Optimus
1.0.0

Ce référentiel contient le code source nécessaire pour reproduire les résultats présentés dans le papier EMNLP 2020 Optimus: Organisation des phrases via la modélisation pré-formée d'un espace latent.
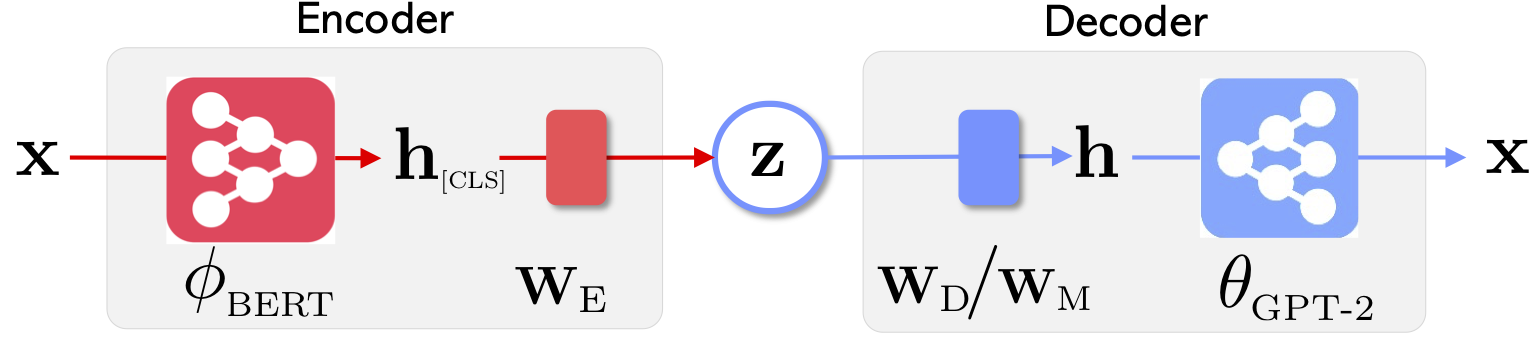 | 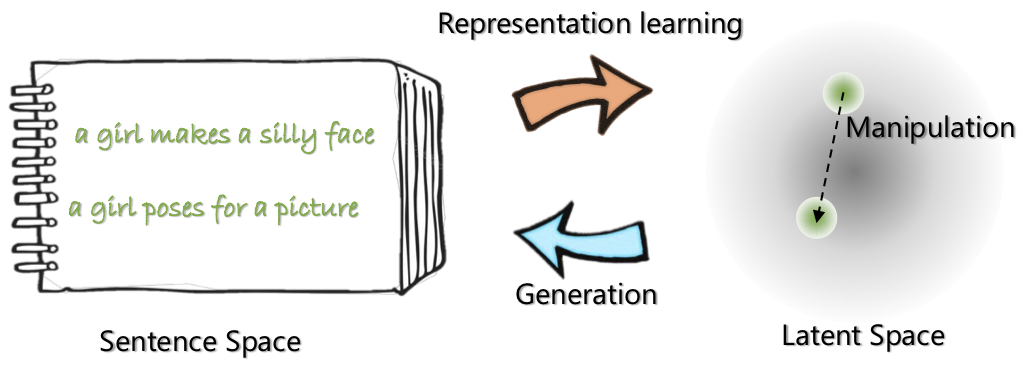 |
|---|---|
| L'architecture réseau d'Optimus: Encodeur pour l'apprentissage de la représentation et le décodeur pour la génération | Les phrases sont organisées et manipulées dans un espace de latente compact et lisse pré-formé |
Pour en savoir plus sur ce projet, consultez le blog Microsoft Research.
21 mai 2020: Libérer une demo pour la manipulation de l'espace latent, y compris l'interpolation des phrases et l'analogie. Consultez le website .
20 mai 2020: Le code de manipulation de l'espace latente est nettoyé et libéré. Voir les instructions à optimius_for_snli.md .
13 mai 2020: Le code de réglage fin pour la modélisation de Langauge est publié. Voir les instructions sur optimus_finetune_language_models.md
Il y a quatre étapes pour utiliser cette base de code pour reproduire les résultats du papier.
Tirez Docker de Docker Hub à: chunyl/pytorch-transformers:v2 . Veuillez consulter l'instruction à doc/env.md
Le projet est organisé dans les structures suivantes, avec des fichiers et dossiers Endential. output enregistre les points de contrôle des modèles.
├── Optimus
└── code
├── examples
├── big_ae
├── modules
├── vae.py
└── ...
├── run_lm_vae_pretraining_phdist_beta.py
├── run_lm_vae_training.py
└── ...
├── pytorch_transformers
├── modeling_bert.py
├── modeling_gpt2.py
└── ...
├── scripts
├── scripts_docker
├── scripts_local
├── scripts_philly
└── data
└── datasets
├── wikipedia_json_64_filtered
└── ...
├── snli_data
└── ...
└── output
├── pretrain
├── LM
└── ...
Veuillez télécharger ou préparer les données via le suivi des instructions sur data/download_datasets.md .
1. Pré-formation sur les décors à Wikipedia
Nous avons préparé nos modèles sur Philly (un cluster de calcul interne Microsoft), le code est spécialisé pour le calcul multi-nœuds multi-GPU sur cette plate-forme. Le python principal pré-formation est run_lm_vae_pretraining_phdist_beta.py . Vous devrez peut-être ajuster les scripts de formation distribués.
2. Modélisation Languange
Pour avoir une comparaison équitable avec les modèles VAE Languange existants, nous considérons un modèle avec la dimension latente 32. Le modèle pré-formé est affiné sur quatre ensembles de données généralement pour une époque. Veuillez consulter les détails sur doc/optimus_finetune_language_models.md
3. Génération de langue guidée
Manipulation de l'espace latente Pour assurer de bonnes performances, nous considérons un modèle avec une dimension latente 768. Le modèle pré-formé est affiné sur l'ensemble de données SNLI, où les phrases présentent des modèles connexes. Veuillez consulter les détails à consulter les détails de doc/optimius_for_snli.md
4. Compréhension du langage à faible ressource
Une fois les réseaux formés et les résultats enregistrés, nous avons extrait les résultats clés à l'aide du script Python. Les résultats peuvent être tracés à l'aide du cahier IPython plots/main_plots.ipynb . Démarrez le serveur d'ordinateurs portables Ipython:
$ cd plots
$ ipython notebook
Sélectionnez le cahier main_plots.ipynb et exécutez le code inclus. Notez que sans modification, nous avons copié nos résultats extraits dans le cahier et le script sortira des chiffres dans l'article. Si vous avez suivi votre propre formation et que vous souhaitez tracer des résultats, vous devrez plutôt organiser vos résultats dans le même format.
S'il vous plaît, envoyez-moi (Chunyuan) une ligne si vous avez des questions.
@inproceedings{li2020_Optimus,
title={Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space},
author={Li, Chunyuan and Gao, Xiang and Li, Yuan and Li, Xiujun and Peng, Baolin and Zhang, Yizhe and Gao, Jianfeng},
booktitle={EMNLP},
year={2020}
}


