DePT
1.0.0
يوفر هذا المستودع رمزًا للورقة بعنوان DEPT: ضبط موجه المتحللة للضغط الدقيق الموفرة للمعلمة ، مما يجعل تكامل مساهمات الكود لدينا في مشاريع أخرى يمكن الوصول إليها.
MODEL على مسار LLAMA-2 المحلي لتشغيل التجارب.يمكنك إعادة إنتاج تجارب قسم الورق لدينا: ضبط موجه متحلل للضبط الدقيق الموفرة للمعلمة.
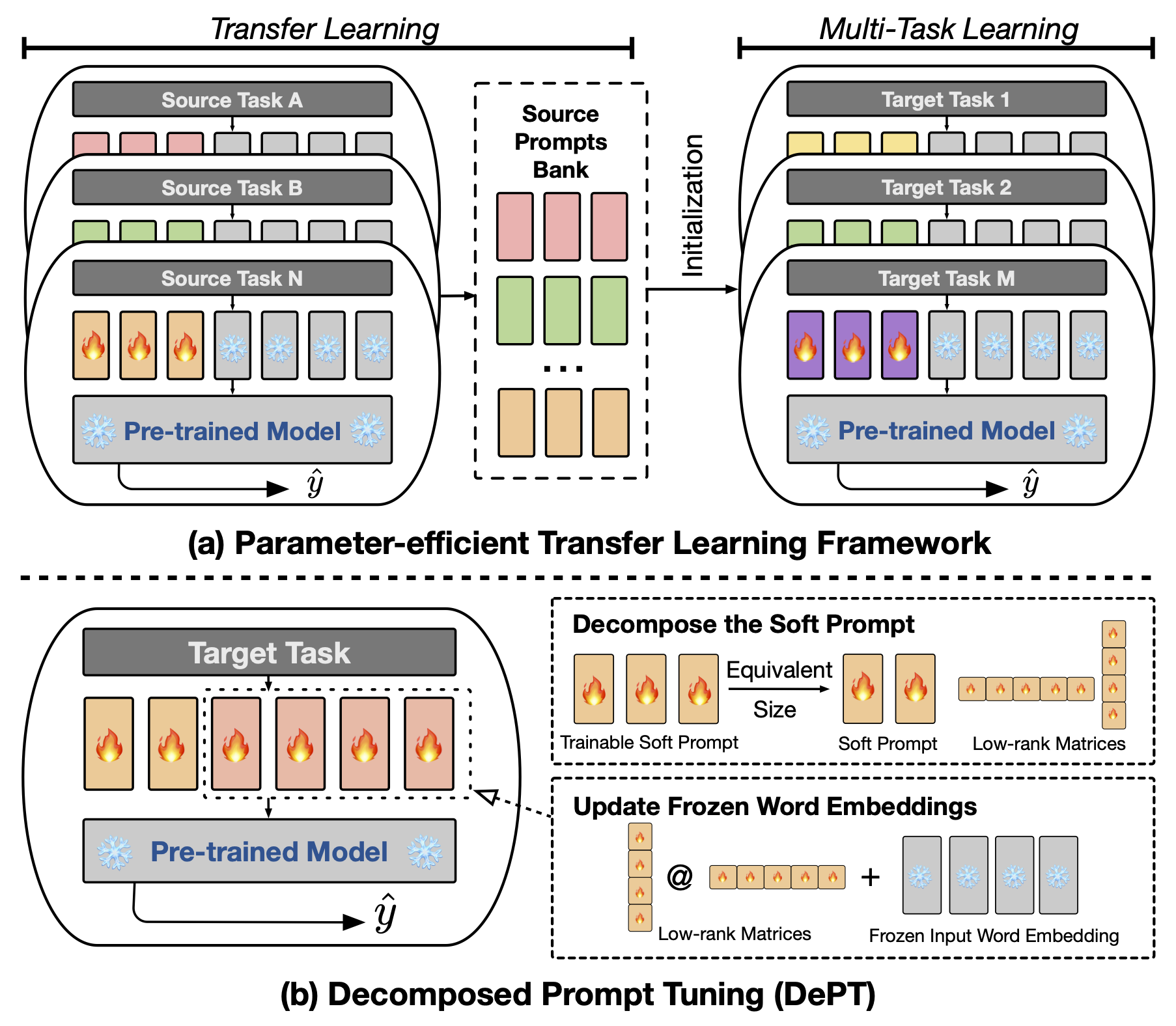
أظهرت ضبط موجه المجردة (PT) ، حيث يتم تثبيت كمية صغيرة من المتجهات الناعمة (المستمرة) القابلة للتدريب (المستمر) على مدخلات نماذج اللغة (LM) ، نتائج واعدة عبر مهام ونماذج مختلفة لضوء المعلمة (PEFT). تبرز PT من أساليب PEFT الأخرى لأنها تحافظ على أداء تنافسي مع عدد أقل من المعلمات القابلة للتدريب ولا يزيد بشكل كبير من معلماته مع توسيع حجم النموذج. ومع ذلك ، تقدم PT رموزًا إضافية ناعمة ، مما يؤدي إلى تسلسل إدخال أطول ، مما يؤثر بشكل كبير على وقت التدريب واستنتاج استخدام الذاكرة بسبب التعقيد التربيعي للمحول. خاصة فيما يتعلق بنماذج اللغة الكبيرة (LLMS) التي تواجه استعلامًا يوميًا ثقيلًا. لمعالجة هذه المشكلة ، نقترح ضبط الموجه المتحلل (DEPT) ، الذي يحلل المطالبة الناعمة إلى مطالبة ناعمة أقصر وزوج من المصفوفات ذات الرتبة المنخفضة التي يتم تحسينها بعد ذلك بمعدلتين تعليميتين مختلفتين. يتيح هذا DEPT تحقيق أداء أفضل مع توفير تكاليف كبيرة للذاكرة والوقت مقارنة مع الفانيليا PT ومتغيراتها ، دون تغيير أحجام المعلمات القابلة للتدريب. من خلال تجارب واسعة النطاق على 23 مهام معالجة اللغة الطبيعية (NLP) ومهام لغة الرؤية (VL) ، نوضح أن DEPT يتفوق على مقاربات PEFT الحديثة ، بما في ذلك خط الأساس الكامل للضوء ، في بعض السيناريوهات. بالإضافة إلى ذلك ، نظهر تجريبياً أن القسم ينمو أكثر كفاءة مع زيادة حجم النموذج. تكشف دراستنا الإضافية أن DEPT تتكامل بسلاسة مع التعلم النقل الفعال للمعلمة في إعداد التعلم قليلًا ويسلط الضوء على قدرته على التكيف مع مختلف بنيات وأحجام النماذج.
لتشغيل الضبط الدقيق المستند إلى المقدمة أو CLS ، تحتاج إلى تثبيت الحزم التالية.
نستخدم مجموعات بيانات NLP التالية في تجاربنا: Glue ، SuperGlue ، MRQA 2019 Task ، Winogrande ، Yelp-2 ، Scitail و Paws-Wiki. جميع مجموعات البيانات هذه متوفرة في مجموعات بيانات HuggingFace ويمكن تنزيلها تلقائيًا. يرجى الرجوع إلى الملف src/tasks.py للحصول على تفاصيل مجموعات البيانات.
نحن نقدم البرامج النصية لإعادة إنتاج التجارب الرئيسية في ورقتنا. على سبيل المثال ، يمكنك تشغيل البرنامج النصي التالي لإعادة إنتاج نتائج DEPT على مجموعة بيانات الغراء. يمثل PREFIX_LENGTH طول المطالبة الناعمة m في الورقة. يمثل R رتبة مصفوفات منخفضة الرتبة r في الورقة. lr هو معدل التعلم للمطالبة الناعمة ، و LORA_LR هو معدل التعلم لزوج المصفوفات ذات الرتبة المنخفضة التي سيتم إضافتها إلى تضمينات الكلمات المجمدة.
MODEL=t5-base
MAX_LENGTH=256
MAX_STEPS=40000
PREFIX_LENGTH=40
R=45
for TASK_NAME in cola mrpc mnli qnli qqp rte sst2 stsb ; do
for LORA_LR in 5e-3 3e-1 5e-4 ; do
for lr in 3e-1 4e-1 ; do
CUDA_VISIBLE_DEVICES=0 python train.py
--peft_type PROMPT_TUNING_LORA
--lora_embedding_lr ${LORA_LR}
--learning_rate ${lr}
--prefix_length ${PREFIX_LENGTH}
--r ${R}
--task_name ${TASK_NAME}
--dataset_config_name en
--model_name_or_path ${MODEL}
--do_train
--do_eval
--do_predict
--per_device_train_batch_size 32
--per_device_eval_batch_size 32
--max_seq_length ${MAX_LENGTH}
--save_strategy steps
--evaluation_strategy steps
--max_steps ${MAX_STEPS}
--eval_steps 1000
--save_steps 1000
--warmup_steps 500
--weight_decay 1e-5
--load_best_model_at_end
--save_total_limit 1
--output_dir saved_ ${MODEL} / ${TASK_NAME} _lr ${lr} _loralr ${LORA_LR} _pl ${PREFIX_LENGTH} _r ${R} _st ${MAX_STEPS} ;
done ;
done ;
done يمكنك استبدال TASK_NAME بـ superglue-multirc superglue-wic superglue-wsc.fixed superglue-cb superglue-boolq للحصول على معيار superglue ، newsqa searchqa hotpotqa nq للمهمة المشتركة لـ mrqa 2019 ، winogrande for winogrande ، yelp_polarity for the scitail for scitail ، paws لمجموعة بيانات PAWS-Wiki.
بالإضافة إلى ذلك ، يمكنك إضافة الوسيطة- --peft_model_id لتهيئة المطالبة الناعمة وزوج المصفوفات ذات الرتبة المنخفضة مع ناقلات موجه مسبق. يمكنك إضافة الوسيطة- --k_shot_examples لتحديد عدد الأمثلة المستخدمة لتعلم القليل من اللقطة.
نظرًا لأننا قمنا بالانحناء في الورقة ، فإن أحد القيود المحتملة لهذا العمل هو إدخال مكافآت عالية للضبط ، على سبيل المثال ، معدل تعلم المصفوفات منخفضة الرتبة وخطوات التدريب. قد يقدم هذا بعض النفقات العامة الحاسوبية الإضافية خلال مرحلة تحسين الفائقة من التدريب النموذجي. من المهم البحث على كل هذه المقاييس المفرطة للحصول على الأداء الأمثل. بالنسبة لمجموعة البيانات الكبيرة التي تضم أكثر من 100000 مثال تدريبي ، نتبع العمل السابق (Vu et al. ، 2022) لتدريب قسم الطريقة المقترحة مع ما يصل إلى 300000 خطوة. تدريب المزيد من الخطوات مفيد لتحسين الأداء على مجموعات البيانات الكبيرة. الإضافة ، مع انخفاض طول المطالبات الناعمة ، قد يستغرق المزيد من الجهود لإجراء البحث فرط البارامتر. عادة ، يجب أن يكون استخدام المطالبة الناعمة مع الطول PREFIX_LENGTH كـ 40 أو 60 على ما يرام. يمكن أن يكون استخدام تعلم النقل الموفرة للمعلمة (PETL) مفيدًا لتقليل الجهود المبذولة لبحث فرط الأطر. ومع ذلك ، من المهم أن نلاحظ أن عملية تدريب النماذج هي حدث لمرة واحدة ، في حين أن استدلال النموذج ليس كذلك. في هذا السياق ، تصبح فوائد الكفاءة للقسم ذات قيمة خاصة أثناء الاستدلال.
إذا كان لديك أي أسئلة بخصوص الكود أو الورقة ، فلا تتردد في الوصول إلى Zhengxiang في [email protected] . إذا واجهت أي صعوبات أثناء استخدام الرمز أو تحتاج إلى الإبلاغ عن خطأ ، فلا تتردد في فتح مشكلة. نطلب منك أن تقدم معلومات مفصلة حول المشكلة لمساعدتنا في تقديم دعم فعال.
@inproceedings{shi2024dept,
title={DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning},
author={Zhengxiang Shi and Aldo Lipani},
booktitle={International Conference on Learning Representations},
year={2024},
url={http://arxiv.org/abs/2309.05173}
}
هذا المستودع مبني على المستودعات التالية:


