gc4lm
1.0.0
该存储库为德国人提供了一个巨大的(且有偏见的)语言模型,该模型在最近发布的“德国巨大,干净的普通爬行语料库”(GC4)中,总数据集大小约为844GB。
免责声明:此存储库中提出的和训练有素的语言模型仅用于研究目的。 GC4语料库(用于培训)包含互联网上的爬行文本。因此,可以将语言模型视为高度偏见,从而产生了一个模型,该模型编码沿性别,种族,种族和残疾状况的刻板印象关联。在使用并使用已发布的检查点之前,强烈建议阅读:
关于随机鹦鹉的危险:语言模型会太大吗?
来自Emily M. Bender,Timnit Gebru,Angelina McMillan-Major和Shmargaret Shmitchell。
发布的检查站的目的是促进针对德语的大型预训练的语言模型的研究,尤其是确定偏见和如何预防它们,因为大多数研究目前仅针对英语进行。
请使用新的GitHub讨论功能来讨论或提出进一步的研究问题。可以随意在Twitter上使用#gc4lm 。
下载GC4的完整HEAD和MIDDLE部分后,我们提取下载的档案馆,并通过GC4团队提供的GIST提取原始内容(包括语言得分过滤)。
在另一个预处理脚本中,我们对整个预训练语料库进行句子分解。最快的解决方案之一是使用NLTK(带有德国模型),而不是使用EG Spacy。
提取后,语言得分过滤和句子分割后,结果数据集大小为844GB 。
句子分解后,下一步是创建一个兼容的兼容词汇,这在下一节中进行了描述。
词汇一代的工作流程主要灵感来自Juditács的博客文章,介绍了“探索Bert的词汇”和最近发行的论文“您的令牌器有多好?”来自Phillip Rust,Jonas Pfeiffer,IvanVulić,Sebastian Ruder和Iryna Gurevych。
我们主要专注于计算流行下游任务的培训和开发数据的子词生育能力,例如命名实体识别(NER),POS标签和文本分类。为此,我们使用以下方式的令牌化培训和开发数据:
并计算各种德语模型的未知(子)单词的子词生育能力和部分:
| 模型名称 | 子词生育能力 | UNK部分 |
|---|---|---|
bert-base-german-cased | 1.4433 | 0.0083% |
bert-base-german-dbmdz-cased | 1.4070 | 0.0050% |
| 这项工作(32K) | 1.3955 | 0.0011% |
| 这项工作(64k) | 1.3050 | 0.0011% |
然后,我们决定根据GC4的HEAD和MIDDLE部分创建一个新的词汇。我们选择以下档案以生成新的词汇:
0000_2015-48 (来自HEAD ,2.5GB)0004_2016-44 (来自HEAD ,2.1GB)和0006_2016-44 (来自MIDDLE ,861MB)0003_2017-30 (来自HEAD ,2.4GB)和0007_2017-51 ( MIDDLE ,1.1GB)0007_2018-30 (来自HEAD ,409MB)和0007_2018-51 ( MIDDLE ,4.9GB)0006_2019-09 (来自HEAD ,1.8GB)和0008_2019-30 (来自MIDDLE ,2.2GB)0003_2020-10 (来自HEAD ,4.5GB)和0007_2020-10 ( MIDDLE ,4.0GB)这会导致用于词汇生成的27GB大小的语料库。
我们决定使用令人敬畏的拥抱脸庞图书馆来生成32K和64K大小的词汇。
GC4语料库上的第一个大型预训练的语言模型是基于电气的模型: GC4Electra 。它的参数与V3-32 TPU上的土耳其Electra模型相同的参数进行了训练。它使用64k词汇(当前正在训练32K型号)。
注意:我们不发布一个模型。取而代之的是,我们发布了所有模型检查点(具有100K阶梯),以获取更多的研究可能性。
可以从拥抱面模型中心可用以下检查站。感谢拥抱的脸提供这个惊人的基础设施!!
我们还在集线器上的每个型号中包括原始的张量集检查点。
| 模型集线器名称 | 检查点(步骤) |
|---|---|
electra-base-gc4-64k-0-cased-discriminator -Electra electra-base-gc4-64k-0-cased-generator | 0(初始) |
electra-base-gc4-64k-100000-cased-discriminator -Electra electra-base-gc4-64k-100000-cased-generator | 100,000步 |
electra-base-gc4-64k-200000-cased-discriminator -Electra electra-base-gc4-64k-200000-cased-generator | 200,000步 |
electra-base-gc4-64k-300000-cased-discriminator -Electra electra-base-gc4-64k-300000-cased-generator | 300,000步 |
electra-base-gc4-64k-400000-cased-discriminator -Electra electra-base-gc4-64k-400000-cased-generator | 40万步 |
electra-base-gc4-64k-500000-cased-discriminator -Electra electra-base-gc4-64k-500000-cased-generator | 500,000步 |
electra-base-gc4-64k-600000-cased-discriminator -Electra electra-base-gc4-64k-600000-cased-generator | 600,000步 |
electra-base-gc4-64k-700000-cased-discriminator electra-base-gc4-64k-700000-cased-generator | 700,000步 |
electra-base-gc4-64k-800000-cased-discriminator -Electra electra-base-gc4-64k-800000-cased-generator | 800,000步 |
electra-base-gc4-64k-900000-cased-discriminator - electra-base-gc4-64k-900000-cased-generator | 900,000步 |
electra-base-gc4-64k-1000000-cased-discriminator electra-base-gc4-64k-1000000-cased-generator | 1M步骤 |
注意:您应该将发电机模型用于MLM任务,例如蒙版令牌预测。鉴别模型应用于在下游任务,诸如NER,POS标记,文本类别等的下游任务上进行微调。
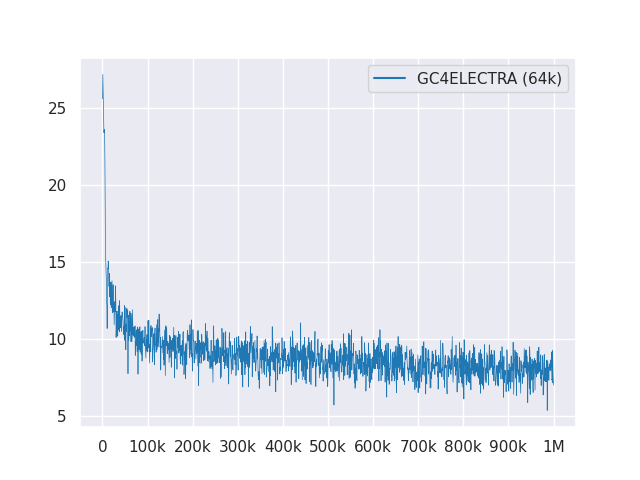
以下图显示了超过1M步骤的损耗曲线:
所有型号均在麻省理工学院下获得许可。
请使用新的GitHub讨论进行反馈,或者只是填写PR以进行建议/更正。
感谢Philip May,PhilippReißel和[Iisys](信息系统研究所HOF University)发布和托管“德国巨大的,清洁的Common Common Crawl Corpus”(GC4)。
Google Tensorflow Research Cloud(TFRC)的Cloud TPU支持研究。感谢您提供访问TFRC❤️
得益于拥抱面孔团队的慷慨支持,可以从模型中心存储和下载所有检查站?


