasi | Kalimat disusun dan dimanipulasi dalam ruang laten yang kompak dan halus terlatih |
Untuk lebih lanjut tentang proyek ini, lihat posting blog Microsoft Research.
21 Mei 2020: Melepaskan demo untuk manipulasi ruang laten, termasuk interpolasi dan analogi kalimat. Lihat website .
20 Mei 2020: Kode manipulasi ruang laten dibersihkan dan dilepaskan. Lihat instruksi di optimius_for_snli.md .
13 Mei 2020: Kode penyesuaian untuk pemodelan Langauge dirilis. Lihat instruksi di optimus_finetune_language_models.md
Ada empat langkah untuk menggunakan basis kode ini untuk mereproduksi hasil di koran.
Tarik Docker dari Docker Hub di: chunyl/pytorch-transformers:v2 . Silakan lihat instruksi di doc/env.md
Proyek ini diatur ke dalam struktur berikut, dengan file & folder ensensial divisualisasikan. output menyimpan pos pemeriksaan model.
├── Optimus
└── code
├── examples
├── big_ae
├── modules
├── vae.py
└── ...
├── run_lm_vae_pretraining_phdist_beta.py
├── run_lm_vae_training.py
└── ...
├── pytorch_transformers
├── modeling_bert.py
├── modeling_gpt2.py
└── ...
├── scripts
├── scripts_docker
├── scripts_local
├── scripts_philly
└── data
└── datasets
├── wikipedia_json_64_filtered
└── ...
├── snli_data
└── ...
└── output
├── pretrain
├── LM
└── ...
Silakan unduh atau persiapkan data melalui mengikuti instruksi di data/download_datasets.md .
1. Pra-pelatihan pada setencence di Wikipedia
Kami melakukan pra-terlatih model kami di Philly (kluster komputasi internal Microsoft), kode ini khusus untuk komputasi multi-node multi-GPU pada platform ini. Python utama pra-pelatihan adalah run_lm_vae_pretraining_phdist_beta.py . Anda mungkin perlu menyesuaikan skrip pelatihan yang didistribusikan.
2. Pemodelan Languue
Untuk memiliki perbandingan yang adil dengan model VAE Langeange yang ada, kami mempertimbangkan model dengan dimensi laten 32. Model pra-terlatih disesuaikan dengan empat dataset yang biasa untuk satu zaman. Silakan lihat detailnya di doc/optimus_finetune_language_models.md
3. Generasi Bahasa Terpandu
Manipulasi ruang laten untuk memastikan kinerja yang baik, kami mempertimbangkan model dengan dimensi laten 768. Model pra-terlatih disesuaikan dengan dataset SNLI, di mana kalimat menunjukkan pola terkait. Silakan lihat detailnya di silakan lihat detailnya di doc/optimius_for_snli.md
4. Pemahaman Bahasa Rendah Sumber Daya
Setelah jaringan dilatih dan hasilnya disimpan, kami mengekstraksi hasil utama menggunakan skrip Python. Hasilnya dapat diplot menggunakan plots/main_plots.ipynb . Mulai server notebook Ipython:
$ cd plots
$ ipython notebook
Pilih notebook main_plots.ipynb dan jalankan kode yang disertakan. Perhatikan bahwa tanpa modifikasi, kami telah menyalin hasil yang diekstraksi ke dalam buku catatan, dan skrip akan menghasilkan angka di koran. Jika Anda menjalankan pelatihan sendiri dan ingin merencanakan hasil, Anda harus mengatur hasil Anda dalam format yang sama sebagai gantinya.
Tolong kirimkan saya (chunyuan) satu baris jika Anda memiliki pertanyaan.
@inproceedings{li2020_Optimus,
title={Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space},
author={Li, Chunyuan and Gao, Xiang and Li, Yuan and Li, Xiujun and Peng, Baolin and Zhang, Yizhe and Gao, Jianfeng},
booktitle={EMNLP},
year={2020}
}


