gc4lm
1.0.0
Dieses Repository präsentiert ein kolossales (und voreingenommenes) Sprachmodell für Deutsch, der auf dem kürzlich veröffentlichten "Deutschen kolossalen, sauberen Common Crawl Corpus" (GC4) mit einer Gesamtdatensatzgröße von ~ 844 GB ausgebildet wurde.
Haftungsausschluss : Die vorgestellten und geschulten Sprachmodelle in diesem Repository dienen nur zu Forschungszwecken . Der GC4 -Korpus - der für das Training verwendet wurde - enthält krabbelende Texte aus dem Internet. Somit können die Sprachmodelle als hochvoreingenommen angesehen werden, was zu einem Modell führt, das stereotype Assoziationen entlang von Geschlecht, Rasse, ethnischer Zugehörigkeit und Behinderungstatus codiert. Bevor Sie die freigegebenen Kontrollpunkte verwenden und arbeiten, wird dies sehr empfohlen, um zu lesen:
Zu den Gefahren stochastischer Papageien: Können Sprachmodelle zu groß sein?
von Emily M. Bender, Timnit Gebru, Angelina McMillan-Major und Shmargaret Shmitchell.
Ziel der freigegebenen Kontrollpunkte ist es, die Forschung zu großen vorgeborenen Sprachmodellen für Deutsch zu steigern, insbesondere zur Identifizierung von Vorurteilen und zur Verhinderung, da die meisten Forschungen derzeit nur für Englisch durchgeführt werden.
Bitte verwenden Sie die neue Feature von GitHub -Diskussionen, um weitere Forschungsfragen zu diskutieren oder zu präsentieren. Fühlen Sie sich frei, #gc4lm auf Twitter zu verwenden?
Nach dem Herunterladen des kompletten HEAD und MIDDLE Teile des GC4 extrahierten wir die heruntergeladenen Archive und extrahieren den Rohinhalt (inkl. Sprach -Score -Filterung) mit dem bereitgestellten GIST des GC4 -Teams.
In einem anderen vorverarbeiteten Skript führen wir die Satzspaltung des gesamten Voraussetzungskorpus durch. Eine der schnellsten Lösungen besteht darin, NLTK (mit dem deutschen Modell) zu verwenden, anstatt EG Spacy zu verwenden.
Nach der Extraktion, der Filterung und der Satzaufteilung der Sprachbewertung beträgt die resultierende Datensatzgröße 844 GB .
Nach dem Aufenthalt des Satzes besteht der nächste Schritt darin, ein elektra-kompatibler Vokabale zu erstellen, der im nächsten Abschnitt beschrieben wird.
Der Workflow der Vocab Generation ist hauptsächlich von einem Blog -Beitrag von Judit Ács über "Erkundung von Berts Wortschatz" und eine kürzlich veröffentlichte Arbeit "Wie gut ist Ihr Tokenizer" inspiriert? Von Phillip Rust, Jonas Pfeiffer, Ivan Vulić, Sebastian Ruder und Iryna Gurevych.
Wir konzentrieren uns hauptsächlich auf die Berechnung der Subword -Fertilität auf die Schulungs- und Entwicklungsdaten für beliebte nachgeschaltete Aufgaben wie die benannte Entitätserkennung (NER), POS -Tagging und Textklassifizierung. Zu diesem Zweck verwenden wir die tokenisierten Trainings- und Entwicklungsdaten aus:
und berechnen Sie die Subword -Fruchtbarkeit und den Teil unbekannter (Sub-) Wörter für verschiedene freigegebene Deutsche Sprachmodelle:
| Modellname | Subword -Fruchtbarkeit | UNK -Teil |
|---|---|---|
bert-base-german-cased | 1.4433 | 0,0083% |
bert-base-german-dbmdz-cased | 1.4070 | 0,0050% |
| Diese Arbeit (32k) | 1.3955 | 0,0011% |
| Diese Arbeit (64k) | 1.3050 | 0,0011% |
Wir beschlossen dann, ein neues Vokabular zu erstellen, das auf HEAD und MIDDLE Teilen von GC4 basiert. Wir wählen die folgenden Archive aus, um ein neues Vokabale zu generieren:
0000_2015-48 (vom HEAD , 2,5 GB)0004_2016-44 (aus HEAD , 2,1 GB) und 0006_2016-44 (aus MIDDLE , 861 MB)0003_2017-30 (aus HEAD , 2,4 GB) und 0007_2017-51 (aus MIDDLE , 1,1 GB)0007_2018-30 (aus HEAD , 409 MB) und 0007_2018-51 (aus MIDDLE , 4,9 GB)0006_2019-09 (aus HEAD , 1,8 GB) und 0008_2019-30 (aus MIDDLE , 2,2 GB)0003_2020-10 (aus HEAD , 4,5 GB) und 0007_2020-10 (aus MIDDLE , 4,0 GB)Dies führt zu einem Korpus mit einer Größe von 27 GB, die für die Vokabazerstellung verwendet wird.
Wir haben uns entschlossen, sowohl ein 32 -km- als auch ein 64 -km großer Vokabular zu erzeugen, wobei wir die fantastische Bibliothek mit Face -Tipperizern verwenden.
Das erste große, vorgeborene Sprachmodell auf dem GC4-Korpus ist ein elektrabasiertes Modell: GC4Lectra . Es wurde mit den gleichen Parametern wie das türkische Elektralodell auf einer V3-32-TPU trainiert. Es verwendet das 64K -Vokabular (32K -Modell trainiert derzeit).
HINWEIS : Wir geben kein Modell los. Stattdessen veröffentlichen wir alle Modellkontrollpunkte (mit einer Stufenbreite von 100.000) für weitere Forschungsmöglichkeiten.
Die folgenden Kontrollpunkte sind über den Hub des Umarmungsgesichtsmodells erhältlich. Vielen Dank umarmen Gesicht für die Bereitstellung dieser erstaunlichen Infrastruktur !!
Wir nehmen auch den originalen TensorFlow -Checkpoint in jedes Modell auf der Hub ein.
| Model Hub -Name | Checkpoint (Schritt) |
|---|---|
electra-base-gc4-64k-0-cased-discriminator - electra-base-gc4-64k-0-cased-generator | 0 (initial) |
electra-base-gc4-64k-100000-cased-discriminator - electra-base-gc4-64k-100000-cased-generator | 100.000 Schritte |
electra-base-gc4-64k-200000-cased-discriminator - electra-base-gc4-64k-200000-cased-generator | 200.000 Schritte |
electra-base-gc4-64k-300000-cased-discriminator - electra-base-gc4-64k-300000-cased-generator | 300.000 Schritte |
electra-base-gc4-64k-400000-cased-discriminator - electra-base-gc4-64k-400000-cased-generator | 400.000 Schritte |
electra-base-gc4-64k-500000-cased-discriminator - electra-base-gc4-64k-500000-cased-generator | 500.000 Schritte |
electra-base-gc4-64k-600000-cased-discriminator - electra-base-gc4-64k-600000-cased-generator | 600.000 Schritte |
electra-base-gc4-64k-700000-cased-discriminator - electra-base-gc4-64k-700000-cased-generator | 700.000 Schritte |
electra-base-gc4-64k-800000-cased-discriminator - electra-base-gc4-64k-800000-cased-generator | 800.000 Schritte |
electra-base-gc4-64k-900000-cased-discriminator - electra-base-gc4-64k-900000-cased-generator | 900.000 Schritte |
electra-base-gc4-64k-1000000-cased-discriminator - electra-base-gc4-64k-1000000-cased-generator | 1m Schritte |
Hinweis : Sie sollten die Generatormodelle für MLM -Aufgaben wie maskierte Token -Vorhersage verwenden. Die Diskriminatormodelle sollten zur Feinabstimmung bei nachgeschalteten Aufgaben wie NER, POS-Tagging, Textklassifizierung und vielen anderen verwendet werden.
Das folgende Diagramm zeigt die Verlustkurve über 1M Schritte:
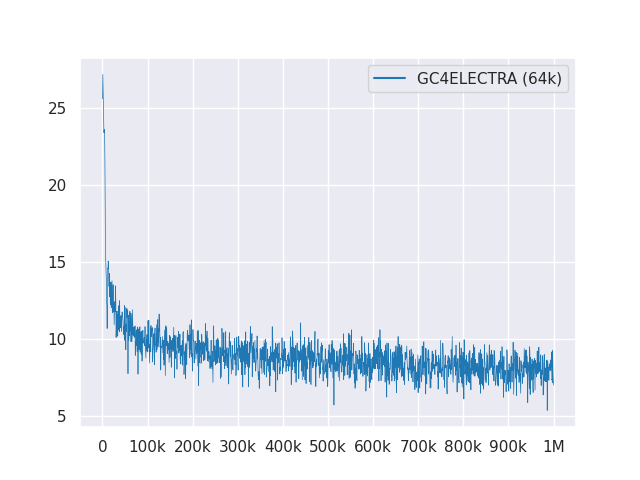
Alle Modelle sind unter MIT lizenziert.
Bitte verwenden Sie die neuen Github -Diskussionen für Feedback oder füllen Sie einfach eine PR für Vorschläge/Korrekturen aus.
Vielen Dank an Philip May, Philipp Reißel und an [IISYS] (das Institute of Information Systems Hof University) für die Veröffentlichung und Ausrichtung des "deutschen kolossalen, gereinigten Common Crawl Corpus" (GC4).
Forschung, die mit Cloud -TPUs aus der TensorFlow Research Cloud (TFRC) von Google unterstützt wird. Vielen Dank für den Zugang zum TFRC ❤️
Dank der großzügigen Unterstützung des umarmenden Face -Teams ist es möglich, alle Kontrollpunkte von ihrem Modellzentrum zu speichern und herunterzuladen?


