Optimus
1.0.0

このリポジトリには、EMNLP 2020 Paper Optimusに示されている結果を再現するために必要なソースコードが含まれています。
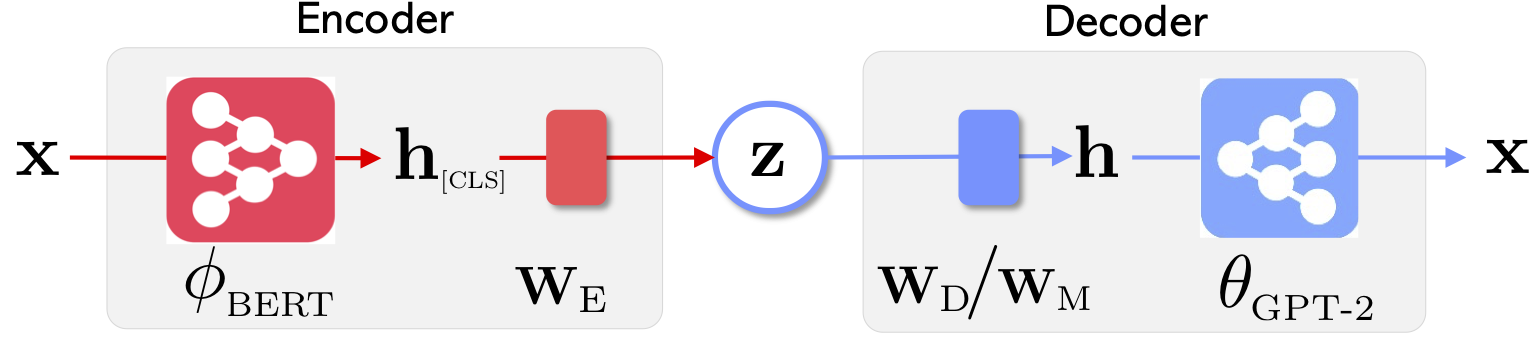 | 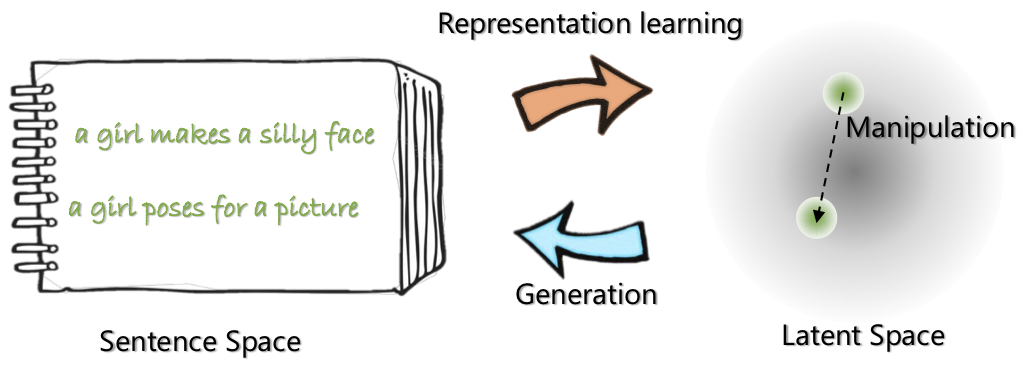 |
|---|---|
| Optimusのネットワークアーキテクチャ:表現のためのエンコーダー生成用のデコーダー | 文章は、事前に訓練されたコンパクトで滑らかな潜在スペースで編成および操作されます |
このプロジェクトの詳細については、Microsoft Researchブログ投稿を参照してください。
2020年5月21日:文の補間や類推を含む潜在的な宇宙操作のdemoをリリースします。 websiteをご覧ください。
2020年5月20日:潜在的な宇宙操作コードがクリーニングされ、リリースされます。 optimius_for_snli.mdの指示を参照してください。
2020年5月13日:ランゲージモデリング用の微調整コードがリリースされます。 optimus_finetune_language_models.mdの手順を参照してください
このコードベースを使用して、論文の結果を再現するための4つの手順があります。
Docker HubからDockerを引く: chunyl/pytorch-transformers:v2 。 doc/env.mdの指示をご覧ください
このプロジェクトは、次の構造に整理され、視覚化されています。 outputモデルチェックポイントを保存します。
├── Optimus
└── code
├── examples
├── big_ae
├── modules
├── vae.py
└── ...
├── run_lm_vae_pretraining_phdist_beta.py
├── run_lm_vae_training.py
└── ...
├── pytorch_transformers
├── modeling_bert.py
├── modeling_gpt2.py
└── ...
├── scripts
├── scripts_docker
├── scripts_local
├── scripts_philly
└── data
└── datasets
├── wikipedia_json_64_filtered
└── ...
├── snli_data
└── ...
└── output
├── pretrain
├── LM
└── ...
data/download_datasets.mdの手順に従ってデータをダウンロードまたは準備してください。
1。ウィキペディアの整理に関する事前トレーニング
Philly(Microsoft Internal Compute Cluster)でモデルを事前に訓練しました。このコードは、このプラットフォーム上のマルチノードマルチGPUコンピューティングに特化しています。トレーニング前のメインPythonはrun_lm_vae_pretraining_phdist_beta.pyです。分散トレーニングスクリプトを調整する必要がある場合があります。
2。角質モデリング
既存のVAE角質モデルと公正な比較を行うために、潜在寸法32のモデルを検討します。事前に訓練されたモデルは、1つのエポックの4つの一般的なデータセットで微調整されています。 doc/optimus_finetune_language_models.mdの詳細をご覧ください
3。ガイド付き言語生成
潜在的な空間操作良好なパフォーマンスを確保するために、潜在寸法768のモデルを検討します。768。事前に訓練されたモデルは、文が関連するパターンを示すSNLIデータセットで微調整されています。詳細をご覧くださいdoc/optimius_for_snli.mdの詳細をご覧ください
4。低リソースの言語理解
ネットワークがトレーニングされ、結果が保存されると、Pythonスクリプトを使用して重要な結果を抽出しました。結果は、含まれているIPythonノートブックplots/main_plots.ipynbを使用してプロットできます。 IPythonノートブックサーバーを開始します。
$ cd plots
$ ipython notebook
main_plots.ipynbノートブックを選択し、付属のコードを実行します。変更がなければ、抽出された結果をノートブックにコピーし、スクリプトが論文の数値を出力することに注意してください。独自のトレーニングを実行し、結果をプロットしたい場合は、代わりに同じ形式で結果を整理する必要があります。
質問がある場合は、私(Chunyuan)を1行に落としてください。
@inproceedings{li2020_Optimus,
title={Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space},
author={Li, Chunyuan and Gao, Xiang and Li, Yuan and Li, Xiujun and Peng, Baolin and Zhang, Yizhe and Gao, Jianfeng},
booktitle={EMNLP},
year={2020}
}


