gc4lm
1.0.0
Repositori ini menyajikan model bahasa kolosal (dan bias) untuk Jerman yang dilatih pada "jerman corpus crawl crawl yang bersih dan bersih (GC4), dengan ukuran total dataset ~ 844GB.
Penafian : Model bahasa yang disajikan dan terlatih dalam repositori ini hanya untuk tujuan penelitian . Corpus GC4 - yang digunakan untuk pelatihan - berisi teks -teks merangkak dari internet. Dengan demikian, model bahasa dapat dianggap sangat bias, menghasilkan model yang mengkodekan asosiasi stereotip di sepanjang gender, ras, etnis dan status kecacatan. Sebelum menggunakan dan bekerja dengan pos pemeriksaan yang dirilis, sangat disarankan untuk membaca:
Tentang bahaya burung beo stokastik: Bisakah model bahasa terlalu besar?
Dari Emily M. Bender, Timnit Gebru, Angelina McMillan-Mayor dan Shmargaret Shmitchell.
Tujuan dari pos pemeriksaan yang dirilis adalah untuk meningkatkan penelitian pada model bahasa pra-terlatih besar untuk Jerman, terutama untuk mengidentifikasi bias dan bagaimana mencegahnya, karena sebagian besar penelitian saat ini dilakukan hanya untuk bahasa Inggris.
Harap gunakan fitur Diskusi GitHub baru untuk membahas atau menyajikan pertanyaan penelitian lebih lanjut. Jangan ragu untuk menggunakan #gc4lm di Twitter?
Setelah mengunduh bagian HEAD dan MIDDLE lengkap GC4, kami mengekstrak arsip yang diunduh dan mengekstrak konten mentah (termasuk penyaringan skor bahasa) dengan inti yang disediakan dari tim GC4.
Dalam skrip pra-pemrosesan lainnya, kami melakukan pemisahan kalimat dari seluruh korpus pra-pelatihan. Salah satu solusi tercepat adalah menggunakan NLTK (dengan model Jerman) alih -alih menggunakan EG Spacy.
Setelah ekstraksi, penyaringan skor bahasa dan pemisahan kalimat, ukuran dataset yang dihasilkan adalah 844GB .
Setelah kalimat yang melekatkan langkah selanjutnya adalah membuat kosakata yang kompatibel dengan elektra, yang dijelaskan pada bagian selanjutnya.
Alur kerja Generasi Vocab terutama terinspirasi oleh posting blog dari Judit ács tentang "Menjelajahi Kosakata Bert" dan makalah yang baru dirilis "Seberapa Baik Tokenizer Anda?" Dari Phillip Rust, Jonas Pfeiffer, Ivan Volić, Sebastian Ruder dan Iryna Gurevych.
Kami terutama fokus pada penghitungan kesuburan subword pada data pelatihan dan pengembangan untuk tugas hilir populer seperti Named Entity Recognition (NER), POS Tagging dan klasifikasi teks. Untuk tujuan itu kami menggunakan data pelatihan dan pengembangan tokenisasi dari:
dan menghitung kesuburan subword dan bagian dari kata -kata yang tidak diketahui (sub) untuk berbagai model bahasa Jerman yang dirilis:
| Nama model | Kesuburan subword | Porsi UNK |
|---|---|---|
bert-base-german-cased | 1.4433 | 0,0083% |
bert-base-german-dbmdz-cased | 1.4070 | 0,0050% |
| Pekerjaan ini (32k) | 1.3955 | 0,0011% |
| Pekerjaan ini (64k) | 1.3050 | 0,0011% |
Kami kemudian memutuskan untuk membuat kosakata baru berdasarkan bagian HEAD dan MIDDLE dari GC4. Kami memilih arsip berikut untuk menghasilkan vocab baru di:
0000_2015-48 (dari HEAD , 2.5GB)0004_2016-44 (dari HEAD , 2.1GB) dan 0006_2016-44 (dari MIDDLE , 861MB)0003_2017-30 (dari HEAD , 2.4GB) dan 0007_2017-51 (dari MIDDLE , 1.1GB)0007_2018-30 (dari HEAD , 409MB) dan 0007_2018-51 (dari MIDDLE , 4.9GB)0006_2019-09 (dari HEAD , 1.8GB) dan 0008_2019-30 (dari MIDDLE , 2.2GB)0003_2020-10 (dari HEAD , 4.5GB) dan 0007_2020-10 (dari MIDDLE , 4.0GB)Ini menghasilkan corpus dengan ukuran 27GB yang digunakan untuk generasi kosakata.
Kami memutuskan untuk menghasilkan kosakata berukuran 32K dan 64K, menggunakan perpustakaan Tokenizer Face yang luar biasa.
Model bahasa pra-terlatih besar pertama pada gc4 corpus adalah model berbasis electra: GC4electra . Itu dilatih dengan parameter yang sama dengan model Electra Turki pada TPU V3-32. Ini menggunakan kosakata 64K (model 32K saat ini pelatihan).
Perhatikan : Kami tidak merilis satu model. Sebagai gantinya, kami merilis semua pos pemeriksaan model (dengan selebar langkah 100 ribu), untuk kemungkinan penelitian lebih lanjut.
Pos pemeriksaan berikut tersedia dari Hugging Face Model Hub. Terima kasih memeluk wajah karena menyediakan infrastruktur yang luar biasa ini !!
Kami juga menyertakan pos pemeriksaan TensorFlow asli di setiap model di hub.
| Nama Hub Model | CHECKPOINT (Langkah) |
|---|---|
electra-base-gc4-64k-0-cased-discriminator - electra-base-gc4-64k-0-cased-generator | 0 (awal) |
electra-base-gc4-64k-100000-cased-discriminator - electra-base-gc4-64k-100000-cased-generator | 100.000 langkah |
electra-base-gc4-64k-200000-cased-discriminator - electra-base-gc4-64k-200000-cased-generator | 200.000 langkah |
electra-base-gc4-64k-300000-cased-discriminator - electra-base-gc4-64k-300000-cased-generator | 300.000 langkah |
electra-base-gc4-64k-400000-cased-discriminator - electra-base-gc4-64k-400000-cased-generator | 400.000 langkah |
electra-base-gc4-64k-500000-cased-discriminator - electra-base-gc4-64k-500000-cased-generator | 500.000 langkah |
electra-base-gc4-64k-600000-cased-discriminator - electra-base-gc4-64k-600000-cased-generator | 600.000 langkah |
electra-base-gc4-64k-700000-cased-discriminator - electra-base-gc4-64k-700000-cased-generator | 700.000 langkah |
electra-base-gc4-64k-800000-cased-discriminator - electra-base-gc4-64k-800000-cased-generator | 800.000 langkah |
electra-base-gc4-64k-900000-cased-discriminator - electra-base-gc4-64k-900000-cased-generator | 900.000 langkah |
electra-base-gc4-64k-1000000-cased-discriminator - electra-base-gc4-64k-1000000-cased-generator | Langkah 1m |
Perhatikan : Anda harus menggunakan model generator untuk tugas MLM seperti prediksi token bertopeng. Model diskriminator harus digunakan untuk menyempurnakan tugas hilir seperti NER, penandaan POS, klasifikasi teks dan banyak lagi.
Plot berikut menunjukkan kurva kehilangan lebih dari 1m langkah:
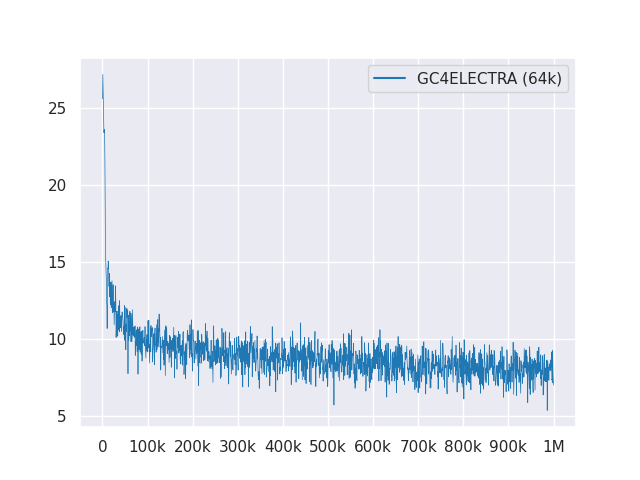
Semua model dilisensikan di bawah MIT.
Harap gunakan diskusi GitHub baru untuk umpan balik atau cukup isi PR untuk saran/koreksi.
Terima kasih kepada Philip May, Philipp Reißel dan kepada [IISYS] (Institut Sistem Informasi HOF University) untuk merilis dan menjadi tuan rumah "jerman kolosal, corpus merangkak umum yang dibersihkan" (GC4).
Penelitian yang didukung dengan Cloud TPU dari Google TensorFlow Research Cloud (TFRC). Terima kasih telah menyediakan akses ke TFRC ❤️
Berkat dukungan murah hati dari tim Face Hugging, dimungkinkan untuk menyimpan dan mengunduh semua pos pemeriksaan dari hub model mereka?


