gc4lm
1.0.0
該存儲庫為德國人提供了一個巨大的(且有偏見的)語言模型,該模型在最近發布的“德國巨大,乾淨的普通爬行語料庫”(GC4)中,總數據集大小約為844GB。
免責聲明:此存儲庫中提出的和訓練有素的語言模型僅用於研究目的。 GC4語料庫(用於培訓)包含互聯網上的爬行文本。因此,可以將語言模型視為高度偏見,從而產生了一個模型,該模型編碼沿性別,種族,種族和殘疾狀況的刻板印象關聯。在使用並使用已發布的檢查點之前,強烈建議閱讀:
關於隨機鸚鵡的危險:語言模型會太大嗎?
來自Emily M. Bender,Timnit Gebru,Angelina McMillan-Major和Shmargaret Shmitchell。
發布的檢查站的目的是促進針對德語的大型預訓練的語言模型的研究,尤其是確定偏見和如何預防它們,因為大多數研究目前僅針對英語進行。
請使用新的GitHub討論功能來討論或提出進一步的研究問題。可以隨意在Twitter上使用#gc4lm 。
下載GC4的完整HEAD和MIDDLE部分後,我們提取下載的檔案館,並通過GC4團隊提供的GIST提取原始內容(包括語言得分過濾)。
在另一個預處理腳本中,我們對整個預訓練語料庫進行句子分解。最快的解決方案之一是使用NLTK(帶有德國模型),而不是使用EG Spacy。
提取後,語言得分過濾和句子分割後,結果數據集大小為844GB 。
句子分解後,下一步是創建一個兼容的兼容詞彙,這在下一節中進行了描述。
詞彙一代的工作流程主要靈感來自Juditács的博客文章,介紹了“探索Bert的詞彙”和最近發行的論文“您的令牌器有多好?”來自Phillip Rust,Jonas Pfeiffer,IvanVulić,Sebastian Ruder和Iryna Gurevych。
我們主要專注於計算流行下游任務的培訓和開發數據的子詞生育能力,例如命名實體識別(NER),POS標籤和文本分類。為此,我們使用以下方式的令牌化培訓和開發數據:
併計算各種德語模型的未知(子)單詞的子詞生育能力和部分:
| 模型名稱 | 子詞生育能力 | UNK部分 |
|---|---|---|
bert-base-german-cased | 1.4433 | 0.0083% |
bert-base-german-dbmdz-cased | 1.4070 | 0.0050% |
| 這項工作(32K) | 1.3955 | 0.0011% |
| 這項工作(64k) | 1.3050 | 0.0011% |
然後,我們決定根據GC4的HEAD和MIDDLE部分創建一個新的詞彙。我們選擇以下檔案以生成新的詞彙:
0000_2015-48 (來自HEAD ,2.5GB)0004_2016-44 (來自HEAD ,2.1GB)和0006_2016-44 (來自MIDDLE ,861MB)0003_2017-30 (來自HEAD ,2.4GB)和0007_2017-51 ( MIDDLE ,1.1GB)0007_2018-30 (來自HEAD ,409MB)和0007_2018-51 ( MIDDLE ,4.9GB)0006_2019-09 (來自HEAD ,1.8GB)和0008_2019-30 (來自MIDDLE ,2.2GB)0003_2020-10 (來自HEAD ,4.5GB)和0007_2020-10 ( MIDDLE ,4.0GB)這會導致用於詞彙生成的27GB大小的語料庫。
我們決定使用令人敬畏的擁抱臉龐圖書館來生成32K和64K大小的詞彙。
GC4語料庫上的第一個大型預訓練的語言模型是基於電氣的模型: GC4Electra 。它的參數與V3-32 TPU上的土耳其Electra模型相同的參數進行了訓練。它使用64k詞彙(當前正在訓練32K型號)。
注意:我們不發布一個模型。取而代之的是,我們發布了所有模型檢查點(具有100K階梯),以獲取更多的研究可能性。
可以從擁抱面模型中心可用以下檢查站。感謝擁抱的臉提供這個驚人的基礎設施! !
我們還在集線器上的每個型號中包括原始的張量集檢查點。
| 模型集線器名稱 | 檢查點(步驟) |
|---|---|
electra-base-gc4-64k-0-cased-discriminator -Electra electra-base-gc4-64k-0-cased-generator | 0(初始) |
electra-base-gc4-64k-100000-cased-discriminator -Electra electra-base-gc4-64k-100000-cased-generator | 100,000步 |
electra-base-gc4-64k-200000-cased-discriminator -Electra electra-base-gc4-64k-200000-cased-generator | 200,000步 |
electra-base-gc4-64k-300000-cased-discriminator -Electra electra-base-gc4-64k-300000-cased-generator | 300,000步 |
electra-base-gc4-64k-400000-cased-discriminator -Electra electra-base-gc4-64k-400000-cased-generator | 40萬步 |
electra-base-gc4-64k-500000-cased-discriminator -Electra electra-base-gc4-64k-500000-cased-generator | 500,000步 |
electra-base-gc4-64k-600000-cased-discriminator -Electra electra-base-gc4-64k-600000-cased-generator | 600,000步 |
electra-base-gc4-64k-700000-cased-discriminator electra-base-gc4-64k-700000-cased-generator | 700,000步 |
electra electra-base-gc4-64k-800000-cased-discriminator -Electra electra-base-gc4-64k-800000-cased-generator | 800,000步 |
electra-base-gc4-64k-900000-cased-discriminator - electra-base-gc4-64k-900000-cased-generator | 900,000步 |
electra-base-gc4-64k-1000000-cased-discriminator electra-base-gc4-64k-1000000-cased-generator | 1M步驟 |
注意:您應該將發電機模型用於MLM任務,例如蒙版令牌預測。鑑別模型應用於在下游任務,諸如NER,POS標記,文本類別等的下游任務上進行微調。
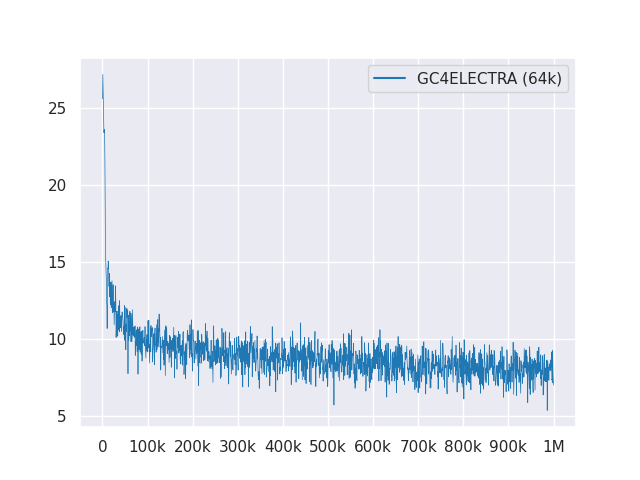
以下圖顯示了超過1M步驟的損耗曲線:
所有型號均在麻省理工學院下獲得許可。
請使用新的GitHub討論進行反饋,或者只是填寫PR以進行建議/更正。
感謝Philip May,PhilippReißel和[Iisys](信息系統研究所HOF University)發布和託管“德國巨大的,清潔的Common Common Crawl Corpus”(GC4)。
Google Tensorflow Research Cloud(TFRC)的Cloud TPU支持研究。感謝您提供訪問TFRC❤️
得益於擁抱面孔團隊的慷慨支持,可以從模型中心存儲和下載所有檢查站?


