Optimus
1.0.0

该存储库包含重现EMNLP 2020纸张Optimus中显示的结果所需的源代码:通过潜在空间的预训练模型组织句子。
 |  |
|---|---|
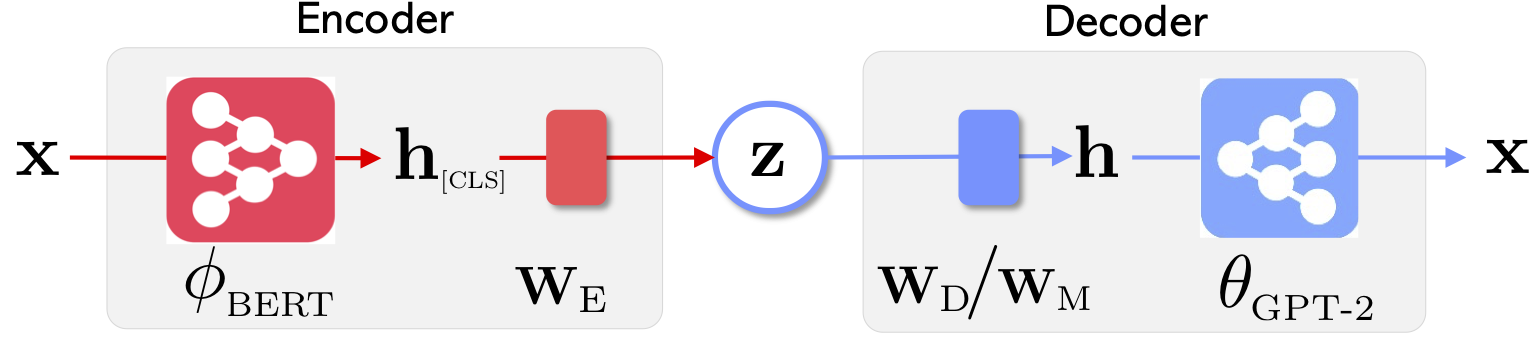
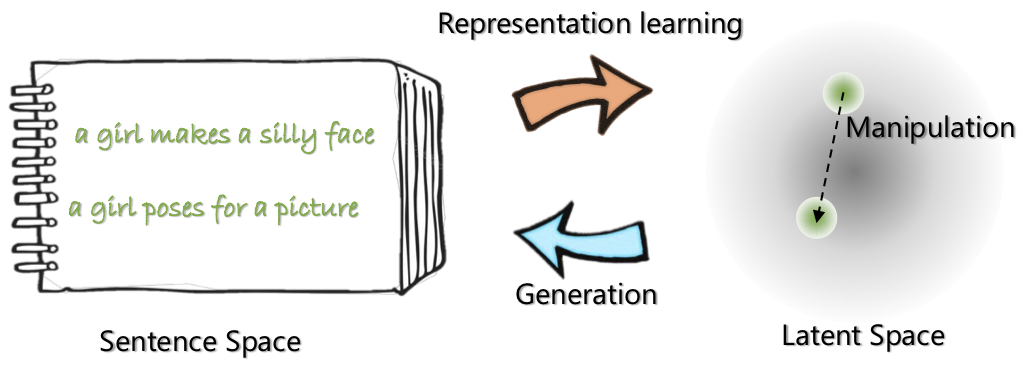
| Optimus的网络体系结构:代表学习的编码器和生成解码器 | 句子是在预先训练的紧凑和平稳的潜在空间中组织和操纵的 |
有关此项目的更多信息,请参见Microsoft研究博客文章。
2020年5月21日:释放一个用于潜在空间操纵的demo ,包括句子插值和类比。查看website 。
2020年5月20日:清洁和释放潜在的空间操纵代码。请参阅optimius_for_snli.md的说明。
2020年5月13日:发布了Langauge建模的微调代码。请参阅optimus_finetune_language_models.md上的说明
有四个步骤使用此代码库来重现论文中的结果。
从Docker Hub拉出Docker: chunyl/pytorch-transformers:v2 。请在doc/env.md上查看指令
该项目被组织到以下结构中,并且可视化了均匀的文件和文件夹。 output保存模型检查点。
├── Optimus
└── code
├── examples
├── big_ae
├── modules
├── vae.py
└── ...
├── run_lm_vae_pretraining_phdist_beta.py
├── run_lm_vae_training.py
└── ...
├── pytorch_transformers
├── modeling_bert.py
├── modeling_gpt2.py
└── ...
├── scripts
├── scripts_docker
├── scripts_local
├── scripts_philly
└── data
└── datasets
├── wikipedia_json_64_filtered
└── ...
├── snli_data
└── ...
└── output
├── pretrain
├── LM
└── ...
请通过data/download_datasets.md下载或准备数据。
1。维基百科的设置预训练
我们在Philly(Microsoft Internal Compute群集)上预先训练了模型,该代码专门用于该平台上的多节点多GPU计算。预训练的主要python是run_lm_vae_pretraining_phdist_beta.py 。您可能需要调整分布式培训脚本。
2。languange建模
为了与现有的Vae Languange模型进行公平的比较,我们考虑了一个具有潜在维度32的模型。预先训练的模型在一个时期的四个通常数据集上进行了微调。请在doc/optimus_finetune_language_models.md上查看详细信息
3。引导语言生成
为了确保良好的性能,我们考虑了一个具有潜在维度768的模型。预训练的模型在SNLI数据集中进行了微调,其中句子显示了相关的模式。请查看详细信息,请参见doc/optimius_for_snli.md的详细信息
4。低资源语言理解
一旦训练网络并保存了结果,我们就使用Python脚本提取了关键结果。可以使用随附的ipython笔记本plots/main_plots.ipynb绘制结果。启动ipython笔记本服务器:
$ cd plots
$ ipython notebook
选择main_plots.ipynb笔记本并执行随附的代码。请注意,如果没有修改,我们将提取的结果复制到了笔记本上,脚本将在论文中输出数字。如果您进行了自己的培训并希望绘制结果,则必须以相同格式组织结果。
如果您有任何疑问,请给我(Chunyuan)一行。
@inproceedings{li2020_Optimus,
title={Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space},
author={Li, Chunyuan and Gao, Xiang and Li, Yuan and Li, Xiujun and Peng, Baolin and Zhang, Yizhe and Gao, Jianfeng},
booktitle={EMNLP},
year={2020}
}


