DePT
1.0.0
Repositori ini menyediakan kode untuk makalah berjudul Dept: Dekomposisi penyetelan prompt untuk fine-tuning yang efisien parameter , membuat integrasi kontribusi kode kami ke dalam proyek lain lebih mudah diakses.
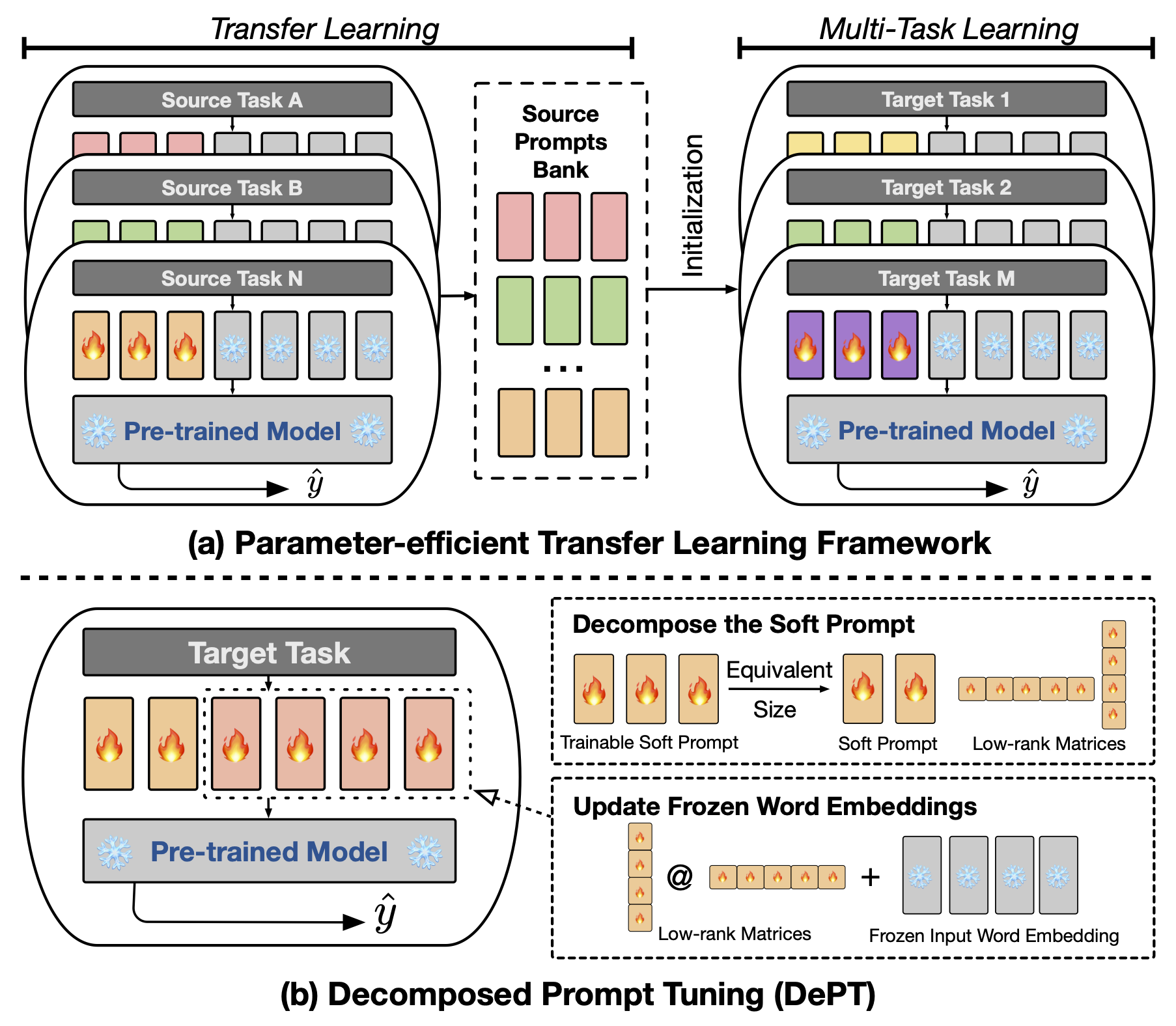
MODEL ke jalur LLAMA-2 lokal Anda untuk menjalankan eksperimen.Anda dapat mereproduksi eksperimen Dept Kertas kami: Tuning cepat yang terurai untuk fine-tuning yang efisien parameter.
Abstrak Prompt Tuning (PT), di mana sejumlah kecil vektor cepat lunak (kontinu) yang dapat dilatih ditempelkan pada input model bahasa (LM), telah menunjukkan hasil yang menjanjikan di berbagai tugas dan model untuk fine-tuning (PEFT) yang efisien parameter. PT menonjol dari pendekatan PEFT lain karena mempertahankan kinerja kompetitif dengan lebih sedikit parameter yang dapat dilatih dan tidak secara drastis meningkatkan parameternya saat ukuran model berkembang. Namun, PT memperkenalkan token prompt lunak tambahan, yang mengarah ke urutan input yang lebih lama, yang secara signifikan berdampak pada pelatihan dan waktu inferensi dan penggunaan memori karena kompleksitas kuadrat transformator. Terutama tentang model bahasa besar (LLM) yang menghadapi permintaan harian yang berat. Untuk mengatasi masalah ini, kami mengusulkan penyetelan prompt yang terurai (Dept), yang menguraikan prompt lunak menjadi prompt lunak yang lebih pendek dan sepasang matriks peringkat rendah yang kemudian dioptimalkan dengan dua tingkat pembelajaran yang berbeda. Ini memungkinkan Dept untuk mencapai kinerja yang lebih baik sambil menghemat biaya memori dan waktu yang substansial dibandingkan dengan vanilla PT dan variannya, tanpa mengubah ukuran parameter yang dapat dilatih. Melalui eksperimen ekstensif pada 23 tugas pemrosesan bahasa alami (NLP) dan visi-bahasa (VL), kami menunjukkan bahwa departemen mengungguli pendekatan PEFT canggih, termasuk baseline fine-tuning penuh, dalam beberapa skenario. Selain itu, kami secara empiris menunjukkan bahwa Dept tumbuh lebih efisien seiring dengan meningkatnya ukuran model. Studi lebih lanjut kami mengungkapkan bahwa Dept mengintegrasikan mulus dengan pembelajaran transfer yang efisien parameter dalam pengaturan pembelajaran beberapa-shot dan menyoroti kemampuan beradaptasi pada berbagai arsitektur dan ukuran model.
Untuk menjalankan fine-tuning berbasis CLS atau CLS, Anda perlu menginstal paket berikut.
Kami menggunakan kumpulan data NLP berikut dalam percobaan kami: Glue, Superglue, MRQA 2019 Tugas Bersama, Winogrande, Yelp-2, Scitail dan Paws-Wiki. Semua set data ini tersedia dalam set data HuggingFace dan dapat diunduh secara otomatis. Silakan merujuk ke file src/tasks.py untuk detail dataset.
Kami menyediakan skrip untuk mereproduksi eksperimen utama dalam makalah kami. Misalnya, Anda dapat menjalankan skrip berikut untuk mereproduksi hasil dept pada dataset lem. PREFIX_LENGTH mewakili panjang prompt lunak m di koran. R mewakili peringkat matriks rendah di r . lr adalah tingkat pembelajaran untuk soft prompt, dan LORA_LR adalah tingkat pembelajaran untuk pasangan matriks peringkat rendah yang akan ditambahkan ke embeddings kata beku.
MODEL=t5-base
MAX_LENGTH=256
MAX_STEPS=40000
PREFIX_LENGTH=40
R=45
for TASK_NAME in cola mrpc mnli qnli qqp rte sst2 stsb ; do
for LORA_LR in 5e-3 3e-1 5e-4 ; do
for lr in 3e-1 4e-1 ; do
CUDA_VISIBLE_DEVICES=0 python train.py
--peft_type PROMPT_TUNING_LORA
--lora_embedding_lr ${LORA_LR}
--learning_rate ${lr}
--prefix_length ${PREFIX_LENGTH}
--r ${R}
--task_name ${TASK_NAME}
--dataset_config_name en
--model_name_or_path ${MODEL}
--do_train
--do_eval
--do_predict
--per_device_train_batch_size 32
--per_device_eval_batch_size 32
--max_seq_length ${MAX_LENGTH}
--save_strategy steps
--evaluation_strategy steps
--max_steps ${MAX_STEPS}
--eval_steps 1000
--save_steps 1000
--warmup_steps 500
--weight_decay 1e-5
--load_best_model_at_end
--save_total_limit 1
--output_dir saved_ ${MODEL} / ${TASK_NAME} _lr ${lr} _loralr ${LORA_LR} _pl ${PREFIX_LENGTH} _r ${R} _st ${MAX_STEPS} ;
done ;
done ;
done You can replace the TASK_NAME with superglue-multirc superglue-wic superglue-wsc.fixed superglue-cb superglue-boolq for the SuperGLUE benchmark, newsqa searchqa hotpotqa nq for the MRQA 2019 Shared Task, winogrande for the WinoGrande dataset, yelp_polarity for the Yelp-2 dataset, scitail for the SciTail dataset, and paws untuk dataset Paws-Wiki.
Selain itu, Anda dapat menambahkan argumen --peft_model_id untuk menginisialisasi soft prompt dan pasangan matriks peringkat rendah dengan vektor prompt pretrained. Anda dapat menambahkan argumen --k_shot_examples untuk menentukan jumlah contoh yang digunakan untuk pembelajaran beberapa shot.
Seperti yang kami lakukan di koran, salah satu batasan potensial dari pekerjaan ini adalah pengenalan hiperparameter tambahan untuk penyetelan, misalnya , tingkat pembelajaran matriks rendah dan langkah-langkah pelatihan. Ini mungkin memperkenalkan beberapa overhead komputasi tambahan selama fase optimisasi hiperparameter dari pelatihan model. Penting untuk mencari semua hiperparameter ini untuk mendapatkan kinerja yang optimal. Untuk dataset besar dengan lebih dari 100.000 contoh pelatihan, kami mengikuti pekerjaan sebelumnya (Vu et al., 2022) untuk melatih departemen metode yang diusulkan dengan 300.000 langkah. Melatih lebih banyak langkah sangat membantu untuk meningkatkan kinerja pada dataset besar. Additonal, seiring dengan panjang permintaan lunak berkurang, mungkin perlu lebih banyak upaya untuk melakukan pencarian hiperparameter. Biasanya, menggunakan prompt lunak dengan panjang PREFIX_LENGTH karena 40 atau 60 harus baik -baik saja. Menggunakan Transfer Learning (PETL) yang efisien secara parameter dapat membantu mengurangi upaya pencarian hiperparameter. Namun, penting untuk dicatat bahwa proses pelatihan model adalah peristiwa satu kali, sedangkan inferensi model tidak. Dalam konteks ini, manfaat efisiensi dept menjadi sangat berharga selama inferensi.
Jika Anda memiliki pertanyaan tentang kode atau kertas, jangan ragu untuk menghubungi Zhengxiang di [email protected] . Jika Anda mengalami kesulitan saat menggunakan kode atau perlu melaporkan bug, jangan ragu untuk membuka masalah. Kami dengan senang hati meminta Anda memberikan informasi terperinci tentang masalah untuk membantu kami memberikan dukungan yang efektif.
@inproceedings{shi2024dept,
title={DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning},
author={Zhengxiang Shi and Aldo Lipani},
booktitle={International Conference on Learning Representations},
year={2024},
url={http://arxiv.org/abs/2309.05173}
}
Repositori ini dibangun di atas repositori berikut:


