Optimus
1.0.0

ที่เก็บนี้มีซอร์สโค้ดที่จำเป็นในการทำซ้ำผลลัพธ์ที่นำเสนอใน Paper Optimus กระดาษ EMNLP 2020: การจัดประโยคผ่านการสร้างแบบจำลองที่ผ่านการฝึกอบรมมาก่อนของพื้นที่แฝง
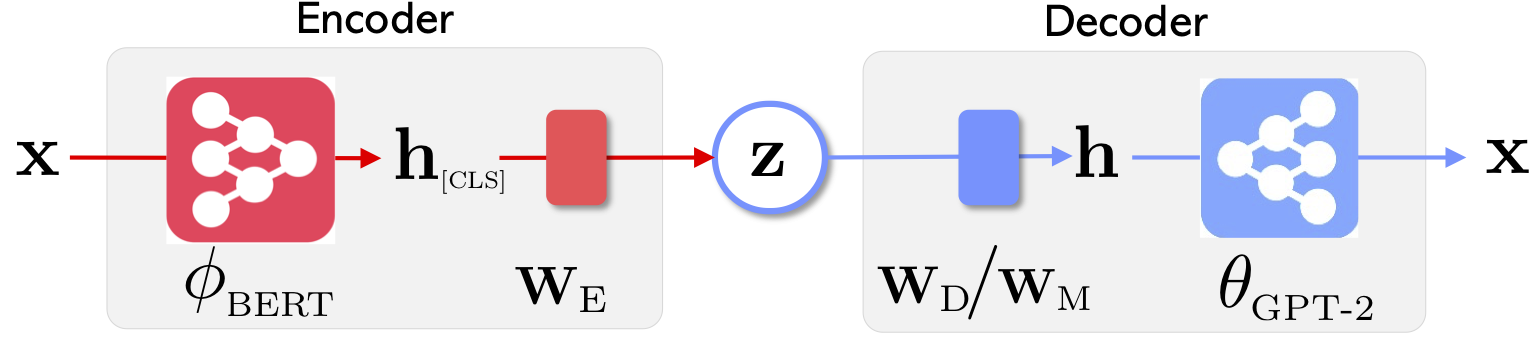 | 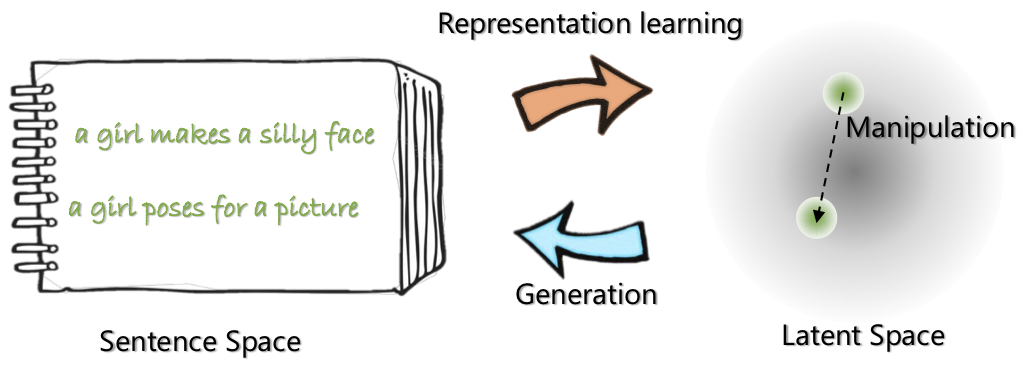 |
|---|---|
| สถาปัตยกรรมเครือข่ายของ Optimus: encoder สำหรับการเรียนรู้การเป็นตัวแทนและตัวถอดรหัสสำหรับรุ่น | มีการจัดระเบียบประโยคและจัดการในพื้นที่ที่มีขนาดกะทัดรัดและได้รับการฝึกฝนมาก่อนและราบรื่น |
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับโครงการนี้ดูโพสต์บล็อกการวิจัยของ Microsoft
21 พฤษภาคม 2563: ปล่อย demo สำหรับการจัดการพื้นที่แฝงรวมถึงการแก้ไขประโยคและการเปรียบเทียบ ตรวจสอบ website
20 พฤษภาคม 2020: รหัสการจัดการพื้นที่แฝงได้รับการทำความสะอาดและปล่อยออกมา ดูคำแนะนำที่ optimius_for_snli.md
13 พฤษภาคม 2020: รหัสการปรับแต่งสำหรับการสร้างแบบจำลอง Langauge ได้รับการปล่อยตัว ดูคำแนะนำที่ optimus_finetune_language_models.md
มีสี่ขั้นตอนในการใช้ codebase นี้เพื่อทำซ้ำผลลัพธ์ในกระดาษ
ดึงนักเทียบท่าจาก Docker Hub ที่: chunyl/pytorch-transformers:v2 โปรดดูคำแนะนำที่ doc/env.md
โครงการถูกจัดระเบียบลงในโครงสร้างต่อไปนี้โดยมีไฟล์และโฟลเดอร์ที่มองเห็นได้ output บันทึกจุดตรวจสอบรุ่น
├── Optimus
└── code
├── examples
├── big_ae
├── modules
├── vae.py
└── ...
├── run_lm_vae_pretraining_phdist_beta.py
├── run_lm_vae_training.py
└── ...
├── pytorch_transformers
├── modeling_bert.py
├── modeling_gpt2.py
└── ...
├── scripts
├── scripts_docker
├── scripts_local
├── scripts_philly
└── data
└── datasets
├── wikipedia_json_64_filtered
└── ...
├── snli_data
└── ...
└── output
├── pretrain
├── LM
└── ...
โปรดดาวน์โหลดหรือเตรียมข้อมูลผ่านคำแนะนำที่ data/download_datasets.md
1. การฝึกอบรมล่วงหน้าเกี่ยวกับ setences ใน Wikipedia
เราได้รับการฝึกอบรมแบบจำลองของเราล่วงหน้าเกี่ยวกับ Philly (Microsoft Internal Compute Cluster) รหัสนี้มีความเชี่ยวชาญสำหรับการคำนวณแบบหลายโหนดหลายโหนดบนแพลตฟอร์มนี้ งูหลามหลักก่อนการฝึกคือ run_lm_vae_pretraining_phdist_beta.py คุณอาจต้องปรับสคริปต์การฝึกอบรมแบบกระจาย
2. การสร้างแบบจำลอง Langange
เพื่อให้มีการเปรียบเทียบที่เป็นธรรมกับโมเดล VAE ที่มีอยู่เดิมเราพิจารณาโมเดลที่มีมิติแฝง 32 โมเดลที่ผ่านการฝึกอบรมมาก่อนได้รับการปรับแต่งอย่างละเอียดในชุดข้อมูลทั่วไปสี่ชุดสำหรับยุคหนึ่ง โปรดดูรายละเอียดที่ doc/optimus_finetune_language_models.md
3. การสร้างภาษาไกด์
การจัดการพื้นที่แฝง เพื่อให้แน่ใจว่าประสิทธิภาพที่ดีเราพิจารณาแบบจำลองที่มีมิติแฝง 768 โมเดลที่ผ่านการฝึกอบรมมาก่อนได้รับการปรับแต่งในชุดข้อมูล SNLI ซึ่งประโยคแสดงรูปแบบที่เกี่ยวข้อง โปรดดูรายละเอียดที่โปรดดูรายละเอียดที่ doc/optimius_for_snli.md
4. ความเข้าใจภาษาที่ทรัพยากรต่ำ
เมื่อเครือข่ายได้รับการฝึกอบรมและบันทึกผลลัพธ์เราจะแยกผลลัพธ์ที่สำคัญโดยใช้สคริปต์ Python ผลลัพธ์สามารถพล็อตได้โดยใช้ plots/main_plots.ipynb เริ่มเซิร์ฟเวอร์ Ipython Notebook:
$ cd plots
$ ipython notebook
เลือกสมุดบันทึก main_plots.ipynb และเรียกใช้รหัสที่รวมอยู่ โปรดทราบว่าหากไม่มีการดัดแปลงเราได้คัดลอกผลลัพธ์ที่แยกออกมาลงในโน้ตบุ๊กและตัวเลขสคริปต์จะส่งออกตัวเลขในกระดาษ หากคุณได้รับการฝึกอบรมของคุณเองและต้องการพล็อตผลลัพธ์คุณจะต้องจัดระเบียบผลลัพธ์ในรูปแบบเดียวกันแทน
โปรดวางฉัน (Chunyuan) บรรทัดถ้าคุณมีคำถามใด ๆ
@inproceedings{li2020_Optimus,
title={Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space},
author={Li, Chunyuan and Gao, Xiang and Li, Yuan and Li, Xiujun and Peng, Baolin and Zhang, Yizhe and Gao, Jianfeng},
booktitle={EMNLP},
year={2020}
}


