gc4lm
1.0.0
このリポジトリは、最近リリースされた「ドイツのコロッサル、クリーンな一般的なクロールコーパス」(GC4)で訓練されたドイツ語の巨大な(および偏った)言語モデルを提示し、合計データセットサイズは〜844GBです。
免責事項:このリポジトリで提示された訓練された言語モデルは、研究のみを目的としています。トレーニングに使用されたGC4コーパスには、インターネットからのrawいテキストが含まれています。したがって、言語モデルは非常に偏っていると見なすことができ、その結果、性別、人種、民族性、障害の状態に沿ったステレオタイプの関連性をコードするモデルになります。リリースされたチェックポイントを使用して作業する前に、読むことを強くお勧めします。
確率的オウムの危険性について:言語モデルは大きすぎることができますか?
エミリー・M・ベンダー、ティムニット・ゲブル、アンジェリーナ・マクミラン・マジャール、シュマーガレット・シュミッチェルから。
リリースされたチェックポイントの目的は、ほとんどの研究が現在英語のみで行われているため、特にバイアスとそれらを防ぐ方法を特定するために、ドイツ語の大規模な事前訓練を受けた言語モデルの研究を強化することです。
さらなる研究の質問について議論または提示するために、新しいGitHubディスカッション機能を使用してください。 Twitterで#gc4lm自由に使用してください。
GC4の完全なHEADとMIDDLE部をダウンロードした後、ダウンロードしたアーカイブを抽出し、GC4チームから提供されたGISTで生のコンテンツ(言語スコアフィルタリングを含む)を抽出します。
別の前処理スクリプトでは、トレーニング前のコーパス全体の文節を実行します。最速のソリューションの1つは、SPACYを使用する代わりに、NLTK(ドイツモデルを使用)を使用することです。
抽出後、言語スコアのフィルタリング、および文の分割後、結果のデータセットサイズは844GBです。
次のステップは、次のセクションで説明されているエレクトラ互換のボカブを作成することです。
語彙生成ワークフローは、主に「バートの語彙の探索」と最近リリースされた論文「トークンザーはどれくらい良いですか?」フィリップ・ラスト、ジョナス・ファイファー、イヴァン・ヴィリッチ、セバスチャン・ルーダー、イリーナ・グレビッチから。
主に、名前付きエンティティ認識(NER)、POSタグ付け、テキスト分類などの一般的なダウンストリームタスクのトレーニングと開発データのサブワードの肥沃度の計算に焦点を当てています。そのために、次の目的でトークン化されたトレーニングと開発データを使用します。
さまざまなリリースされたドイツ語モデルのサブワードの肥沃度と未知の(サブ)単語の一部を計算します。
| モデル名 | サブワードの肥沃度 | UNK部分 |
|---|---|---|
bert-base-german-cased | 1.4433 | 0.0083% |
bert-base-german-dbmdz-cased | 1.4070 | 0.0050% |
| この作業(32K) | 1.3955 | 0.0011% |
| この作業(64K) | 1.3050 | 0.0011% |
次に、GC4のHEADとMIDDLE部に基づいて新しい語彙を作成することにしました。以下のアーカイブを選択して、新しい音声を生成します。
0000_2015-48 ( HEADから、2.5GB)0004_2016-44 ( HEADから、2.1GB)および0006_2016-44 ( MIDDLEから、861MB)0003_2017-30 ( HEADから、2.4GB)および0007_2017-51 ( MIDDLEから、1.1GB)0007_2018-30 ( HEADから、409MBから)および0007_2018-51 ( MIDDLEから、4.9GB)0006_2019-09 ( HEADから、1.8GB)および0008_2019-30 ( MIDDLEから、2.2GB)0003_2020-10 ( HEADから、4.5GB)および0007_2020-10 ( MIDDLEから、4.0GB)これにより、音声生成に使用される27GBのサイズのコーパスになります。
Awesome Hugging Face Tokenizers Libraryを使用して、32Kと64Kサイズの語彙の両方を生成することにしました。
GC4コーパスの最初の大規模な訓練を受けた言語モデルは、エレクトラベースのモデルであるGC4Electraです。 V3-32 TPUでトルコのエレクトラモデルと同じパラメーターで訓練されました。 64Kの語彙を使用しています(32Kモデルが現在トレーニングです)。
注意: 1つのモデルをリリースしません。代わりに、より多くの研究の可能性を得るために、すべてのモデルチェックポイント(100Kステップ幅で)をリリースします。
次のチェックポイントは、ハグするフェイスモデルハブから入手できます。この素晴らしいインフラストラクチャを提供してくれた顔を抱き締めてくれてありがとう!
また、ハブ上の各モデルに元のTensorflowチェックポイントも含めます。
| モデルハブ名 | チェックポイント(ステップ) |
|---|---|
electra-base-gc4-64k-0-cased-discriminator - electra-base-gc4-64k-0-cased-generator | 0(初期) |
electra-base-gc4-64k-100000-cased-discriminator -Electra electra-base-gc4-64k-100000-cased-generator | 100,000ステップ |
electra-base-gc4-64k-200000-cased-discriminator - electra-base-gc4-64k-200000-cased-generator | 200,000ステップ |
electra-base-gc4-64k-300000-cased-discriminator -Electra electra-base-gc4-64k-300000-cased-generator | 300,000ステップ |
electra-base-gc4-64k-400000-cased-discriminator -Electra electra-base-gc4-64k-400000-cased-generator | 400,000ステップ |
electra-base-gc4-64k-500000-cased-discriminator -Electra electra-base-gc4-64k-500000-cased-generator | 500,000ステップ |
electra-base-gc4-64k-600000-cased-discriminator -Electra electra-base-gc4-64k-600000-cased-generator | 600,000ステップ |
electra-base-gc4-64k-700000-cased-discriminator -Electra electra-base-gc4-64k-700000-cased-generator | 700,000ステップ |
electra-base-gc4-64k-800000-cased-discriminator -Electra electra-base-gc4-64k-800000-cased-generator | 800,000ステップ |
electra-base-gc4-64k-900000-cased-discriminator -Electra electra-base-gc4-64k-900000-cased-generator | 900,000ステップ |
electra-base-gc4-64k-1000000-cased-discriminator -Electra electra-base-gc4-64k-1000000-cased-generator | 1Mステップ |
注意:マスクされたトークン予測などのMLMタスクには、ジェネレーターモデルを使用する必要があります。識別子モデルは、NER、POSタグ付け、テキストの古いなどの下流タスクで微調整するために使用する必要があります。
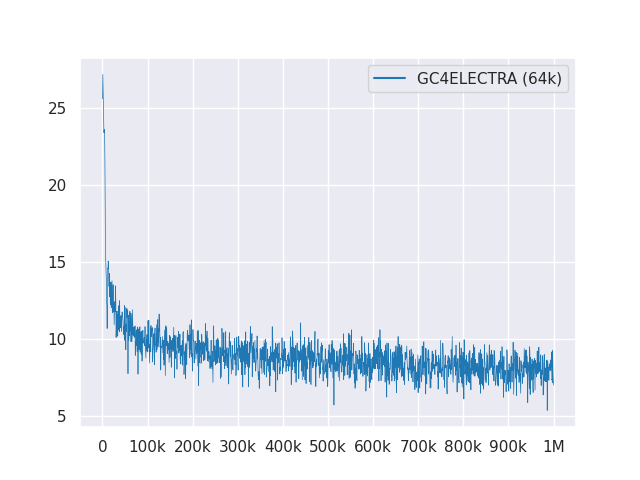
次のプロットは、1mのステップを超える損失曲線を示しています。
すべてのモデルはMITの下でライセンスされています。
フィードバックのために新しいGitHubディスカッションを使用するか、提案/修正のためにPRを記入してください。
フィリップ・メイ、フィリップ・レイエル、および[ISISS](Instruction Systems HOF University)に感謝します。
GoogleのTensorflow Research Cloud(TFRC)のクラウドTPUでサポートされている研究。 TFRCのアクセスを提供していただきありがとうございます
抱き合っているフェイスチームからの寛大なサポートのおかげで、モデルハブからすべてのチェックポイントを保存およびダウンロードすることができますか?


