gc4lm
1.0.0
Este repositório apresenta um modelo de idioma colossal (e tendencioso) para alemão treinado no recém -lançado "colossal alemão, corpus de rastreamento comum" (GC4), com um tamanho total do conjunto de dados de ~ 844 GB.
Isenção de responsabilidade : Os modelos de idiomas apresentados e treinados neste repositório são apenas para fins de pesquisa . O corpus GC4 - que foi usado para treinamento - contém textos rastejados da Internet. Assim, os modelos de linguagem podem ser considerados altamente tendenciosos, resultando em um modelo que codifica associações estereotipadas ao longo do status de gênero, raça, etnia e incapacidade. Antes de usar e trabalhar com os pontos de verificação lançados, é altamente recomendável ler:
Sobre os perigos dos papagaios estocásticos: os modelos de linguagem podem ser muito grandes?
De Emily M. Bender, Timnit Gebru, Angelina McMillan-Major e Shmargaret Shmitchell.
O objetivo dos postos de controle liberado é aumentar a pesquisa sobre grandes modelos de idiomas pré-treinados para alemão, especialmente para identificar vieses e como evitá-los, pois a maioria das pesquisas é realizada atualmente apenas para inglês.
Use o novo recurso de discussões do Github para discutir ou apresentar outras questões de pesquisa. Sinta -se à vontade para usar #gc4lm no Twitter?
Depois de baixar as partes completas HEAD e MIDDLE do GC4, extraímos os arquivos baixados e extraímos o conteúdo bruto (incl.
Em outro script de pré-processamento, realizamos divisões de frases de todo o corpus de pré-treinamento. Uma das soluções mais rápidas é usar o NLTK (com o modelo alemão) em vez de usar o EG Spacy.
Após a extração, a filtragem da pontuação do idioma e a divisão de frases, o tamanho do conjunto de dados resultante é de 844 GB .
Após a divisão de frases, a próxima etapa é criar um vocabulário compatível com Electra, que é descrito na próxima seção.
O fluxo de trabalho da geração de vocabulários é inspirado principalmente por uma postagem no blog de Judit ACs sobre "Explorando o vocabulário de Bert" e um artigo recentemente lançado "Quão bom é o seu tokenizador?" De Phillip Rust, Jonas Pfeiffer, Ivan Vulić, Sebastian Ruder e Iryna Gurevych.
Nós nos concentramos principalmente no cálculo da fertilidade do subglema nos dados de treinamento e desenvolvimento para tarefas populares a jusante, como reconhecimento de entidade nomeado (NER), marcação de POS e classificação de texto. Para esse fim, usamos os dados de treinamento e desenvolvimento tokenizados de:
e calcule a fertilidade e a parte do subpainhas de palavras desconhecidas (sub) para vários modelos de idiomas alemães liberados:
| Nome do modelo | Fertilidade do subpainha | Parte UNK |
|---|---|---|
bert-base-german-cased | 1.4433 | 0,0083% |
bert-base-german-dbmdz-cased | 1.4070 | 0,0050% |
| Este trabalho (32k) | 1.3955 | 0,0011% |
| Este trabalho (64k) | 1.3050 | 0,0011% |
Decidimos então criar um novo vocabulário baseado nas partes HEAD e MIDDLE do GC4. Selecionamos os seguintes arquivos para gerar um novo vocabulário em:
0000_2015-48 (da HEAD , 2,5 GB)0004_2016-44 (da HEAD , 2,1 GB) e 0006_2016-44 (do MIDDLE , 861MB)0003_2017-30 (da HEAD , 2,4 GB) e 0007_2017-51 (do MIDDLE , 1,1 GB)0007_2018-30 (da HEAD , 409 MB) e 0007_2018-51 (do MIDDLE , 4,9 GB)0006_2019-09 (da HEAD , 1,8 GB) e 0008_2019-30 (do MIDDLE , 2,2 GB)0003_2020-10 (da HEAD , 4,5 GB) e 0007_2020-10 (do MIDDLE , 4,0 GB)Isso resulta em um corpus com um tamanho de 27 GB usado para geração de vocabulário.
Decidimos gerar vocabulários de 32k e 64K, usando a incrível biblioteca de tokenizadores de face abraçados.
O primeiro grande modelo de idioma pré-treinado no corpus GC4 é um modelo baseado em electra: GC4Electra . Foi treinado com os mesmos parâmetros que o modelo turco Electra em uma TPU V3-32. Ele usa o vocabulário de 64k (o modelo 32K está treinando no momento).
Aviso : não lançamos um modelo. Em vez disso, lançamos todos os pontos de verificação do modelo (com uma largura de 100 mil), para mais possibilidades de pesquisa.
Os seguintes pontos de verificação estão disponíveis no hub do modelo de face abraça. Obrigado abraçando o rosto por fornecer esta infraestrutura incrível !!
Também incluímos o ponto de verificação do TensorFlow original em cada modelo no hub.
| Nome do hub de modelo | Ponto de verificação (etapa) |
|---|---|
electra-base-gc4-64k-0-cased-discriminator - electra-base-gc4-64k-0-cased-generator | 0 (inicial) |
electra-base-gc4-64k-100000-cased-discriminator - electra-base-gc4-64k-100000-cased-generator | 100.000 etapas |
electra-base-gc4-64k-200000-cased-discriminator - electra-base-gc4-64k-200000-cased-generator | 200.000 etapas |
electra-base-gc4-64k-300000-cased-discriminator - electra-base-gc4-64k-300000-cased-generator | 300.000 etapas |
electra-base-gc4-64k-400000-cased-discriminator - electra-base-gc4-64k-400000-cased-generator | 400.000 etapas |
electra-base-gc4-64k-500000-cased-discriminator - electra-base-gc4-64k-500000-cased-generator | 500.000 etapas |
electra-base-gc4-64k-600000-cased-discriminator - electra-base-gc4-64k-600000-cased-generator | 600.000 etapas |
electra-base-gc4-64k-700000-cased-discriminator - electra-base-gc4-64k-700000-cased-generator | 700.000 etapas |
electra-base-gc4-64k-800000-cased-discriminator - electra-base-gc4-64k-800000-cased-generator | 800.000 etapas |
electra-base-gc4-64k-900000-cased-discriminator - electra-base-gc4-64k-900000-cased-generator | 900.000 etapas |
electra-base-gc4-64k-1000000-cased-discriminator - electra-base-gc4-64k-1000000-cased-generator | 1m etapas |
Aviso : você deve usar os modelos geradores para tarefas MLM, como previsão de token mascarada. Os modelos discriminadores devem ser usados para ajustar finos em tarefas a jusante como NER, marcação de POS, classificação de texto e muito mais.
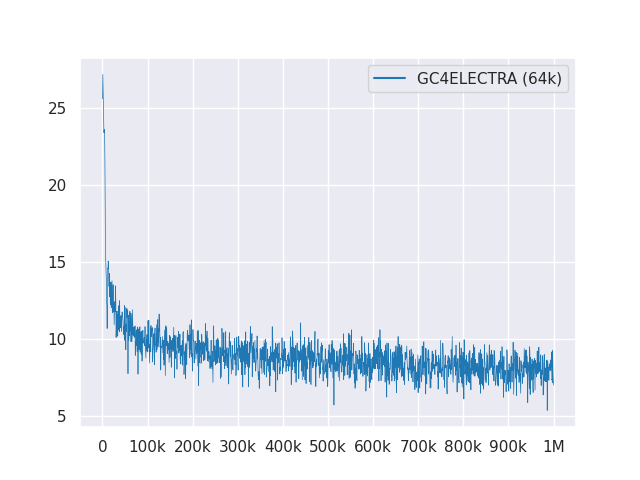
O gráfico a seguir mostra a curva de perda mais de 1 milhão de etapas:
Todos os modelos são licenciados no MIT.
Use as novas discussões do Github para obter feedback ou apenas preencha um PR para sugestões/correções.
Graças a Philip May, Philipp Reißel e a [iisys] (o Institute of Information Systems Hof University) por lançar e sediar o "colossal alemão, limpo corpus de rastreamento comum" (GC4).
Pesquisas suportadas com TPUs em nuvem da Cloud de pesquisa Tensorflow do Google (TFRC). Obrigado por fornecer acesso ao TFRC ❤️
Graças ao apoio generoso da equipe do Hugging Face, é possível armazenar e baixar todos os pontos de verificação do hub de modelo?


