gc4lm
1.0.0
이 저장소는 최근에 발표 된 "독일 거대, 깨끗한 일반 크롤링 코퍼스"(GC4)에 대해 훈련 된 독일어에 대한 거대한 (및 편향) 언어 모델을 제시하며 총 데이터 세트 크기는 ~ 844GB입니다.
면책 조항 :이 저장소에서 제시되고 훈련 된 언어 모델은 연구 목적으로 전용입니다. 훈련에 사용 된 GC4 코퍼스에는 인터넷의 크롤링 텍스트가 포함되어 있습니다. 따라서 언어 모델은 고도로 편향된 것으로 간주 될 수 있으며, 이는 성별, 인종, 민족성 및 장애 상태에 따라 전형적인 연관성을 인코딩하는 모델을 초래합니다. 릴리스 된 체크 포인트를 사용하고 작업하기 전에 다음을 읽는 것이 좋습니다.
확률 앵무새의 위험에 대해 : 언어 모델이 너무 커질 수 있습니까?
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major 및 Shmargaret Shmitchell에서.
릴리스 된 체크 포인트의 목표는 독일어의 대규모 미리 훈련 된 언어 모델에 대한 연구, 특히 편견을 식별하고이를 예방하는 방법에 대한 연구를 향상시키는 것입니다. 대부분의 연구는 현재 영어에 대해서만 수행되고 있습니다.
추가 연구 질문을 논의하거나 제시하기 위해 새로운 Github 토론 기능을 사용하십시오. 트위터에서 #gc4lm 자유롭게 사용하십시오.
GC4의 전체 HEAD 및 MIDDLE 부분을 다운로드 한 후 다운로드 된 아카이브를 추출하고 GC4 팀의 제공된 GIST와 함께 RAW 컨텐츠 (언어 점수 필터링 포함)를 추출합니다.
다른 사전 처리 스크립트에서는 전체 사전 훈련 코퍼스의 문장 분할을 수행합니다. 가장 빠른 솔루션 중 하나는 예를 들어 Spacy를 사용하는 대신 NLTK (독일 모델과 함께)를 사용하는 것입니다.
추출 후, 언어 점수 필터링 및 문장 분할, 결과 데이터 세트 크기는 844GB 입니다.
문장이 분할 된 후 다음 단계는 다음 섹션에서 설명되는 전자 호환 어휘를 만드는 것입니다.
어휘 생성 워크 플로우는 주로 "Bert의 어휘 탐색"과 최근에 발표 된 논문 "Tokenizer는 얼마나 좋은가요?"에 관한 Judit Ács의 블로그 게시물에서 영감을 얻었습니다. Phillip Rust, Jonas Pfeiffer, Ivan Vulić, Sebastian Ruder 및 Iryna Gurevych에서.
우리는 주로 명명 된 엔티티 인식 (NER), POS 태그 및 텍스트 분류와 같은 대중적인 다운 스트림 작업에 대한 교육 및 개발 데이터에 대한 서브 워드 생식력을 계산하는 데 중점을 둡니다. 이를 위해 우리는 토큰 화 된 교육 및 개발 데이터를 사용합니다.
다양한 출시 된 독일어 모델에 대한 서브 워드 생식력과 알려지지 않은 (서브) 단어의 일부를 계산합니다.
| 모델 이름 | 서브 워드 다산 | UNK 부분 |
|---|---|---|
bert-base-german-cased | 1.4433 | 0.0083% |
bert-base-german-dbmdz-cased | 1.4070 | 0.0050% |
| 이 작업 (32k) | 1.3955 | 0.0011% |
| 이 작업 (64K) | 1.3050 | 0.0011% |
그런 다음 GC4의 HEAD 와 MIDDLE 부분을 기반으로 새로운 어휘를 만들기로 결정했습니다. 새로운 어휘를 생성 할 다음 아카이브를 선택합니다.
0000_2015-48 ( HEAD 에서 2.5GB)0004_2016-44 ( HEAD , 2.1GB) 및 0006_2016-44 ( MIDDLE , 861MB)0003_2017-30 ( HEAD , 2.4GB) 및 0007_2017-51 ( MIDDLE , 1.1GB)0007_2018-30 ( HEAD , 409MB) 및 0007_2018-51 ( MIDDLE , 4.9GB)0006_2019-09 ( HEAD , 1.8GB) 및 0008_2019-30 ( MIDDLE , 2.2GB)0003_2020-10 ( HEAD , 4.5GB) 및 0007_2020-10 ( MIDDLE , 4.0GB)이로 인해 27GB 크기의 코퍼스가 어휘 생성에 사용됩니다.
우리는 멋진 Hugging Face Tokenizers 라이브러리를 사용하여 32K 및 64K 크기의 어휘를 생성하기로 결정했습니다.
GC4 코퍼스에서 첫 번째 대형 미리 훈련 된 언어 모델은 Electra 기반 모델 인 GC4Electra 입니다. V3-32 TPU의 터키 전자 모델과 동일한 매개 변수로 교육을 받았습니다. 64K 어휘를 사용합니다 (32K 모델은 현재 훈련 중).
주목 : 우리는 하나의 모델을 출시하지 않습니다. 대신, 우리는 더 많은 연구 가능성을 위해 모든 모델 체크 포인트 (100k step width)를 출시합니다.
Hugging Face Model Hub에서 다음 체크 포인트를 사용할 수 있습니다. 이 놀라운 인프라를 제공해 주셔서 감사합니다 !!
또한 허브의 각 모델에 원래 Tensorflow 체크 포인트도 포함합니다.
| 모델 허브 이름 | 체크 포인트 (단계) |
|---|---|
electra-base-gc4-64k-0-cased-discriminator - electra-base-gc4-64k-0-cased-generator | 0 (초기) |
electra-base-gc4-64k-100000-cased-discriminator -Electra electra-base-gc4-64k-100000-cased-generator | 100,000 단계 |
electra-base-gc4-64k-200000-cased-discriminator - electra-base-gc4-64k-200000-cased-generator | 200,000 단계 |
electra-base-gc4-64k-300000-cased-discriminator electra-base-gc4-64k-300000-cased-generator | 300,000 단계 |
electra-base-gc4-64k-400000-cased-discriminator electra-base-gc4-64k-400000-cased-generator | 400,000 단계 |
electra-base-gc4-64k-500000-cased-discriminator electra-base-gc4-64k-500000-cased-generator | 500,000 단계 |
electra-base-gc4-64k-600000-cased-discriminator electra-base-gc4-64k-600000-cased-generator | 600,000 단계 |
electra-base-gc4-64k-700000-cased-discriminator electra-base-gc4-64k-700000-cased-generator | 700,000 단계 |
electra-base-gc4-64k-800000-cased-discriminator electra-base-gc4-64k-800000-cased-generator | 800,000 단계 |
electra-base-gc4-64k-900000-cased-discriminator electra-base-gc4-64k-900000-cased-generator | 900,000 단계 |
electra-base-gc4-64k-1000000-cased-discriminator -Electra electra-base-gc4-64k-1000000-cased-generator | 1m 단계 |
주목 : 마스크 토큰 예측과 같은 MLM 작업에는 생성기 모델을 사용해야합니다. 판별 자 모델은 NER, POS 태깅, 텍스트 클래식 등과 같은 다운 스트림 작업을 미세 조정하는 데 사용해야합니다.
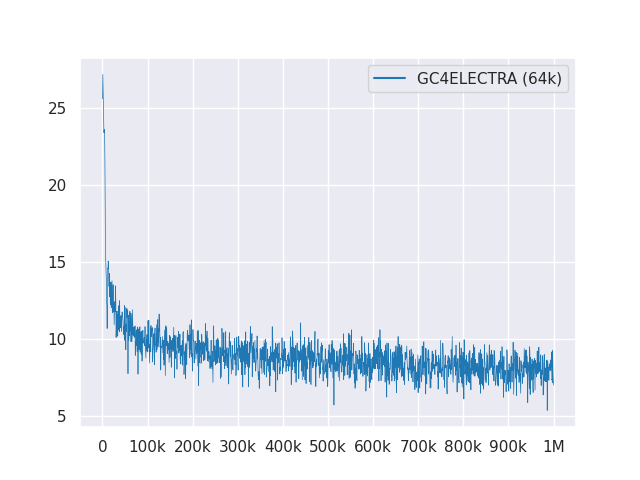
다음 플롯은 1m 단계에 걸친 손실 곡선을 보여줍니다.
모든 모델은 MIT에 따라 라이센스가 부여됩니다.
피드백을 위해 새로운 GitHub 토론을 사용하거나 제안/수정을 위해 PR을 채우십시오.
Philip May, Philipp Reißel과 [IISYS] (Institute of Information Systems Hof University)에게 "독일 거대, 청소 된 일반 크롤링 코퍼스 (GC4)를 출시하고 호스팅했습니다.
Google의 Tensorflow Research Cloud (TFRC)의 Cloud TPU를 지원하는 연구. TFRC ❤️에 대한 액세스를 제공해 주셔서 감사합니다
Hugging Face 팀의 관대 한 지원 덕분에 모델 허브에서 모든 체크 포인트를 저장하고 다운로드 할 수 있습니까?


