Optimus
1.0.0

Dieses Repository enthält den Quellcode, der zur Reproduktion der im EMNLP 2020 Papier Optimus dargestellten Ergebnisse erforderlich ist: Organisation von Sätzen durch vorgebliebenes Modellieren eines latenten Raums.
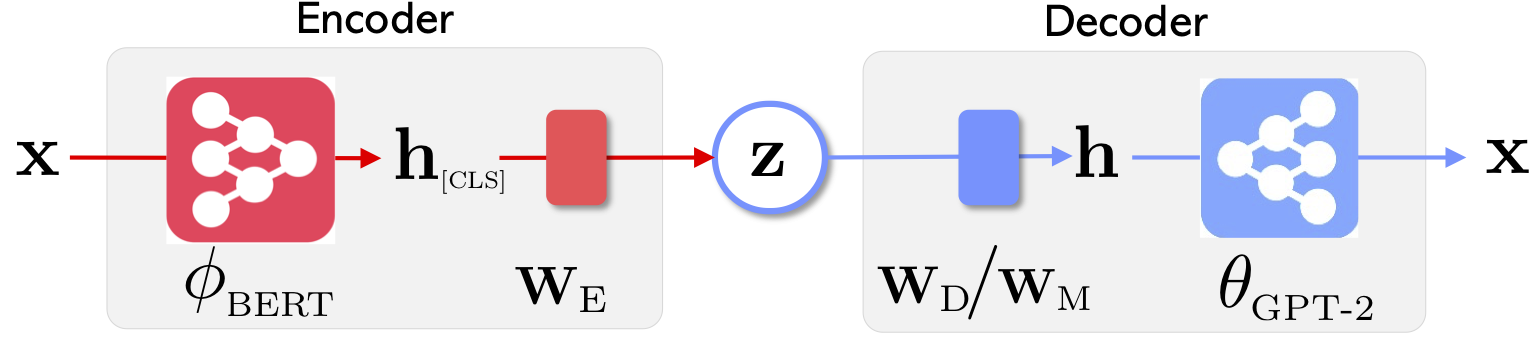 | 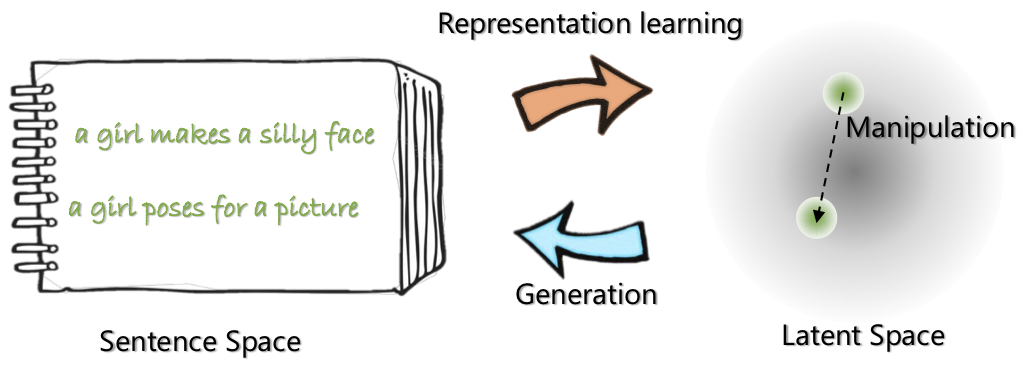 |
|---|---|
| Die Netzwerkarchitektur von Optimus: Encoder für Repräsentationslernen und Decoder für die Generation | Die Sätze werden in einem vorgebildeten kompakten und glatten latenten Raum organisiert und manipuliert |
Weitere Informationen zu diesem Projekt finden Sie im Microsoft Research Blog -Beitrag.
21. Mai 2020: Veröffentlichung einer demo zur latenten Raummanipulation, einschließlich Satzinterpolation und Analogie. Schauen Sie sich die website an.
20. Mai 2020: Der latente Raummanipulationscode wird gereinigt und veröffentlicht. Siehe Anweisungen unter optimius_for_snli.md .
13. Mai 2020: Der Feinabstimmungscode für die Modellierung von Langauge wird veröffentlicht. Siehe Anweisungen unter optimus_finetune_language_models.md
Es gibt vier Schritte, um diese Codebasis zu verwenden, um die Ergebnisse im Papier zu reproduzieren.
Ziehen Sie Docker von Docker Hub bei: chunyl/pytorch-transformers:v2 . Bitte beachten Sie die Anweisung unter doc/env.md
Das Projekt ist in die folgenden Strukturen organisiert, wobei die unteren Dateien und Ordner sichtbar machen. output speichert die Modelle Checkpoints.
├── Optimus
└── code
├── examples
├── big_ae
├── modules
├── vae.py
└── ...
├── run_lm_vae_pretraining_phdist_beta.py
├── run_lm_vae_training.py
└── ...
├── pytorch_transformers
├── modeling_bert.py
├── modeling_gpt2.py
└── ...
├── scripts
├── scripts_docker
├── scripts_local
├── scripts_philly
└── data
└── datasets
├── wikipedia_json_64_filtered
└── ...
├── snli_data
└── ...
└── output
├── pretrain
├── LM
└── ...
Bitte laden Sie die Daten über die Anweisungen unter data/download_datasets.md herunter oder erstellen Sie die Daten vor.
1. Voraberziehung bei Setings in Wikipedia
Wir haben unsere Modelle auf Philly (einem Microsoft Internal Compute Cluster) vorgebracht. Der Code ist auf dieser Plattform auf Multi-Node-Multi-GPU-Computer spezialisiert. Das Hauptpython vor dem Training ist run_lm_vae_pretraining_phdist_beta.py . Möglicherweise müssen Sie die verteilten Trainingsskripte anpassen.
2. Modellierung der Sprache
Um einen fairen Vergleich mit vorhandenen VAE-Sprachenmodellen zu haben, betrachten wir ein Modell mit latenter Dimension 32. Das vorgebreitete Modell ist für eine Epoche auf vier üblichen Datensätzen fein abgestimmt. Bitte beachten Sie die Details unter doc/optimus_finetune_language_models.md
3.. Guided Sprachgenerierung
Latent Space Manipulation Um eine gute Leistung zu gewährleisten, betrachten wir ein Modell mit latenter Dimension 768. Das vorgebildete Modell ist in SNLI-Datensatz fein abgestimmt, wo Sätze verwandte Muster zeigen. Bitte beachten Sie die Details unter den Details unter doc/optimius_for_snli.md
4. Verständnis mit niedrigem Ressourcensprachen
Sobald die Netzwerke trainiert und die Ergebnisse gespeichert sind, haben wir mithilfe von Python -Skript die wichtigsten Ergebnisse extrahiert. Die Ergebnisse können mit den mitgelieferten Ipython -Notebooks plots/main_plots.ipynb aufgetragen werden. Starten Sie den Ipython Notebook -Server:
$ cd plots
$ ipython notebook
Wählen Sie das Notizbuch main_plots.ipynb und führen Sie den mitgelieferten Code aus. Beachten Sie, dass wir ohne Änderung unsere extrahierten Ergebnisse in das Notebook kopiert haben und das Skript die Zahlen im Papier ausgibt. Wenn Sie Ihr eigenes Training ausgeführt haben und Ergebnisse zeichnen möchten, müssen Sie Ihre Ergebnisse stattdessen in demselben Format organisieren.
Bitte geben Sie mich (Chunyuan) eine Zeile, wenn Sie Fragen haben.
@inproceedings{li2020_Optimus,
title={Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space},
author={Li, Chunyuan and Gao, Xiang and Li, Yuan and Li, Xiujun and Peng, Baolin and Zhang, Yizhe and Gao, Jianfeng},
booktitle={EMNLP},
year={2020}
}


