gc4lm
1.0.0
يقدم هذا المستودع نموذجًا لغويًا هائلًا (ومنحازًا) للألمانية المدربة على "مجموعة German Aldossal ، Clian Crawl Corra" (GC4) التي تم إصدارها مؤخرًا ، حيث يبلغ حجم مجموعة البيانات الإجمالية حوالي 844 جيجا بايت.
إخلاء المسئولية : نماذج اللغة المقدمة والمدربة في هذا المستودع هي لأغراض البحث فقط . يحتوي GC4 Corpus - الذي تم استخدامه للتدريب - على نصوص زحف من الإنترنت. وبالتالي ، يمكن اعتبار نماذج اللغة منحازة للغاية ، مما يؤدي إلى نموذج يشفر الارتباطات النمطية على طول الجنس والعرق والعرق وحالة الإعاقة. قبل استخدام نقاط التفتيش التي تم إصدارها والعمل عليها ، يوصى بشدة بقراءة:
على مخاطر الببغاوات العشوائية: هل يمكن أن تكون نماذج اللغة كبيرة جدًا؟
من Emily M. Bender و Timnit Gebru و Angelina McMillan-Major و Shmargaret Shmitchell.
يتمثل الهدف من نقاط التفتيش التي تم إصدارها في تعزيز الأبحاث حول نماذج اللغة الكبيرة التي تم تدريبها للألمانية ، وخاصة لتحديد التحيزات وكيفية منعها ، حيث تتم معظم الأبحاث حاليًا للغة الإنجليزية فقط.
يرجى استخدام ميزة مناقشات GitHub الجديدة من أجل مناقشة أو تقديم المزيد من الأسئلة البحثية. لا تتردد في استخدام #gc4lm على Twitter؟.
بعد تنزيل الأجزاء الكاملة HEAD من GC4 ، نقوم باستخراج المحفوظات التي MIDDLE تنزيلها واستخراج المحتوى الخام (بما في ذلك تصفية نقاط اللغة) مع GIST المقدمة من فريق GC4.
في برنامج آخر للمعالجة المسبقة ، نقوم بإجراء تقسيم الجملة لجسم ما قبل التدريب بأكمله. أحد أسرع الحلول هو استخدام NLTK (مع النموذج الألماني) بدلاً من استخدام EG Spacy.
بعد الاستخراج ، تصفية درجة اللغة وتقسيم الجملة ، يبلغ حجم مجموعة البيانات الناتجة 844 جيجابايت .
بعد تقسيم الجملة ، فإن الخطوة التالية هي إنشاء مفردات متوافقة مع Electra ، الموصوفة في القسم التالي.
يعمل سير عمل Generation بشكل أساسي من خلال منشور مدونة من Judit ács حول "استكشاف مفردات Bert" وورقة تم إصدارها مؤخرًا "ما مدى جودة Tokenizer؟" من Phillip Rust ، Jonas Pfeiffer ، Ivan Vulić ، Sebastian Ruder و Iryna Gurevych.
نركز بشكل أساسي على حساب خصوبة الكلمات الفرعية على بيانات التدريب والتطوير لمهام المصب الشهيرة مثل التعرف على الكيان المسماة (NER) ، وضع علامات POS وتصنيف النص. لهذا الغرض ، نستخدم بيانات التدريب والتطوير المميز من:
وحساب خصوبة الكلمة الفرعية وجزء من الكلمات غير المعروفة (الفرعية) لمختلف نماذج اللغة الألمانية التي تم إصدارها:
| اسم النموذج | خصوبة الكلمة الفرعية | جزء UNK |
|---|---|---|
bert-base-german-cased | 1.4433 | 0.0083 ٪ |
bert-base-german-dbmdz-cased | 1.4070 | 0.0050 ٪ |
| هذا العمل (32 كيلو) | 1.3955 | 0.0011 ٪ |
| هذا العمل (64 كيلو) | 1.3050 | 0.0011 ٪ |
ثم قررنا إنشاء مفردات جديدة تعتمد على HEAD والأجزاء MIDDLE من GC4. نختار المحفوظات التالية لإنشاء مفردات جديدة على:
0000_2015-48 (من HEAD ، 2.5 جيجابايت)0004_2016-44 (من HEAD ، 2.1 جيجابايت) و 0006_2016-44 (من MIDDLE ، 861 ميجابايت)0003_2017-30 (من HEAD ، 2.4 جيجابايت) و 0007_2017-51 (من MIDDLE ، 1.1 جيجابايت)0007_2018-30 (من HEAD ، 409 ميجابايت) و 0007_2018-51 (من MIDDLE ، 4.9 جيجابايت)0006_2019-09 (من HEAD ، 1.8 جيجابايت) و 0008_2019-30 (من MIDDLE ، 2.2 جيجابايت)0003_2020-10 (من HEAD ، 4.5 جيجابايت) و 0007_2020-10 (من MIDDLE ، 4.0 جيجابايت)ينتج عن هذا مجموعة بحجم 27 جيجابايت تستخدم لتوليد المفردات.
قررنا توليد كل من المفردات بحجم 32 ألف و 64 كيلو بايت ، باستخدام مكتبة الرمز المميزات الوجه الرائعة.
أول نموذج لغوي كبير مدرب مسبقًا على GC4 Corpus هو نموذج قائم على Electra: GC4Electra . تم تدريبه مع نفس المعلمات مثل نموذج Electra التركي على V3-32 TPU. ويستخدم المفردات 64k (نموذج 32K يتدرب حاليًا).
إشعار : نحن لا ننشر نموذجًا واحدًا . بدلاً من ذلك ، نقوم بإصدار جميع نقاط التفتيش النموذجية (مع عرض خطوة 100 ألف) ، لمزيد من إمكانيات البحث.
تتوفر نقاط التفتيش التالية من محور طراز الوجه المعانقة. شكرا معانقة وجه لتوفير هذه البنية التحتية المذهلة !!
ندرج أيضًا نقطة تفتيش TensorFlow الأصلية في كل طراز على المحور.
| نموذج المحور | نقطة تفتيش (خطوة) |
|---|---|
electra-base-gc4-64k-0-cased-discriminator - electra-base-gc4-64k-0-cased-generator | 0 (أولي) |
electra-base-gc4-64k-100000-cased-discriminator - electra-base-gc4-64k-100000-cased-generator | 100000 خطوة |
electra-base-gc4-64k-200000-cased-discriminator - electra-base-gc4-64k-200000-cased-generator | 200000 خطوة |
electra-base-gc4-64k-300000-cased-discriminator - electra-base-gc4-64k-300000-cased-generator | 300000 خطوة |
electra-base-gc4-64k-400000-cased-discriminator - electra-base-gc4-64k-400000-cased-generator | 400000 خطوة |
electra-base-gc4-64k-500000-cased-discriminator - electra-base-gc4-64k-500000-cased-generator | 500000 خطوة |
electra-base-gc4-64k-600000-cased-discriminator - electra-base-gc4-64k-600000-cased-generator | 600000 خطوة |
electra-base-gc4-64k-700000-cased-discriminator - electra-base-gc4-64k-700000-cased-generator | 700000 خطوة |
electra-base-gc4-64k-800000-cased-discriminator - electra-base-gc4-64k-800000-cased-generator | 800000 خطوة |
electra-base-gc4-64k-900000-cased-discriminator - electra-base-gc4-64k-900000-cased-generator | 900000 خطوة |
electra-base-gc4-64k-1000000-cased-discriminator - electra-base-gc4-64k-1000000-cased-generator | خطوات 1M |
إشعار : يجب عليك استخدام نماذج المولد لمهام MLM مثل التنبؤ الرمزي المقنع. يجب استخدام نماذج التمييز للضبط في مهام المصب مثل NER ، وعلم نقاط البيع ، وكلاسيات النص وغيرها الكثير.
تُظهر المؤامرة التالية منحنى الخسارة أكثر من مليون خطوة:
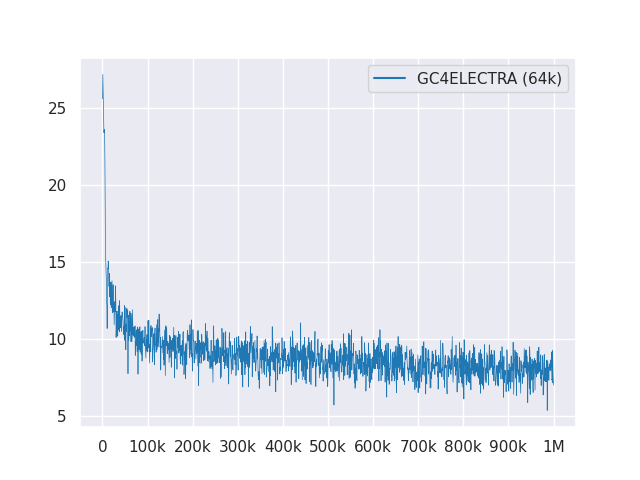
جميع النماذج مرخصة تحت معهد ماساتشوستس للتكنولوجيا.
يرجى استخدام مناقشات جيثب الجديدة للتعليقات أو مجرد ملء العلاقات العامة للاقتراحات/التصحيحات.
بفضل Philip May ، Philipp Reißel و [Iisys] (معهد أنظمة المعلومات HOF) لإصدار واستضافة "Corra Grows Class Cropus الألمانية" (GC4).
الأبحاث المدعومة بـ Cloud TPUs من Cloud TensorFlow Research من Google (TFRC). شكرا لتوفير الوصول إلى TFRC ❤
بفضل الدعم السخي من فريق Hugging Face ، من الممكن تخزين وتنزيل جميع نقاط التفتيش من محور الطراز الخاص بهم؟


