gc4lm
1.0.0
Ce référentiel présente un modèle linguistique colossal (et biaisé) pour l'allemand formé sur le "Corpus de Crawl Common Germossal et Clean Common" récemment publié (GC4), avec une taille totale d'ensemble de données de ~ 844 Go.
Avertissement : Les modèles de langage présentés et formés dans ce référentiel sont à des fins de recherche uniquement . Le GC4 Corpus - qui a été utilisé pour la formation - contient des textes rampants sur Internet. Ainsi, les modèles linguistiques peuvent être considérés comme très biaisés, résultant en un modèle qui code pour les associations stéréotypées le long du genre, de la race, de l'ethnicité et du statut d'invalidité. Avant d'utiliser et de travailler avec les points de contrôle publiés, il est fortement recommandé de lire:
Sur les dangers des perroquets stochastiques: les modèles de langue peuvent-ils être trop importants?
d'Emily M. Bender, Timnit Gebru, Angelina McMillan-Major et Shmargaret Shmitchell.
L'objectif des points de contrôle publiés est de stimuler la recherche sur les grands modèles de langue pré-formés pour l'allemand, en particulier pour l'identification des biais et comment les empêcher, car la plupart des recherches sont actuellement effectuées pour l'anglais uniquement.
Veuillez utiliser la nouvelle fonctionnalité de discussions GitHub afin de discuter ou de présenter d'autres questions de recherche. N'hésitez pas à utiliser #gc4lm sur Twitter ?.
Après avoir téléchargé la HEAD complète et les parties MIDDLE du GC4, nous extraissons les archives téléchargées et extrons le contenu brut (incl. Le filtrage des scores de langage) avec l'essentiel fourni de l'équipe GC4.
Dans un autre script de prétraitement, nous effectuons des phrases de l'ensemble du corpus pré-formation. L'une des solutions les plus rapides consiste à utiliser NLTK (avec le modèle allemand) au lieu d'utiliser EG Spacy.
Après extraction, filtrage du score linguistique et division des phrases, la taille de l'ensemble de données résultant est de 844 Go .
Après la dépistage de la phrase, l'étape suivante consiste à créer un vocabulaire compatible électra, qui est décrit dans la section suivante.
Le flux de travail de génération de vocabs est principalement inspiré par un article de blog de Judit Ács sur "Explorer le vocabulaire de Bert" et un article récemment publié "How Good Your Tokenizer?" De Phillip Rust, Jonas Pfeiffer, Ivan Vullić, Sebastian Ruder et Iryna Gurevych.
Nous nous concentrons principalement sur le calcul de la fertilité des sous-mots sur les données de formation et de développement pour les tâches populaires en aval telles que la reconnaissance de l'entité nommée (NER), le taggage POS et la classification du texte. À cette fin, nous utilisons les données de formation et de développement à tokenisés de:
et calculer la fertilité en sous-mots et la partie des mots inconnus (sub) pour divers modèles de langue allemande publiés:
| Nom du modèle | Fertilité des sous-mots | Portion UNK |
|---|---|---|
bert-base-german-cased | 1.4433 | 0,0083% |
bert-base-german-dbmdz-cased | 1.4070 | 0,0050% |
| Ce travail (32k) | 1.3955 | 0,0011% |
| Ce travail (64k) | 1.3050 | 0,0011% |
Nous avons ensuite décidé de créer un nouveau vocabulaire basé sur la HEAD et les parties MIDDLE de GC4. Nous sélectionnons les archives suivantes pour générer un nouveau vocabulaire sur:
0000_2015-48 (de HEAD , 2,5 Go)0004_2016-44 (de HEAD , 2,1 Go) et 0006_2016-44 (à partir MIDDLE , 861 Mo)0003_2017-30 (de HEAD , 2,4 Go) et 0007_2017-51 (à partir MIDDLE , 1,1 Go)0007_2018-30 (de HEAD , 409 Mo) et 0007_2018-51 (à partir MIDDLE , 4,9 Go)0006_2019-09 (de HEAD , 1,8 Go) et 0008_2019-30 (à partir MIDDLE , 2,2 Go)0003_2020-10 (de HEAD , 4,5 Go) et 0007_2020-10 (à partir MIDDLE , 4,0 Go)Il en résulte un corpus avec une taille de 27 Go qui est utilisé pour la génération de vocabulaire.
Nous avons décidé de générer des vocabulaires de taille 32k et 64k, en utilisant la bibliothèque de tokenistes Face Awesome Hugging Face.
Le premier grand modèle de langage pré-formé sur le corpus GC4 est un modèle à base d'électra: GC4Electra . Il a été formé avec les mêmes paramètres que le modèle Electra turc sur un V3-32 TPU. Il utilise le vocabulaire 64K (le modèle 32K est actuellement en formation).
AVIS : Nous ne publions pas un modèle. Au lieu de cela, nous publions tous les points de contrôle du modèle (avec une largeur de 100 000 à pas), pour plus de possibilités de recherche.
Les points de contrôle suivants sont disponibles à partir du HUB Model Hubing Face. Merci étreignant le visage d'avoir fourni cette infrastructure incroyable !!
Nous incluons également le point de contrôle TensorFlow d'origine dans chaque modèle du Hub.
| Nom du hub modèle | Point de contrôle (étape) |
|---|---|
electra-base-gc4-64k-0-cased-discriminator - electra-base-gc4-64k-0-cased-generator | 0 (initial) |
electra-base-gc4-64k-100000-cased-discriminator - electra-base-gc4-64k-100000-cased-generator | 100 000 étapes |
electra-base-gc4-64k-200000-cased-discriminator - electra-base-gc4-64k-200000-cased-generator | 200 000 étapes |
electra-base-gc4-64k-300000-cased-discriminator - electra-base-gc4-64k-300000-cased-generator | 300 000 étapes |
electra-base-gc4-64k-400000-cased-discriminator - electra-base-gc4-64k-400000-cased-generator | 400 000 étapes |
electra-base-gc4-64k-500000-cased-discriminator - electra-base-gc4-64k-500000-cased-generator | 500 000 étapes |
electra-base-gc4-64k-600000-cased-discriminator - electra-base-gc4-64k-600000-cased-generator | 600 000 étapes |
electra-base-gc4-64k-700000-cased-discriminator - electra-base-gc4-64k-700000-cased-generator | 700 000 étapes |
electra-base-gc4-64k-800000-cased-discriminator - electra-base-gc4-64k-800000-cased-generator | 800 000 étapes |
electra-base-gc4-64k-900000-cased-discriminator - electra-base-gc4-64k-900000-cased-generator | 900 000 étapes |
electra-base-gc4-64k-1000000-cased-discriminator - electra-base-gc4-64k-1000000-cased-generator | Étapes 1m |
AVIS : Vous devez utiliser les modèles de générateurs pour les tâches MLM comme la prédiction de jeton masquée. Les modèles de discriminator doivent être utilisés pour le réglage fin sur les tâches en aval comme le NER, le marquage POS, la classification du texte et bien d'autres.
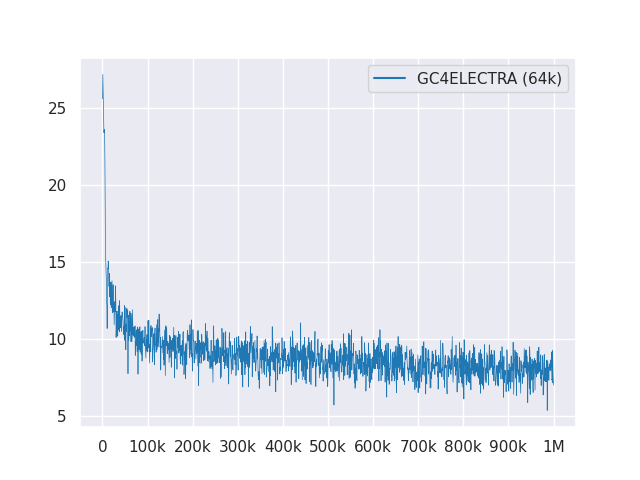
Le tracé suivant montre la courbe de perte sur les étapes de 1 m:
Tous les modèles sont sous licence dans le MIT.
Veuillez utiliser les nouvelles discussions GitHub pour les commentaires ou remplissez simplement un RP pour les suggestions / corrections.
Merci à Philip May, Philipp Reißel et à [Iisys] (l'Institut des systèmes d'information Hof University) pour avoir publié et accueilli le "Corpus de Crawl commun colossal allemand" (GC4).
La recherche est soutenue avec les TPU cloud du cloud de recherche Tensorflow de Google (TFRC). Merci d'avoir donné accès au TFRC ❤️
Grâce au support généreux de l'équipe Hugging Face, il est possible de stocker et de télécharger tous les points de contrôle de leur hub modèle?


