gc4lm
1.0.0
พื้นที่เก็บข้อมูลนี้นำเสนอรูปแบบภาษาขนาดมหึมา (และลำเอียง) สำหรับภาษาเยอรมันที่ผ่านการฝึกอบรมเกี่ยวกับ "German Colossal, Clean Common Crawl Corpus" (GC4) ที่เพิ่งเปิดตัวเมื่อเร็ว ๆ นี้โดยมีขนาดชุดข้อมูลทั้งหมด ~ 844GB
ข้อจำกัดความรับผิดชอบ : แบบจำลองภาษาที่นำเสนอและได้รับการฝึกอบรมในที่เก็บนี้มีวัตถุประสงค์เพื่อ การวิจัยเท่านั้น GC4 Corpus - ที่ใช้สำหรับการฝึกอบรม - มีข้อความที่รวบรวมข้อมูลจากอินเทอร์เน็ต ดังนั้นแบบจำลองภาษาจึงถือได้ว่ามีอคติสูงส่งผลให้แบบจำลองที่เข้ารหัสความสัมพันธ์แบบโปรเฟสเซอร์ตามเพศเชื้อชาติเชื้อชาติและสถานะความพิการ ก่อนที่จะใช้และทำงานกับจุดตรวจสอบที่ปล่อยออกมาขอแนะนำให้อ่าน:
เกี่ยวกับอันตรายของนกแก้วสุ่ม: โมเดลภาษาจะใหญ่เกินไปได้หรือไม่?
จาก Emily M. Bender, Timnit Gebru, Angelina McMillan-Major และ Shmargaret Shmitchell
จุดมุ่งหมายของจุดตรวจที่ปล่อยออกมาคือการเพิ่มการวิจัยเกี่ยวกับแบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อนขนาดใหญ่สำหรับภาษาเยอรมันโดยเฉพาะอย่างยิ่งสำหรับการระบุอคติและวิธีการป้องกันพวกเขาเนื่องจากการวิจัยส่วนใหญ่ทำสำหรับภาษาอังกฤษเท่านั้น
โปรดใช้คุณสมบัติการอภิปราย GitHub ใหม่เพื่อพูดคุยหรือนำเสนอคำถามการวิจัยเพิ่มเติม อย่าลังเลที่จะใช้ #gc4lm บน Twitter?
หลังจากดาวน์โหลด HEAD และส่วน MIDDLE สมบูรณ์ของ GC4 เราได้แยกคลังเก็บที่ดาวน์โหลดมาและแยกเนื้อหาดิบ (รวมการกรองคะแนนภาษา) ด้วย GIST ที่ให้มาจากทีม GC4
ในสคริปต์การประมวลผลล่วงหน้าอื่นเราทำการแยกประโยคของคลังข้อมูลก่อนการฝึกอบรมทั้งหมด หนึ่งในโซลูชั่นที่เร็วที่สุดคือการใช้ NLTK (กับรุ่นเยอรมัน) แทนที่จะใช้ EG spacy
หลังจากการสกัดการกรองคะแนนภาษาและการแยกประโยคขนาดชุดข้อมูลผลลัพธ์คือ 844GB
หลังจากการแยกประโยคขั้นตอนต่อไปคือการสร้างคำศัพท์ที่เข้ากันได้กับอิเลคตร้าซึ่งอธิบายไว้ในส่วนถัดไป
เวิร์กโฟลว์การสร้างคำศัพท์ส่วนใหญ่ได้รับแรงบันดาลใจจากโพสต์บล็อกจาก Judit ácsเกี่ยวกับ "การสำรวจคำศัพท์ของเบิร์ต" และกระดาษที่เพิ่งเปิดตัว "Tokenizer ของคุณดีแค่ไหน?" จาก Phillip Rust, Jonas Pfeiffer, Ivan Vulić, Sebastian Ruder และ Iryna Gurevych
เรามุ่งเน้นไปที่การคำนวณความอุดมสมบูรณ์ของ Subword ในข้อมูลการฝึกอบรมและการพัฒนาสำหรับงานดาวน์สตรีมยอดนิยมเช่นการจดจำเอนทิตีที่มีชื่อ (NER) การติดแท็ก POS และการจำแนกประเภทข้อความ เพื่อจุดประสงค์นั้นเราใช้ข้อมูลการฝึกอบรมและการพัฒนาโทเค็นจาก:
และคำนวณความอุดมสมบูรณ์ของคำศัพท์ subword และส่วนของคำที่ไม่รู้จัก (ย่อย) สำหรับโมเดลภาษาเยอรมันที่ปล่อยออกมาต่างๆ:
| ชื่อนางแบบ | ความอุดมสมบูรณ์ของคำศัพท์ | ส่วน UNK |
|---|---|---|
bert-base-german-cased | 1.4433 | 0.0083% |
bert-base-german-dbmdz-cased | 1.4070 | 0.0050% |
| งานนี้ (32K) | 1.3955 | 0.0011% |
| งานนี้ (64k) | 1.3050 | 0.0011% |
จากนั้นเราตัดสินใจที่จะสร้างคำศัพท์ใหม่ตาม HEAD และชิ้น MIDDLE จาก GC4 เราเลือกคลังเก็บต่อไปนี้เพื่อสร้างคำศัพท์ใหม่บน:
0000_2015-48 (จาก HEAD 2.5GB)0004_2016-44 (จาก HEAD , 2.1GB) และ 0006_2016-44 (จาก MIDDLE , 861MB)0003_2017-30 (จาก HEAD , 2.4GB) และ 0007_2017-51 (จาก MIDDLE , 1.1GB)0007_2018-30 (จาก HEAD , 409MB) และ 0007_2018-51 (จาก MIDDLE , 4.9GB)0006_2019-09 (จาก HEAD , 1.8GB) และ 0008_2019-30 (จาก MIDDLE , 2.2GB)0003_2020-10 (จาก HEAD , 4.5GB) และ 0007_2020-10 (จาก MIDDLE , 4.0GB)สิ่งนี้ส่งผลให้คลังข้อมูลที่มีขนาด 27GB ที่ใช้สำหรับการสร้างคำศัพท์
เราตัดสินใจที่จะสร้างทั้งคำศัพท์ขนาด 32K และ 64K โดยใช้ห้องสมุดโทเคนิเซอร์ใบหน้าที่ยอดเยี่ยม
แบบจำลองภาษาที่ผ่านการฝึกอบรมล่วงหน้าขนาดใหญ่ครั้งแรกใน GC4 Corpus เป็นแบบจำลอง Electra: GC4Electra มันได้รับการฝึกฝนด้วยพารามิเตอร์เดียวกับแบบจำลอง Electra ตุรกีบน V3-32 TPU มันใช้คำศัพท์ 64K (รุ่น 32K กำลังฝึกอบรม)
ข้อสังเกต : เราไม่ปล่อยรุ่น เดียว แต่เราปล่อยจุดตรวจสอบทั้งหมด (ด้วยความกว้างขั้นตอน 100K) เพื่อความเป็นไปได้ในการวิจัยเพิ่มเติม
จุดตรวจสอบต่อไปนี้มีให้บริการจาก Hugging Face Model Hub ขอบคุณ Hugging Face สำหรับการจัดหาโครงสร้างพื้นฐานที่น่าตื่นตาตื่นใจนี้ !!
นอกจากนี้เรายังรวมจุดตรวจสอบ Tensorflow ดั้งเดิมในแต่ละรุ่นบนฮับ
| ชื่อฮับรุ่น | จุดตรวจ (ขั้นตอน) |
|---|---|
electra-base-gc4-64k-0-cased-discriminator - electra-base-gc4-64k-0-cased-generator | 0 (เริ่มต้น) |
electra-base-gc4-64k-100000-cased-discriminator - electra-base-gc4-64k-100000-cased-generator | 100,000 ขั้นตอน |
electra-base-gc4-64k-200000-cased-discriminator - electra-base-gc4-64k-200000-cased-generator | 200,000 ขั้นตอน |
electra-base-gc4-64k-300000-cased-discriminator - electra-base-gc4-64k-300000-cased-generator | 300,000 ขั้นตอน |
electra-base-gc4-64k-400000-cased-discriminator - electra-base-gc4-64k-400000-cased-generator | 400,000 ขั้นตอน |
electra-base-gc4-64k-500000-cased-discriminator - electra-base-gc4-64k-500000-cased-generator | 500,000 ขั้นตอน |
electra-base-gc4-64k-600000-cased-discriminator - electra-base-gc4-64k-600000-cased-generator | 600,000 ขั้นตอน |
electra-base-gc4-64k-700000-cased-discriminator - electra-base-gc4-64k-700000-cased-generator | 700,000 ขั้นตอน |
electra-base-gc4-64k-800000-cased-discriminator - electra-base-gc4-64k-800000-cased-generator | 800,000 ขั้นตอน |
electra-base-gc4-64k-900000-cased-discriminator - electra-base-gc4-64k-900000-cased-generator | 900,000 ขั้นตอน |
electra-base-gc4-64k-1000000-cased-discriminator - electra-base-gc4-64k-1000000-cased-generator | ขั้นตอน 1m |
ข้อสังเกต : คุณควรใช้โมเดลเครื่องกำเนิดไฟฟ้าสำหรับงาน MLM เช่นการทำนายโทเค็นที่สวมหน้ากาก โมเดล discriminator ควรใช้สำหรับการปรับแต่งอย่างละเอียดในงานดาวน์สตรีมเช่น NER, การติดแท็ก POS, การจำแนกประเภทข้อความและอื่น ๆ อีกมากมาย
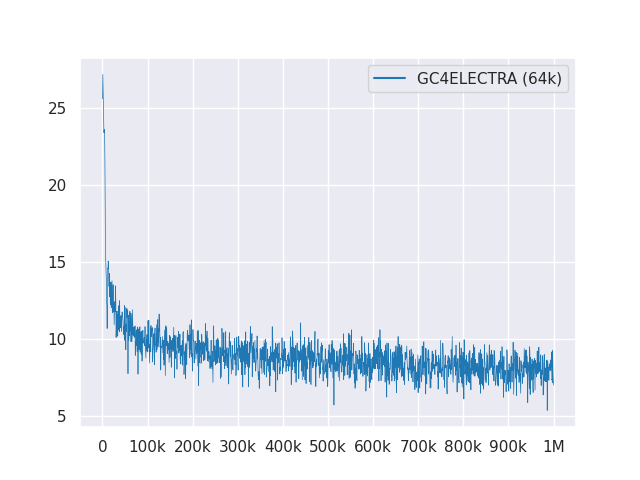
พล็อตต่อไปนี้แสดงเส้นโค้งการสูญเสียผ่านขั้นตอน 1 ม.:
ทุกรุ่นได้รับใบอนุญาตภายใต้ MIT
โปรดใช้การอภิปราย GitHub ใหม่สำหรับข้อเสนอแนะหรือเพียงแค่เติม PR สำหรับคำแนะนำ/การแก้ไข
ต้องขอบคุณ Philip May, Philipp Reißelและ [IISYS] (สถาบันระบบสารสนเทศ HOF University) สำหรับการปล่อยและเป็นเจ้าภาพ "German Colossal ทำความสะอาดคลังข้อมูลการรวบรวมข้อมูลทั่วไป" (GC4)
การวิจัยสนับสนุนด้วยคลาวด์ TPU จาก Cloud Tensorflow Research Cloud (TFRC) ของ Google ขอบคุณที่ให้การเข้าถึง TFRC ❤
ต้องขอบคุณการสนับสนุนที่ใจดีจากทีม Hugging Face จึงเป็นไปได้ที่จะจัดเก็บและดาวน์โหลดจุดตรวจทั้งหมดจาก Hub Model Model หรือไม่?


