DePT
1.0.0
該存儲庫提供了標題為“ Dept:分解的及時調整”的論文代碼,以進行參數有效調整,從而使我們的代碼貢獻集成到其他項目中。
MODEL設置為您本地的Llama-2路徑以運行實驗。您可以重現我們論文部的實驗:分解的及時調整以進行參數有效調整。
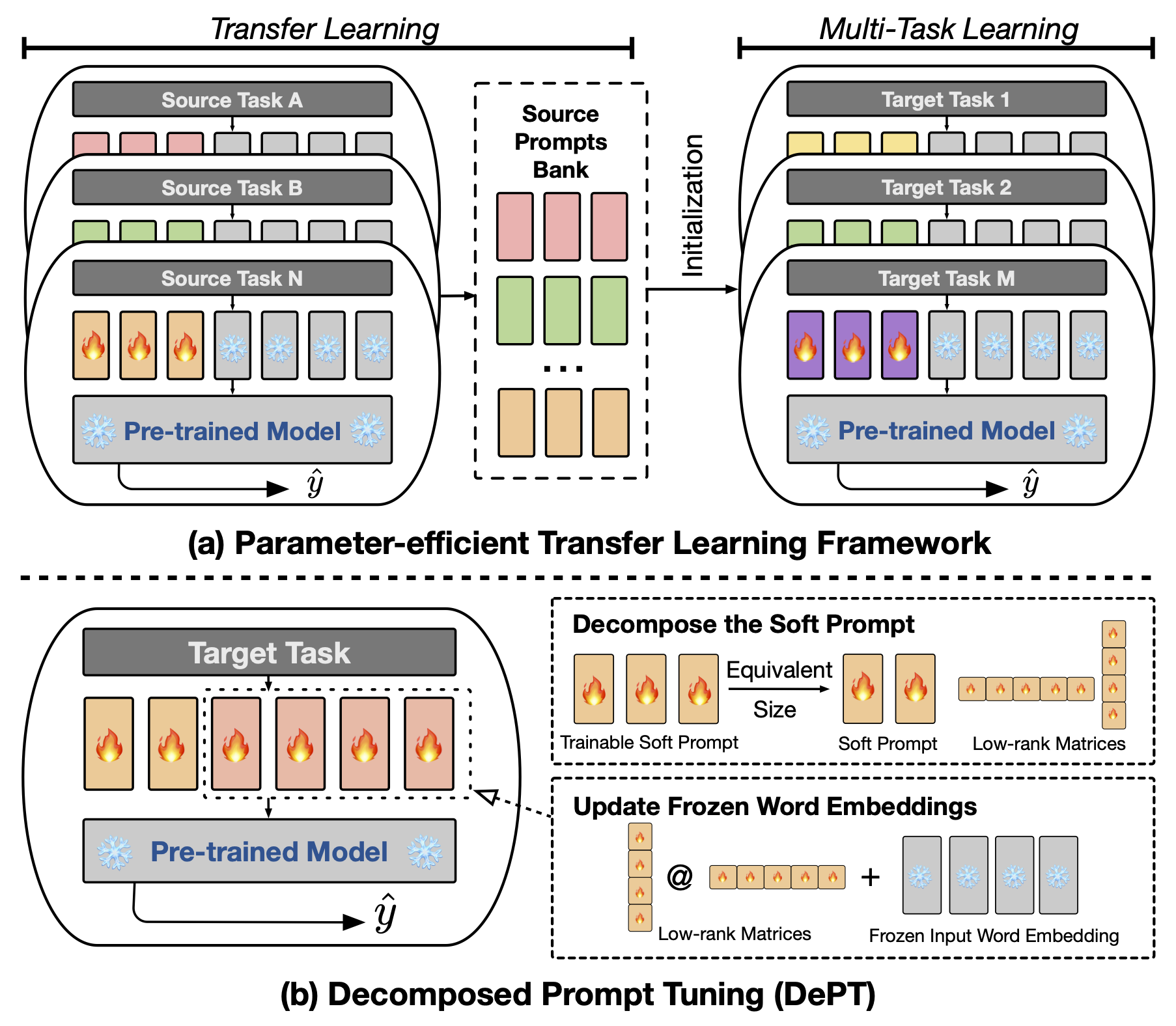
抽象提示調整(PT),其中少量可訓練的軟(連續)提示向量固定在語言模型的輸入中,它顯示了各種任務和模型的有希望的結果,用於參數有效的微調(PEFT)。 PT從其他PEFT方法中脫穎而出,因為它以更少的可訓練參數保持競爭性能,並且隨著模型大小的擴展,它不會大大擴展其參數。但是,PT引入了額外的軟提示令牌,導致輸入序列更長,這顯著影響訓練,推理時間和記憶使用,這是由於變壓器的二次復雜性。特別是針對每日大量查詢的大型語言模型(LLM)。為了解決這個問題,我們提出了分解的提示調整(DEPT),將軟提示分解為較短的軟提示和一對低級矩陣,然後通過兩個不同的學習率進行了優化。與Vanilla PT及其變體相比,這使該部門能夠實現更好的性能,同時節省大量的內存和時間成本,而無需更改可訓練的參數尺寸。通過對23種自然語言處理(NLP)和視覺語言(VL)任務進行的廣泛實驗,我們證明在某些情況下,部門的表現優於最先進的PEFT方法,包括完整的微調基線。此外,我們從經驗上表明,隨著模型大小的增加,部門的效率更加有效。我們的進一步研究表明,部門與參數有效的轉移學習無縫地集成在幾個圖中,並突出了其對各種模型體系結構和大小的適應性。
要運行基於及時或基於CLS的微調,您需要安裝以下軟件包。
我們在實驗中使用以下NLP數據集:膠水,Superglue,MRQA 2019共享任務,Winogrande,Yelp-2,Scitail和Paws Wiki。所有這些數據集都在HuggingFace數據集中可用,可以自動下載。有關數據集的詳細信息,請參考文件src/tasks.py 。
我們提供腳本來複製論文中的主要實驗。例如,您可以運行以下腳本來重現膠數據集上的部門的結果。 PREFIX_LENGTH表示紙張中軟提示m的長度。 R代表紙張中低級矩陣r的等級。 lr是軟提示的學習率,而LORA_LR是將添加到冷凍單詞嵌入中的低級矩陣的學習率。
MODEL=t5-base
MAX_LENGTH=256
MAX_STEPS=40000
PREFIX_LENGTH=40
R=45
for TASK_NAME in cola mrpc mnli qnli qqp rte sst2 stsb ; do
for LORA_LR in 5e-3 3e-1 5e-4 ; do
for lr in 3e-1 4e-1 ; do
CUDA_VISIBLE_DEVICES=0 python train.py
--peft_type PROMPT_TUNING_LORA
--lora_embedding_lr ${LORA_LR}
--learning_rate ${lr}
--prefix_length ${PREFIX_LENGTH}
--r ${R}
--task_name ${TASK_NAME}
--dataset_config_name en
--model_name_or_path ${MODEL}
--do_train
--do_eval
--do_predict
--per_device_train_batch_size 32
--per_device_eval_batch_size 32
--max_seq_length ${MAX_LENGTH}
--save_strategy steps
--evaluation_strategy steps
--max_steps ${MAX_STEPS}
--eval_steps 1000
--save_steps 1000
--warmup_steps 500
--weight_decay 1e-5
--load_best_model_at_end
--save_total_limit 1
--output_dir saved_ ${MODEL} / ${TASK_NAME} _lr ${lr} _loralr ${LORA_LR} _pl ${PREFIX_LENGTH} _r ${R} _st ${MAX_STEPS} ;
done ;
done ;
done您可以用superglue-multirc superglue-wic superglue-wsc.fixed superglue-cb superglue-boolq newsqa searchqa hotpotqa nq winogrande yelp_polarity TASK_NAME scitail數據集和PAWS Wiki數據集的paws 。
此外,您可以添加參數--peft_model_id來初始化軟提示,並使用預算的提示向量來初始化柔軟的提示。您可以添加參數--k_shot_examples來指定用於幾次學習的示例數量。
正如我們在論文中引起的那樣,這項工作的潛在局限性之一是引入了用於調整的額外的超參數,例如,低級矩陣的學習率和訓練步驟。這可能會在模型訓練的超參數優化階段引入一些其他計算開銷。搜索所有這些超參數以獲得最佳性能很重要。對於具有100,000多個培訓示例的大型數據集,我們遵循先前的工作(Vu等,2022),以最多300,000步培訓我們提出的方法部門。培訓更多步驟有助於提高大型數據集的性能。隨著軟提示的長度減少,可以進行超參數搜索,這可能需要更多的努力。通常,使用PREFIX_LENGTH的軟提示為40或60 。使用參數有效的轉移學習(PETL)可能有助於減少超參數搜索的努力。但是,重要的是要注意,模型訓練過程是一次性事件,而模型推斷不是。在這種情況下,在推斷期間,部門的效率優勢變得特別有價值。
如果您對代碼或論文有任何疑問,請隨時通過[email protected]與Zhengxiang聯繫。如果您在使用代碼時遇到任何困難或需要報告錯誤,請隨時打開問題。我們請要求您提供有關問題的詳細信息,以幫助我們提供有效的支持。
@inproceedings{shi2024dept,
title={DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning},
author={Zhengxiang Shi and Aldo Lipani},
booktitle={International Conference on Learning Representations},
year={2024},
url={http://arxiv.org/abs/2309.05173}
}
該存儲庫建立在以下存儲庫上:


