Optimus
1.0.0

Этот репозиторий содержит исходный код, необходимый для воспроизведения результатов, представленных в EMNLP 2020 Paper Optimus: организация предложений посредством предварительно обученного моделирования скрытого пространства.
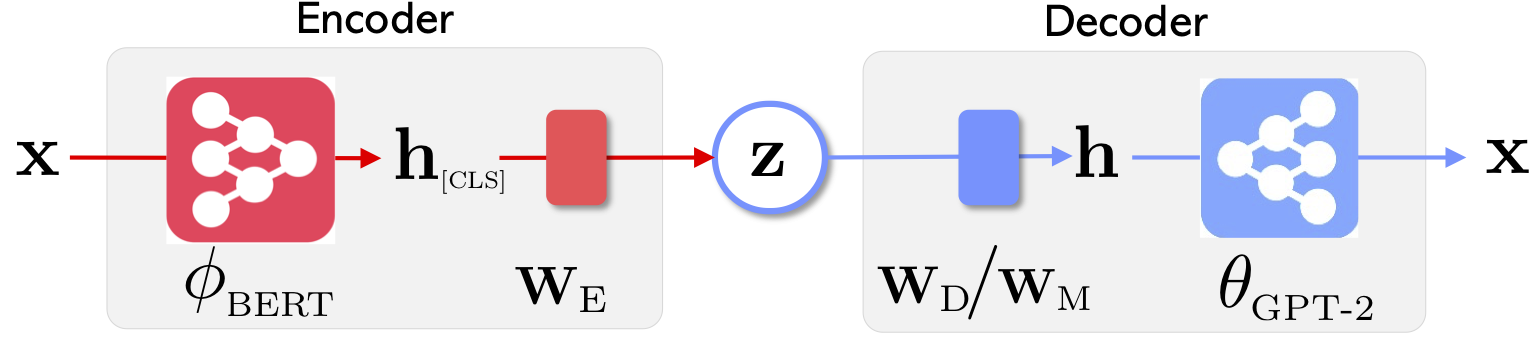 | 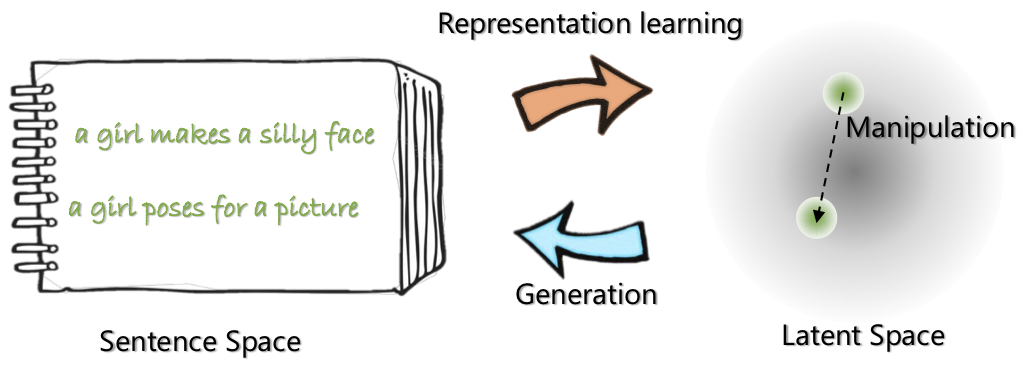 |
|---|---|
| Архитектура сети Optimus: Encoder для обучения и декодера для представления для генерации | Предложения организованы и манипулируют предварительно обученным компактным и гладким скрытым пространством |
Для получения дополнительной информации об этом проекте см. В блоге Microsoft Research.
21 мая 2020 года: выпуск demo для латентного космического манипуляции, включая интерполяцию предложения и аналогию. Проверьте website .
20 мая 2020 года: код манипуляции с скрытым пространством очищается и выпущен. См. Инструкции по адресу optimius_for_snli.md .
13 мая 2020 года. Выпущен код тонкой настройки для моделирования Langauge. См. Инструкции по адресу optimus_finetune_language_models.md
Существует четыре шага для использования этой кодовой базы для воспроизведения результатов в статье.
Вытащите Docker из Docker Hub по адресу: chunyl/pytorch-transformers:v2 . Пожалуйста, смотрите инструкцию в doc/env.md
Проект организован в следующие структуры, с визуализированными фальшивыми файлами и папками. output сохраняет контрольные точки моделей.
├── Optimus
└── code
├── examples
├── big_ae
├── modules
├── vae.py
└── ...
├── run_lm_vae_pretraining_phdist_beta.py
├── run_lm_vae_training.py
└── ...
├── pytorch_transformers
├── modeling_bert.py
├── modeling_gpt2.py
└── ...
├── scripts
├── scripts_docker
├── scripts_local
├── scripts_philly
└── data
└── datasets
├── wikipedia_json_64_filtered
└── ...
├── snli_data
└── ...
└── output
├── pretrain
├── LM
└── ...
Пожалуйста, загрузите или подготовьте данные через инструкции по адресу data/download_datasets.md .
1. Предварительное обучение по установке в Википедии
Мы предварительно обучили наши модели на Philly (Microsoft Internal Compute Cluster), код специализируется на многозвешенном вычислителе с несколькими узлами на этой платформе. Основным питоном перед тренировкой run_lm_vae_pretraining_phdist_beta.py . Вам может потребоваться скорректировать распределенные тренировочные сценарии.
2. Язлонг -моделирование
Чтобы получить справедливое сравнение с существующими моделями VAE-языка, мы рассмотрим модель с скрытым измерением 32. Предварительно обученная модель точно настроена на четырех обычно набора данных для одной эпохи. См. Подробности на doc/optimus_finetune_language_models.md
3. Генерация языка с гидом
Скрытая космическая манипуляция Для обеспечения хорошей производительности мы рассмотрим модель с скрытым измерением 768. Предварительно обученная модель точно настроена на наборе данных SNLI, где предложения показывают связанные шаблоны. Пожалуйста, смотрите подробности, пожалуйста, см. Подробности на doc/optimius_for_snli.md
4. Понимание языка с низким ресурсом
Как только сети обучаются и результаты сохранены, мы извлекли результаты ключей с помощью сценария Python. Результаты могут быть построены с использованием включенных plots/main_plots.ipynb . Запустите сервер ноутбуков ipython:
$ cd plots
$ ipython notebook
Выберите ноутбук main_plots.ipynb и выполните включенный код. Обратите внимание, что без модификации мы скопировали наши извлеченные результаты в ноутбук, и сценарий будет выходить из статьи в статье. Если вы проводите собственное обучение и хотите построить результаты, вам придется организовать свои результаты в том же формате.
Пожалуйста, бросьте мне (Chunyuan) линию, если у вас есть какие -либо вопросы.
@inproceedings{li2020_Optimus,
title={Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space},
author={Li, Chunyuan and Gao, Xiang and Li, Yuan and Li, Xiujun and Peng, Baolin and Zhang, Yizhe and Gao, Jianfeng},
booktitle={EMNLP},
year={2020}
}


