gc4lm
1.0.0
Este repositorio presenta un modelo de idioma colosal (y sesgado) para alemán capacitado en el recientemente lanzado "Corpus de Crawl Common Crawl" recientemente lanzado "(GC4), con un tamaño total del conjunto de datos de ~ 844GB.
Descargo de responsabilidad : los modelos de lenguaje presentados y capacitados en este repositorio son para fines solo para investigaciones . El Corpus GC4, que se usó para el entrenamiento, contiene textos rastreados de Internet. Por lo tanto, los modelos de lenguaje pueden considerarse altamente sesgados, lo que resulta en un modelo que codifica asociaciones estereotipadas a lo largo del estado de género, raza, etnia y discapacidad. Antes de usar y trabajar con los puntos de control lanzados, se recomienda leer:
Sobre los peligros de los loros estocásticos: ¿pueden los modelos de lenguaje ser demasiado grandes?
de Emily M. Bender, Timnit Gebru, Angelina McMillan-Major y Shmargaret Shmitchell.
El objetivo de los puntos de control publicados es impulsar la investigación sobre grandes modelos de idiomas previamente capacitados para alemán, especialmente para identificar sesgos y cómo prevenirlos, ya que la mayoría de la investigación se realiza actualmente solo para inglés.
Utilice la nueva función de discusiones de GitHub para discutir o presentar más preguntas de investigación. ¿No dudes en usar #gc4lm en Twitter?
Después de descargar las partes HEAD y MIDDLE completa del GC4, extraemos los archivos descargados y extraemos el contenido sin procesar (incluido el filtrado de puntaje de lenguaje) con el GIST proporcionado del equipo GC4.
En otro script de preprocesamiento realizamos la división de oraciones de todo el corpus de pre-entrenamiento. Una de las soluciones más rápidas es usar NLTK (con el modelo alemán) en lugar de usar EG Spacy.
Después de la extracción, el filtrado de la puntuación del lenguaje y la división de oraciones, el tamaño del conjunto de datos resultante es 844 GB .
Después de la frase, el siguiente paso es crear un vocabulario electra-compatible, que se describe en la siguiente sección.
El flujo de trabajo de la generación de vocabulario se inspira principalmente en una publicación de blog de Judit ács sobre "Explorar el vocabulario de Bert" y un artículo recientemente lanzado "¿Qué tan bueno es tu tokenizer?" de Phillip Rust, Jonas Pfeiffer, Ivan Vulić, Sebastian Ruder e Iryna Gurevych.
Nos centramos principalmente en calcular la fertilidad de la subvención en los datos de capacitación y desarrollo para tareas populares aguas abajo, como el reconocimiento de entidades nombrado (NER), el etiquetado POS y la clasificación de texto. Para ese propósito, utilizamos los datos de capacitación y desarrollo tokenizados de:
y calcule la fertilidad de la subvención y la parte de las palabras desconocidas (sub) para varios modelos de idiomas alemanes liberados:
| Nombre del modelo | Fertilidad de la subvención | UNK porción |
|---|---|---|
bert-base-german-cased | 1.4433 | 0.0083% |
bert-base-german-dbmdz-cased | 1.4070 | 0.0050% |
| Este trabajo (32k) | 1.3955 | 0.0011% |
| Este trabajo (64k) | 1.3050 | 0.0011% |
Luego decidimos crear un nuevo vocabulario basado en la HEAD y las partes MIDDLE de GC4. Seleccionamos los siguientes archivos para generar un nuevo vocabulario en:
0000_2015-48 (desde HEAD , 2.5GB)0004_2016-44 (desde HEAD , 2.1GB) y 0006_2016-44 (desde MIDDLE , 861 MB)0003_2017-30 (desde HEAD , 2.4GB) y 0007_2017-51 (desde MIDDLE , 1.1GB)0007_2018-30 (desde HEAD , 409mb) y 0007_2018-51 (desde MIDDLE , 4.9gb)0006_2019-09 (desde HEAD , 1.8GB) y 0008_2019-30 (desde MIDDLE , 2.2GB)0003_2020-10 (desde HEAD , 4.5GB) y 0007_2020-10 (desde MIDDLE , 4.0GB)Esto da como resultado un corpus con un tamaño de 27 GB que se usa para la generación de vocabulario.
Decidimos generar vocabularios de 32k y 64k, utilizando la impresionante biblioteca de tokenizadores faciales.
El primer modelo de lenguaje previamente capacitado en el corpus GC4 es un modelo basado en Electra: GC4Electra . Fue entrenado con los mismos parámetros que el modelo de electra turco en una TPU V3-32. Utiliza el vocabulario 64K (el modelo 32K está entrenando actualmente).
AVISO : No lanzamos un modelo. En cambio, lanzamos todos los puntos de control modelo (con un ancho de paso de 100k), para obtener más posibilidades de investigación.
Los siguientes puntos de control están disponibles en el Hub Model de la cara abrazada. ¡Gracias abrazar la cara por proporcionar esta increíble infraestructura!
También incluimos el punto de control TensorFlow original en cada modelo en el cubo.
| Nombre del centro de modelos | Punto de control (paso) |
|---|---|
electra-base-gc4-64k-0-cased-discriminator - electra-base-gc4-64k-0-cased-generator | 0 (inicial) |
electra-base-gc4-64k-100000-cased-discriminator - electra-base-gc4-64k-100000-cased-generator | 100,000 pasos |
electra-base-gc4-64k-200000-cased-discriminator electra-base-gc4-64k-200000-cased-generator | 200,000 pasos |
electra-base-gc4-64k-300000-cased-discriminator - electra-base-gc4-64k-300000-cased-generator | 300,000 pasos |
electra-base-gc4-64k-400000-cased-discriminator - electra-base-gc4-64k-400000-cased-generator | 400,000 pasos |
electra-base-gc4-64k-500000-cased-discriminator - electra-base-gc4-64k-500000-cased-generator | 500,000 pasos |
electra-base-gc4-64k-600000-cased-discriminator - electra-base-gc4-64k-600000-cased-generator | 600,000 pasos |
electra-base-gc4-64k-700000-cased-discriminator - electra-base-gc4-64k-700000-cased-generator | 700,000 pasos |
electra-base-gc4-64k-800000-cased-discriminator - electra-base-gc4-64k-800000-cased-generator | 800,000 pasos |
electra-base-gc4-64k-900000-cased-discriminator - electra-base-gc4-64k-900000-cased-generator | 900,000 pasos |
electra-base-gc4-64k-1000000-cased-discriminator - electra-base-gc4-64k-1000000-cased-generator | 1M pasos |
Aviso : debe usar los modelos de generador para tareas MLM como la predicción de token enmascarado. Los modelos discriminadores deben usarse para ajustar las tareas aguas abajo como NER, etiquetado POS, clasificación de texto y muchos más.
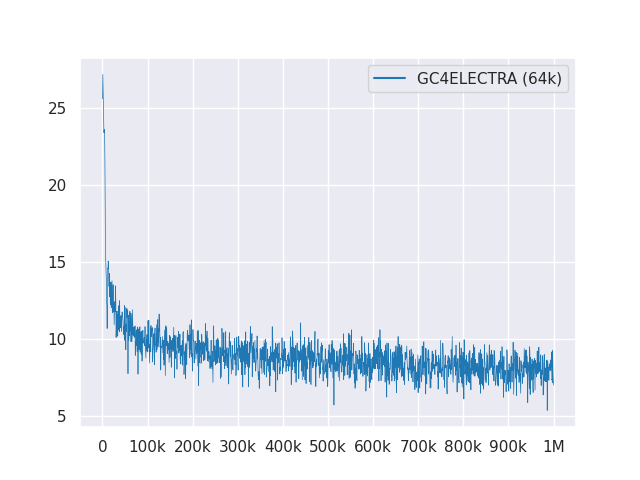
La siguiente trama muestra la curva de pérdida en 1 m pasos:
Todos los modelos tienen licencia bajo MIT.
Utilice las nuevas discusiones de GitHub para recibir comentarios o simplemente llene un PR para sugerencias/correcciones.
Gracias a Philip May, Philipp Reißel y a [IISYS] (la Universidad del Instituto de Sistemas de Información HOF) por liberar y organizar el "Colosal alemán, Corpus de Crawl Common Crawl" (GC4).
Investigación respaldada con TPUS de la nube de TensorFlow Research Cloud (TFRC) de Google. Gracias por proporcionar acceso al TFRC ❤️
Gracias al generoso apoyo del equipo de abrazaderas, ¿es posible almacenar y descargar todos los puntos de control desde su Model Hub?


