Optimus
1.0.0

Este repositório contém código-fonte necessário para reproduzir os resultados apresentados no artigo EMNLP 2020 Optimus: Organizando frases por meio de modelagem pré-treinada de um espaço latente.
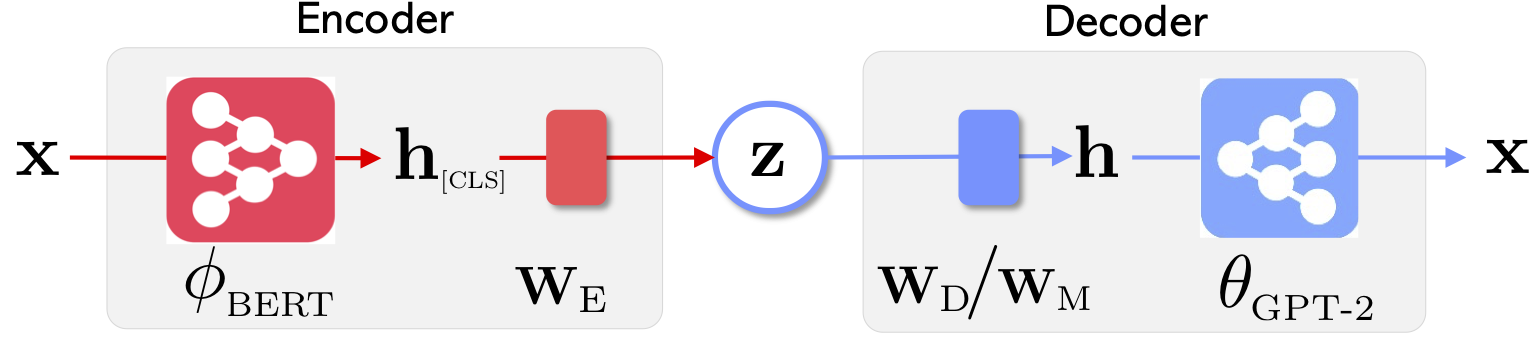 | 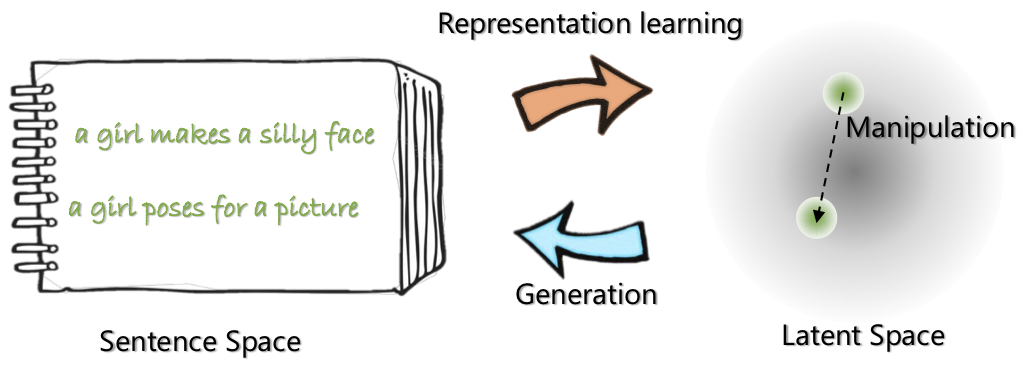 |
|---|---|
| A Arquitetura de Rede de Optimus: Codificador para Aprendizagem e Decodificador de Representação para Geração | As frases são organizadas e manipuladas em um espaço latente compacto e suave pré-treinado |
Para saber mais sobre este projeto, consulte a publicação do Microsoft Research Blog.
21 de maio de 2020: liberando uma demo para manipulação espacial latente, incluindo interpolação e analogia da sentença. Confira o website .
20 de maio de 2020: O código de manipulação do espaço latente é limpo e liberado. Consulte as instruções em optimius_for_snli.md .
13 de maio de 2020: O código de ajuste fino para modelagem de Langauge é lançado. Veja as instruções em optimus_finetune_language_models.md
Existem quatro etapas para usar esta base de código para reproduzir os resultados no artigo.
Puxe o Docker do Docker Hub em: chunyl/pytorch-transformers:v2 . Por favor, veja a instrução em doc/env.md
O projeto está organizado nas seguintes estruturas, com arquivos e pastas básicas visualizadas. output salva os pontos de verificação dos modelos.
├── Optimus
└── code
├── examples
├── big_ae
├── modules
├── vae.py
└── ...
├── run_lm_vae_pretraining_phdist_beta.py
├── run_lm_vae_training.py
└── ...
├── pytorch_transformers
├── modeling_bert.py
├── modeling_gpt2.py
└── ...
├── scripts
├── scripts_docker
├── scripts_local
├── scripts_philly
└── data
└── datasets
├── wikipedia_json_64_filtered
└── ...
├── snli_data
└── ...
└── output
├── pretrain
├── LM
└── ...
Faça o download ou a preparação dos dados seguindo as instruções em data/download_datasets.md .
1. Pré-treinamento em setências na Wikipedia
Pré-treinamos nossos modelos no Philly (um cluster de computação interna da Microsoft), o código é especializado em computação multi-gpu de vários nós nessa plataforma. O Python principal de pré-treinamento é run_lm_vae_pretraining_phdist_beta.py . Pode ser necessário ajustar os scripts de treinamento distribuídos.
2. Modelagem de Languange
Para ter uma comparação justa com os modelos existentes de VAE Languange, consideramos um modelo com dimensão latente 32. O modelo pré-treinado é ajustado em quatro conjuntos de dados comumente para uma época. Consulte os detalhes em doc/optimus_finetune_language_models.md
3. Geração de linguagem guiada
Manipulação de espaço latente Para garantir um bom desempenho, consideramos um modelo com dimensão latente 768. O modelo pré-treinado é ajustado no conjunto de dados SNLI, onde frases mostram padrões relacionados. Consulte os detalhes em Por favor, veja os detalhes em doc/optimius_for_snli.md
4. Entendimento de linguagem de baixo resistência
Depois que as redes são treinadas e os resultados são salvos, extraímos os principais resultados usando o script Python. Os resultados podem ser plotados usando os plots/main_plots.ipynb . Inicie o servidor IPython Notebook:
$ cd plots
$ ipython notebook
Selecione o notebook main_plots.ipynb e execute o código incluído. Observe que, sem modificação, copiamos nossos resultados extraídos para o notebook e o script produzirá figuras no papel. Se você executou seu próprio treinamento e deseja plotar os resultados, precisará organizar seus resultados no mesmo formato.
Por favor, envie -me (Chunyuan) uma linha se tiver alguma dúvida.
@inproceedings{li2020_Optimus,
title={Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space},
author={Li, Chunyuan and Gao, Xiang and Li, Yuan and Li, Xiujun and Peng, Baolin and Zhang, Yizhe and Gao, Jianfeng},
booktitle={EMNLP},
year={2020}
}


