Optimus
1.0.0

يحتوي هذا المستودع على رمز المصدر اللازم لإعادة إنتاج النتائج المقدمة في ورقة EMNLP 2020 Optimus: تنظيم الجمل عبر النمذجة التي تم تدريبها مسبقًا لمساحة كامنة.
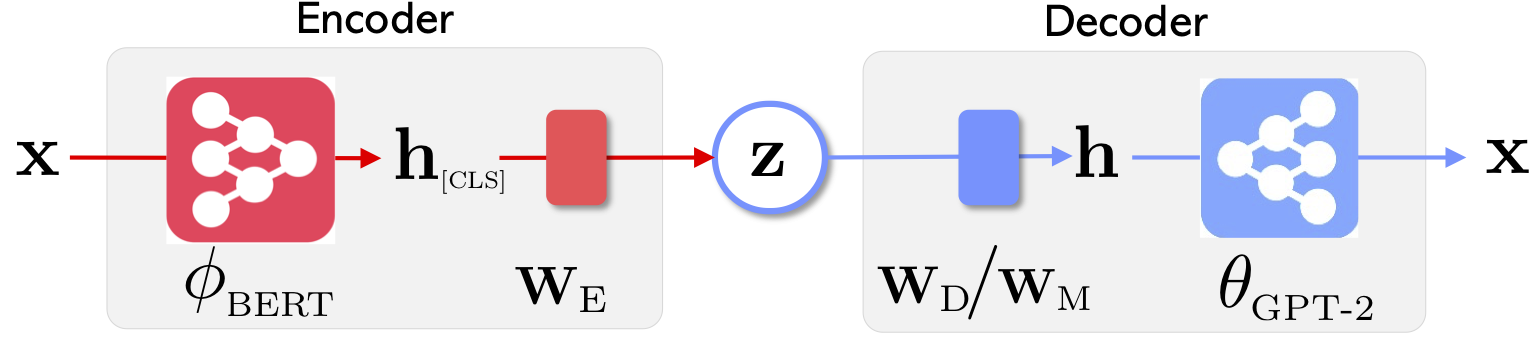 | 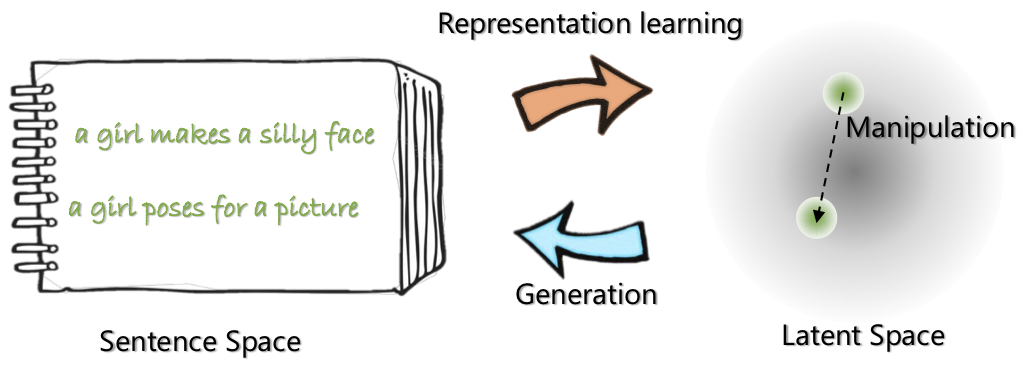 |
|---|---|
| بنية الشبكة لـ Optimus: Encoder لتعلم التمثيل وفك الترميز للجيل | يتم تنظيم الجمل ومعالجتها في مساحة كامنة مضغوطة وسلسة مسبقًا |
لمعرفة المزيد عن هذا المشروع ، راجع منشور مدونة Microsoft Research.
21 مايو ، 2020: إطلاق demo للتلاعب بالفضاء الكامن ، بما في ذلك الاستيفاء من الجملة والتشبيه. تحقق من website .
20 مايو 2020: يتم تنظيف رمز التلاعب بالفضاء الكامن وإطلاقه. انظر التعليمات في optimius_for_snli.md .
13 مايو 2020: تم إصدار رمز الضبط لنمذجة Langauge. راجع التعليمات في optimus_finetune_language_models.md
هناك أربع خطوات لاستخدام قاعدة الشفرة هذه لإعادة إنتاج النتائج في الورقة.
سحب Docker من Docker Hub على: chunyl/pytorch-transformers:v2 . يرجى الاطلاع على التعليمات في doc/env.md
يتم تنظيم المشروع في الهياكل التالية ، مع تصور الملفات والمجلدات التالية. output يحفظ نقاط التفتيش النماذج.
├── Optimus
└── code
├── examples
├── big_ae
├── modules
├── vae.py
└── ...
├── run_lm_vae_pretraining_phdist_beta.py
├── run_lm_vae_training.py
└── ...
├── pytorch_transformers
├── modeling_bert.py
├── modeling_gpt2.py
└── ...
├── scripts
├── scripts_docker
├── scripts_local
├── scripts_philly
└── data
└── datasets
├── wikipedia_json_64_filtered
└── ...
├── snli_data
└── ...
└── output
├── pretrain
├── LM
└── ...
يرجى تنزيل البيانات أو إعدادها عبر الإرشادات الموجودة في data/download_datasets.md .
1. التدريب المسبق على المستويات في ويكيبيديا
لقد قمنا بتدريب نماذجنا مسبقًا على Philly (مجموعة حساب Microsoft الداخلية) ، والرمز متخصص لحساب متعدد GPU متعدد العقدة على هذا النظام الأساسي. بيثون الرئيسي قبل التدريب هو run_lm_vae_pretraining_phdist_beta.py . قد تحتاج إلى ضبط البرامج النصية التدريبية الموزعة.
2. النمذجة اللغوية
للحصول على مقارنة عادلة مع نماذج VAE Languange الحالية ، فإننا نعتبر نموذجًا له البعد الكامن 32. تم ضبط النموذج الذي تم تدريبه مسبقًا على أربع مجموعات بيانات شائعة لعصر واحد. يرجى الاطلاع على التفاصيل في doc/optimus_finetune_language_models.md
3. توليد اللغة الموجهة
معالجة الفضاء الكامنة لضمان أداء جيد ، نعتبر نموذجًا له البعد الكامن 768. تم ضبط النموذج الذي تم تدريبه مسبقًا على مجموعة بيانات SNLI ، حيث تُظهر الجمل أنماطًا ذات صلة. يرجى الاطلاع على التفاصيل في يرجى الاطلاع على التفاصيل في doc/optimius_for_snli.md
4. فهم اللغة منخفضة الموارد
بمجرد تدريب الشبكات وحفظ النتائج ، استخرجنا نتائج رئيسية باستخدام البرنامج النصي Python. يمكن رسم النتائج باستخدام plots/main_plots.ipynb . ابدأ خادم دفتر Ipython:
$ cd plots
$ ipython notebook
حدد دفتر الملاحظات main_plots.ipynb وقم بتنفيذ الكود المضمّن. لاحظ أنه بدون تعديل ، قمنا بنسخ نتائجنا المستخرجة إلى دفتر الملاحظات ، وسيقوم البرنامج النصي بإخراج الأرقام في الورقة. إذا قمت بتشغيل التدريب الخاص بك وترغب في رسم النتائج ، فسيتعين عليك تنظيم نتائجك بنفس التنسيق بدلاً من ذلك.
يرجى إسقاطني (Chunyuan) خط إذا كان لديك أي أسئلة.
@inproceedings{li2020_Optimus,
title={Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space},
author={Li, Chunyuan and Gao, Xiang and Li, Yuan and Li, Xiujun and Peng, Baolin and Zhang, Yizhe and Gao, Jianfeng},
booktitle={EMNLP},
year={2020}
}


