DePT
1.0.0
Dieses Repository enthält den Code für das Papier mit dem Titel "Dept: Decomponierte schnelle Tuning für parametereffiziente Feinabstimmungen , wodurch die Integration unserer Codebeiträge in andere Projekte zugänglicher wird.
MODEL auf Ihren lokalen Lama-2-Pfad, um die Experimente durchzuführen.Sie können die Experimente unserer Papierabteilung reproduzieren: zerlegtes Umstimmen für parametereffiziente Feinabstimmungen.
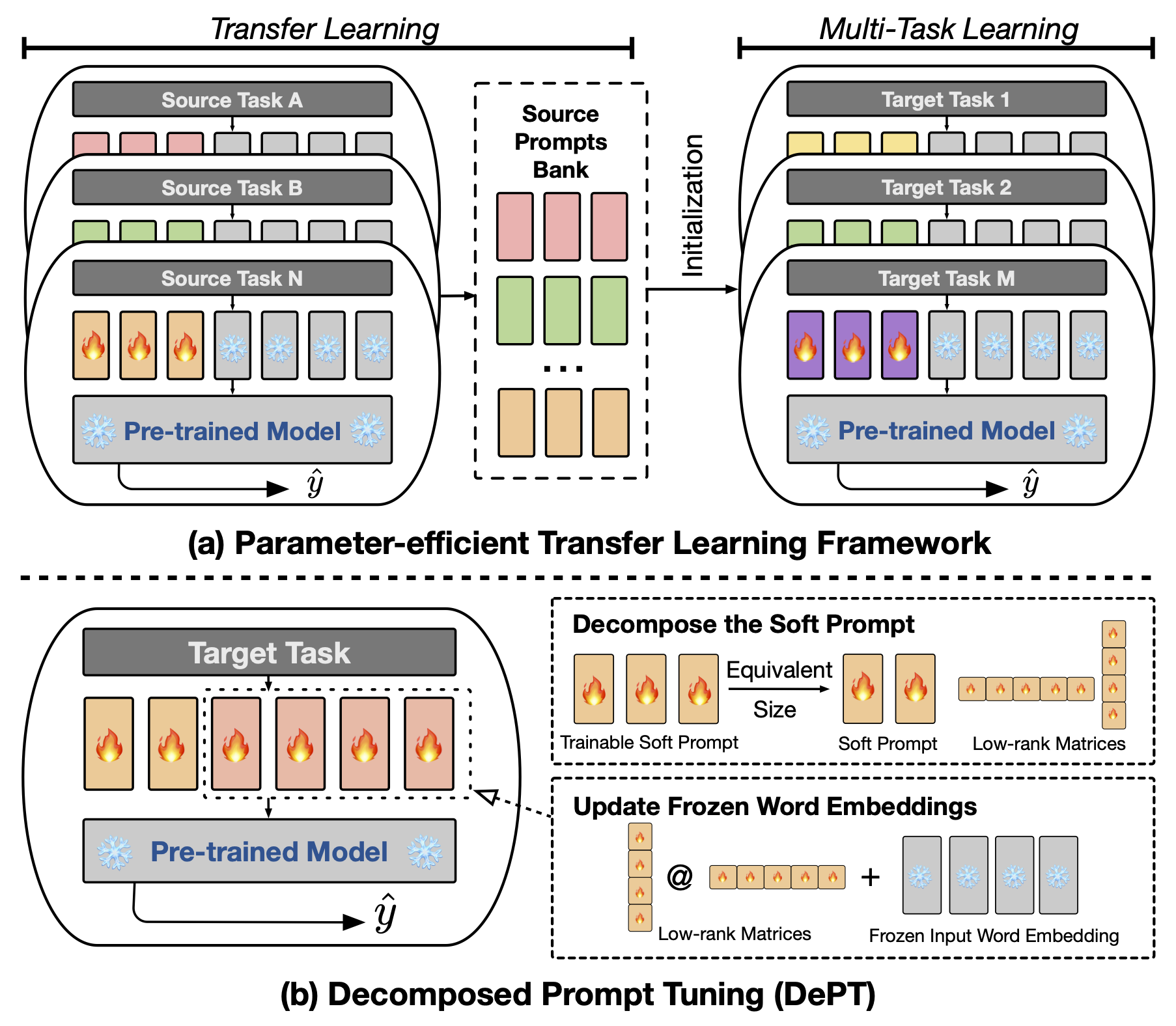
Abstrakte schnelle Tuning (PT), wobei eine kleine Menge an trainierbarem, weichem (kontinuierlichem) sofortiger Vektoren an der Eingabe von Sprachmodellen (LM) befestigt ist, hat vielversprechende Ergebnisse über verschiedene Aufgaben und Modelle für die parametereffiziente Feinabstimmung (PEFT) gezeigt. PT zeichnet sich von anderen PEFT -Ansätzen ab, da es die Wettbewerbsleistung mit weniger trainierbaren Parametern beibehält und seine Parameter mit Erweiterung der Modellgröße nicht drastisch erhöht. PT führt jedoch zusätzliche Soft -Eingabeaufentwicklungs -Token ein, die zu längeren Eingangssequenzen führen, die aufgrund der quadratischen Komplexität des Transformators erheblich auf das Training und die Inferenzzeit und den Speicherverbrauch ausgewirkt werden. Besonders für große Sprachmodelle (LLMs), die einer schweren täglichen Abfrage ausgesetzt sind. Um dieses Problem anzugehen, schlagen wir vor, eine zerlegte Umformung (Abteilung), die die weiche Eingabeaufforderung in eine kürzere weiche Eingabeaufforderung und ein Paar niedriger Rangmatrizen zerlegt, die dann mit zwei verschiedenen Lernraten optimiert werden. Dies ermöglicht eine bessere Leistung und spart gleichzeitig erhebliche Speicher- und Zeitkosten im Vergleich zu Vanille -PT und seinen Varianten, ohne trainierbare Parametergrößen zu ändern. Durch umfangreiche Experimente zu 23 natürlichen Sprachverarbeitung (NLP) und Vision-Sprache (VL) Aufgaben zeigen wir, dass die Abteilung hochmoderne PEFT-Ansätze, einschließlich der vollständigen Feinabstimmung, in einigen Szenarien übertrifft. Darüber hinaus zeigen wir empirisch, dass die Abteilung mit zunehmender Modellgröße effizienter wird. Unsere weitere Studie zeigt, dass die Abteilung nahtlos in das Parameter-effiziente Transferlernen in der Wenig-Shot-Lerneinstellung integriert wird und die Anpassungsfähigkeit an verschiedene Modellarchitekturen und -größen hervorhebt.
Um die eingehend basierte oder CLS-basierte Feinabstimmung auszuführen, müssen Sie die folgenden Pakete installieren.
Wir verwenden die folgenden NLP-Datensätze in unseren Experimenten: Kleber, Superkleber, MRQA 2019 Shared Task, Winogrande, Yelp-2, Scitail und Paws-Wiki. Alle diese Datensätze sind in den Huggingface -Datensätzen verfügbar und können automatisch heruntergeladen werden. Weitere Informationen der Datensätze finden Sie in der Datei src/tasks.py .
Wir stellen die Skripte zur Verfügung, um die Hauptexperimente in unserem Artikel zu reproduzieren. Sie können beispielsweise das folgende Skript ausführen, um die Ergebnisse der Abteilung im Klebstoff -Datensatz zu reproduzieren. Das PREFIX_LENGTH repräsentiert die Länge der weichen Eingabeaufforderung m im Papier. Der R repräsentiert den Rang von niedrigem Matrizen r im Papier. lr ist die Lernrate für die Soft-Eingabeaufforderung, und LORA_LR ist die Lernrate für das Paar der niedrigen Matrizen, die den gefrorenen Wortbettendings hinzugefügt werden.
MODEL=t5-base
MAX_LENGTH=256
MAX_STEPS=40000
PREFIX_LENGTH=40
R=45
for TASK_NAME in cola mrpc mnli qnli qqp rte sst2 stsb ; do
for LORA_LR in 5e-3 3e-1 5e-4 ; do
for lr in 3e-1 4e-1 ; do
CUDA_VISIBLE_DEVICES=0 python train.py
--peft_type PROMPT_TUNING_LORA
--lora_embedding_lr ${LORA_LR}
--learning_rate ${lr}
--prefix_length ${PREFIX_LENGTH}
--r ${R}
--task_name ${TASK_NAME}
--dataset_config_name en
--model_name_or_path ${MODEL}
--do_train
--do_eval
--do_predict
--per_device_train_batch_size 32
--per_device_eval_batch_size 32
--max_seq_length ${MAX_LENGTH}
--save_strategy steps
--evaluation_strategy steps
--max_steps ${MAX_STEPS}
--eval_steps 1000
--save_steps 1000
--warmup_steps 500
--weight_decay 1e-5
--load_best_model_at_end
--save_total_limit 1
--output_dir saved_ ${MODEL} / ${TASK_NAME} _lr ${lr} _loralr ${LORA_LR} _pl ${PREFIX_LENGTH} _r ${R} _st ${MAX_STEPS} ;
done ;
done ;
done You can replace the TASK_NAME with superglue-multirc superglue-wic superglue-wsc.fixed superglue-cb superglue-boolq for the SuperGLUE benchmark, newsqa searchqa hotpotqa nq for the MRQA 2019 Shared Task, winogrande for the WinoGrande dataset, yelp_polarity for the Yelp-2 dataset, scitail for the SciTail dataset, and paws für den PAWS-Wiki-Datensatz.
Zusätzlich können Sie das Argument --peft_model_id hinzufügen, um die Soft-Eingabeaufforderung und das Paar niedriger Rangmatrizen mit den vorgezogenen Eingabeaufforderungen zu initialisieren. Sie können das Argument --k_shot_examples hinzufügen, um die Anzahl der Beispiele anzugeben, die für das Wenige Shot-Lernen verwendet werden.
Während wir in der Arbeit dikussiert sind, ist eine der potenziellen Einschränkungen dieser Arbeit die Einführung zusätzlicher Hyperparameter für das Tuning, z . B. die Lernrate der niedrigen Matrizen und Schulungsschritte. Dies könnte einige zusätzliche Rechenaufwand während der Hyperparameteroptimierungsphase des Modelltrainings einführen. Es ist wichtig, all diese Hyperparameter zu suchen, um die optimale Leistung zu erzielen. Für den großen Datensatz mit mehr als 100.000 Trainingsbeispielen folgen wir den vorherigen Arbeiten (Vu et al., 2022), um unsere vorgeschlagene Methode -Abteilung mit bis zu 300.000 Schritten auszubilden. Weitere Schritte sind hilfreich, um die Leistung der großen Datensätze zu verbessern. Wenn die Länge der weichen Eingabeaufforderungen abnimmt, kann es mehr Anstrengungen erfordern, um die Hyperparameter -Suche durchzuführen. Normalerweise sollte die Verwendung der Soft -Eingabeaufforderung mit der Länge PREFIX_LENGTH als 40 oder 60 in Ordnung sein. Die Verwendung von parameter-effizientem Transferlernen (PETL) kann hilfreich sein, um die Bemühungen für die Hyperparameter-Suche zu verringern. Es ist jedoch wichtig zu beachten, dass der Modelltrainingsprozess ein einmaliges Ereignis ist, während die Modellinferenz nicht ist. In diesem Zusammenhang werden die Effizienzvorteile der Abteilung während der Schlussfolgerung besonders wertvoll.
Wenn Sie Fragen zu dem Code oder dem Papier haben, können Sie sich gerne an Zhengxiang unter [email protected] wenden. Wenn Sie Schwierigkeiten haben, wenn Sie den Code verwenden oder einen Fehler melden müssen, können Sie ein Problem öffnen. Wir bitten Sie freundlich, dass Sie detaillierte Informationen über das Problem bereitstellen, damit wir effektive Unterstützung bieten.
@inproceedings{shi2024dept,
title={DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning},
author={Zhengxiang Shi and Aldo Lipani},
booktitle={International Conference on Learning Representations},
year={2024},
url={http://arxiv.org/abs/2309.05173}
}
Dieses Repository basiert auf folgenden Repositories:


