gc4lm
1.0.0
Этот репозиторий представляет собой колоссальную (и предвзятую) языковую модель для немецкого языка, обученного недавно выпущенному «Немецкому колоссальному, чистую общему корпусу» (GC4), с общим размером набора данных ~ 844 ГБ.
Отказ от ответственности : представленные и обученные языковые модели в этом репозитории предназначены только для исследований . Корпус GC4 - который использовался для обучения - содержит ползанные тексты из Интернета. Таким образом, языковые модели можно рассматривать как сильно предвзятые, что приводит к модели, которая кодирует стереотипные ассоциации по полу, расе, этнической принадлежности и статусу инвалидности. Прежде чем использовать и работать с выпущенными контрольно -пропускными пунктами, настоятельно рекомендуется прочитать:
Об опасностях стохастических попугаев: могут ли языковые модели быть слишком большими?
От Эмили М. Бендер, Тимнит Гебру, Анджелина Макмиллан-Маджор и Шмаргарет Шмичелл.
Целью выпущенных контрольно-пропускных пунктов является развитие исследований на крупных предварительно обученных языковых моделях для немецкого языка, особенно для выявления предубеждений и того, как их предотвратить, так как в настоящее время большинство исследований проводится только для английского языка.
Пожалуйста, используйте новую функцию обсуждения Github, чтобы обсудить или представить дополнительные вопросы исследования. Не стесняйтесь использовать #gc4lm в Twitter?
После загрузки полных HEAD и MIDDLE частей GC4 мы извлекаем загруженные архивы и извлекаем необработанный контент (включая фильтрацию на языке) с предоставленной GIST из команды GC4.
В другом сценарии предварительного обработки мы выполняем предложения по всему корпусу предварительного обучения. Одним из самых быстрых решений является использование NLTK (с немецкой моделью) вместо использования EG Spacy.
После извлечения, фильтрации на языке и разделении предложений, полученный размер набора данных составляет 844 ГБ .
После распределения предложений следующим шагом является создание электроэлектра-совместимого слова, который описан в следующем разделе.
Рабочий процесс поколения Vocab в основном вдохновлен сообщением в блоге от Judit ács о «исследующем словаре Берта» и недавно выпущенной статьей «Насколько хорош ваш токенизатор?» От Филиппа Руст, Джонаса Пфайффера, Ивана Вулича, Себастьяна Рудера и Ирины Гуреви.
В основном мы сосредоточимся на расчете фертильности подчинка на данных обучения и разработки для популярных нисходящих задач, таких как распознавание именных объектов (NER), POS -теги и классификация текста. Для этой цели мы используем токенизированные данные обучения и разработки из:
и вычислить плодородие подчинка и часть неизвестных (под) слов для различных выпущенных моделей немецкого языка:
| Название модели | Фертильность подножки | UNK Portion |
|---|---|---|
bert-base-german-cased | 1.4433 | 0,0083% |
bert-base-german-dbmdz-cased | 1.4070 | 0,0050% |
| Эта работа (32K) | 1.3955 | 0,0011% |
| Эта работа (64K) | 1.3050 | 0,0011% |
Затем мы решили создать новый словарь на основе HEAD и MIDDLE частей от GC4. Мы выбираем следующие архивы, чтобы сгенерировать новый словар:
0000_2015-48 (с HEAD , 2,5 ГБ)0004_2016-44 (от HEAD , 2,1 ГБ) и 0006_2016-44 (от MIDDLE , 861 МБ)0003_2017-30 (от HEAD , 2,4 ГБ) и 0007_2017-51 (от MIDDLE , 1,1 ГБ)0007_2018-30 (от HEAD , 409 МБ) и 0007_2018-51 (от MIDDLE , 4,9 ГБ)0006_2019-09 (от HEAD , 1,8 ГБ) и 0008_2019-30 (с MIDDLE , 2,2 ГБ)0003_2020-10 (от HEAD , 4,5 ГБ) и 0007_2020-10 (от MIDDLE , 4,0 ГБ)Это приводит к корпусу с размером 27 ГБ, который используется для поколения слова.
Мы решили генерировать словарные словесности размером 32K и 64K, используя потрясающую библиотеку Tokenizers для объятий.
Первая крупная предварительно обученная языковая модель на корпусе GC4-это модель на основе Electra: GC4ELECTRA . Он был обучен теми же параметрами, что и турецкая модель Electra на V3-32 TPU. Он использует словарь 64K (модель 32K в настоящее время тренируется).
Примечание : мы не выпускаем одну модель. Вместо этого мы выпускаем все модельные контрольно-пропускные пункты (с шириной шага 100 тыс.), Для дополнительных возможностей для исследования.
Следующие контрольно -пропускные пункты доступны в концентраторе модели обнимающего лица. Спасибо, обнимаю лицо за предоставление этой удивительной инфраструктуры!
Мы также включаем оригинальную контрольную точку TensorFlow в каждую модель на концентраторе.
| Модель Хаб название | Контрольная точка (шаг) |
|---|---|
electra-base-gc4-64k-0-cased-discriminator - electra-base-gc4-64k-0-cased-generator | 0 (начальный) |
electra-base-gc4-64k-100000-cased-discriminator - electra-base-gc4-64k-100000-cased-generator | 100 000 шагов |
electra-base-gc4-64k-200000-cased-discriminator - electra-base-gc4-64k-200000-cased-generator | 200 000 шагов |
electra-base-gc4-64k-300000-cased-discriminator - electra-base-gc4-64k-300000-cased-generator | 300 000 шагов |
electra-base-gc4-64k-400000-cased-discriminator - electra-base-gc4-64k-400000-cased-generator | 400 000 шагов |
electra-base-gc4-64k-500000-cased-discriminator - electra-base-gc4-64k-500000-cased-generator | 500 000 шагов |
electra-base-gc4-64k-600000-cased-discriminator - electra-base-gc4-64k-600000-cased-generator | 600 000 шагов |
electra-base-gc4-64k-700000-cased-discriminator - electra-base-gc4-64k-700000-cased-generator | 700 000 шагов |
electra-base-gc4-64k-800000-cased-discriminator - electra-base-gc4-64k-800000-cased-generator | 800 000 шагов |
electra-base-gc4-64k-900000-cased-discriminator - electra-base-gc4-64k-900000-cased-generator | 900 000 шагов |
electra-base-gc4-64k-1000000-cased-discriminator - electra-base-gc4-64k-1000000-cased-generator | 1м шаги |
Примечание : Вы должны использовать модели генератора для задач MLM, таких как прогноз токенов в масках. Модели дискриминатора должны использоваться для точной настройки по нисходящим задачам, таким как NER, POS-теги, классификация текста и многое другое.
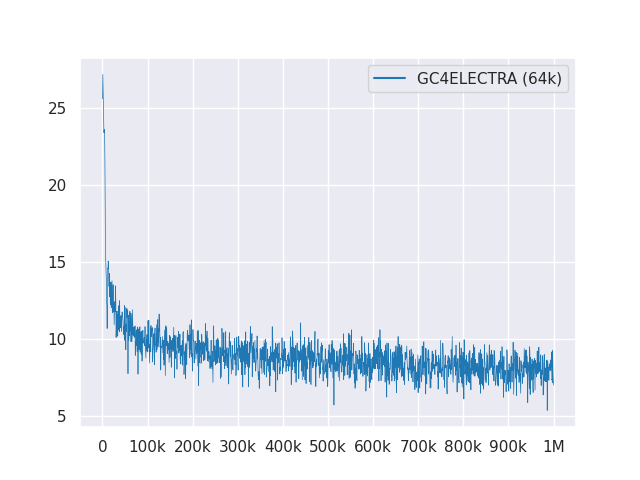
На следующем графике показана кривая потери на 1 м шага:
Все модели лицензированы под MIT.
Пожалуйста, используйте новые дискуссии GitHub для обратной связи или просто заполните пиар для предложений/исправлений.
Благодаря Филиппу Мэй, Филиппу Рейсел и [IISYS] (Институт информационных систем Университет Хоф) за выпуск и проведение «немецкого колоссального, очищенного корпуса общего труда» (GC4).
Исследования, поддерживаемые облачными TPU от Google Tensorflow Research Cloud (TFRC). Спасибо за предоставление доступа к TFRC ❤
Благодаря щедрой поддержке команды обнимающих лиц, можно хранить и загружать все контрольно -пропускные пункты с их модельного центра?


