DePT
1.0.0
Este repositório fornece o código para o artigo intitulado departamento: ajuste rápido decomposto para obter ajuste fino com eficiência de parâmetro , tornando a integração de nossas contribuições de código em outros projetos mais acessíveis.
MODEL para o seu caminho de llama-2 local para executar os experimentos.Você pode reproduzir os experimentos do nosso Departamento de Artigo: Decomposição Prompt Tuning para obter ajustes finos com eficiência de parâmetro.
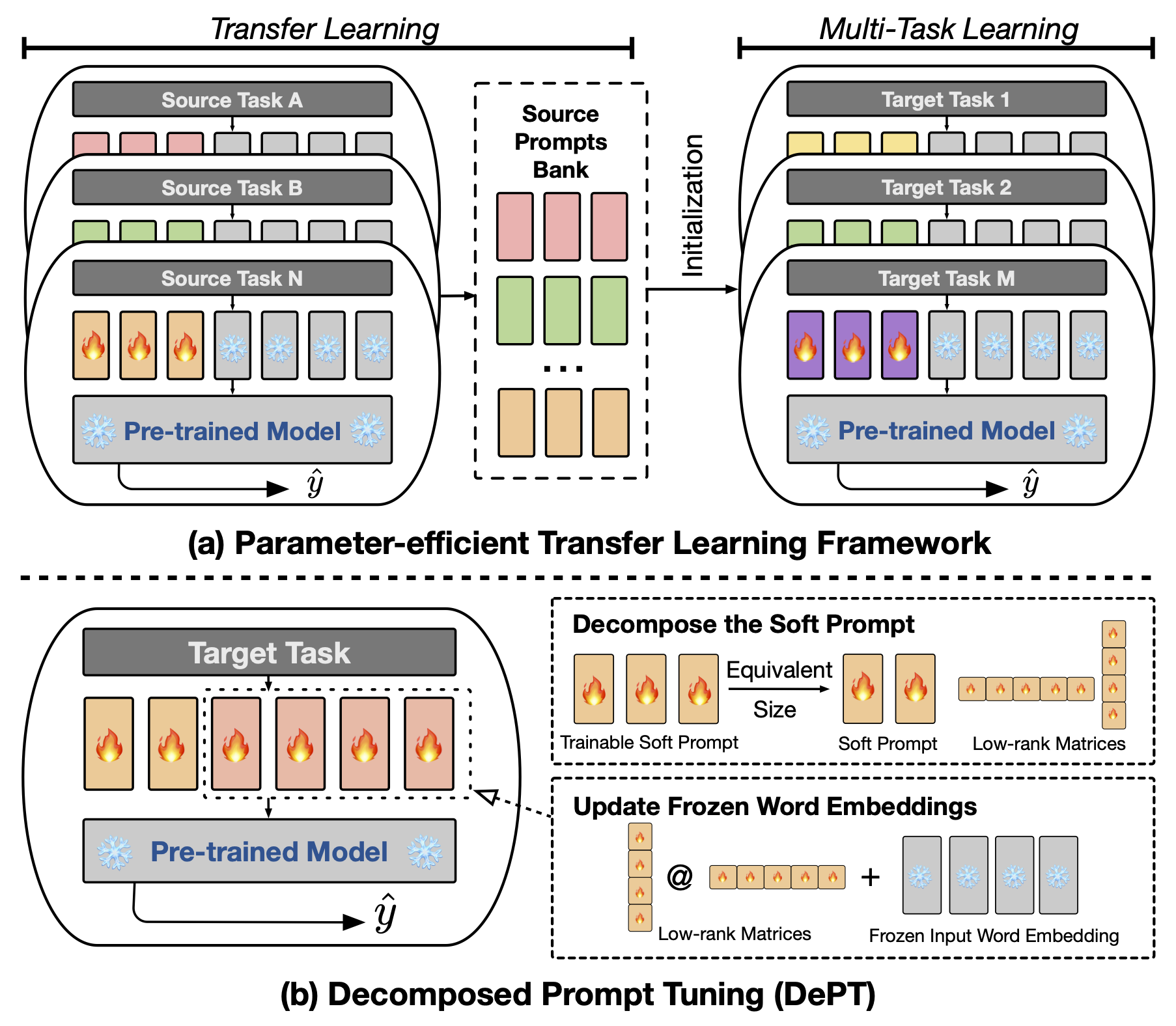
A ajuste imediato de abstrato (PT), onde uma pequena quantidade de vetores prontos prontualizados (contínuos) treináveis é afixados na entrada de modelos de linguagem (LM), mostrou resultados promissores em várias tarefas e modelos para ajuste fino com eficiência de parâmetro (PEFT). O PT se destaca de outras abordagens de PEFT porque mantém o desempenho competitivo com menos parâmetros treináveis e não aumenta drasticamente seus parâmetros à medida que o tamanho do modelo se expande. No entanto, o PT introduz tokens de prompt de soft adicionais, levando a sequências de entrada mais longas, o que afeta significativamente o tempo de treinamento e o tempo de inferência e o uso da memória devido à complexidade quadrática do transformador. Particularmente relacionado a grandes modelos de linguagem (LLMs) que enfrentam consulta diária pesada. Para resolver esse problema, propomos que o ajuste rápido decomposto (departamento), que decompõe o prompt suave em um prompt suave mais curto e um par de matrizes de baixo rank que são otimizadas com duas taxas de aprendizado diferentes. Isso permite que o Departamento alcance melhor desempenho, economizando custos substanciais de memória e tempo em comparação com o PT de baunilha e suas variantes, sem alterar os tamanhos de parâmetros treináveis. Por meio de extensos experimentos sobre 23 tarefas de processamento de linguagem natural (PNL) e linguagem da visão (VL), demonstramos que o Departamento supera as abordagens de Peft de última geração, incluindo a linha de base completa de ajuste fino, em alguns cenários. Além disso, mostramos empiricamente que o departamento se torna mais eficiente à medida que o tamanho do modelo aumenta. Nosso estudo adicional revela que o Departamento se integra perfeitamente ao aprendizado de transferência eficiente em parâmetro no ambiente de aprendizado de poucos tiros e destaca sua adaptabilidade a várias arquiteturas e tamanhos de modelo.
Para executar o ajuste fino baseado em prompt ou baseado em CLS, você precisa instalar os pacotes a seguir.
Utilizamos os seguintes conjuntos de dados NLP em nossos experimentos: cola, superclue, MRQA 2019 Shared Task, Winogrande, Yelp-2, Scitail e Paws-wiki. Todos esses conjuntos de dados estão disponíveis nos conjuntos de dados Huggingface e podem ser baixados automaticamente. Consulte o arquivo src/tasks.py para obter os detalhes dos conjuntos de dados.
Fornecemos os scripts para reproduzir os principais experimentos em nosso artigo. Por exemplo, você pode executar o seguinte script para reproduzir os resultados do departamento no conjunto de dados de cola. O PREFIX_LENGTH representa o comprimento do prompt suave m no papel. O R representa o posto de matrizes de baixo rank r no papel. lr é a taxa de aprendizado para o prompt Soft, e LORA_LR é a taxa de aprendizado para o par das matrizes de baixo rank que serão adicionadas às incorporações de palavras congeladas.
MODEL=t5-base
MAX_LENGTH=256
MAX_STEPS=40000
PREFIX_LENGTH=40
R=45
for TASK_NAME in cola mrpc mnli qnli qqp rte sst2 stsb ; do
for LORA_LR in 5e-3 3e-1 5e-4 ; do
for lr in 3e-1 4e-1 ; do
CUDA_VISIBLE_DEVICES=0 python train.py
--peft_type PROMPT_TUNING_LORA
--lora_embedding_lr ${LORA_LR}
--learning_rate ${lr}
--prefix_length ${PREFIX_LENGTH}
--r ${R}
--task_name ${TASK_NAME}
--dataset_config_name en
--model_name_or_path ${MODEL}
--do_train
--do_eval
--do_predict
--per_device_train_batch_size 32
--per_device_eval_batch_size 32
--max_seq_length ${MAX_LENGTH}
--save_strategy steps
--evaluation_strategy steps
--max_steps ${MAX_STEPS}
--eval_steps 1000
--save_steps 1000
--warmup_steps 500
--weight_decay 1e-5
--load_best_model_at_end
--save_total_limit 1
--output_dir saved_ ${MODEL} / ${TASK_NAME} _lr ${lr} _loralr ${LORA_LR} _pl ${PREFIX_LENGTH} _r ${R} _st ${MAX_STEPS} ;
done ;
done ;
done Você pode substituir o TASK_NAME pelo superglue-multirc superglue-wic superglue-wsc.fixed superglue-cb superglue-boolq yelp_polarity a referência Superclue, newsqa searchqa hotpotqa nq para o scitas MRQA 2019 Shared Task, winogrande para o DataSet, scitail paws para o conjunto de dados Paws-Wiki.
Além disso, você pode adicionar o argumento --peft_model_id para inicializar o prompt Soft e o par de matrizes de baixo rank com os vetores prompts pré-treinados. Você pode adicionar o argumento --k_shot_examples para especificar o número de exemplos usados para o aprendizado de poucos tiro.
À medida que explodimos no artigo, uma das limitações potenciais deste trabalho é a introdução de hiperparâmetros extras para ajustar, por exemplo , a taxa de aprendizado das matrizes e etapas de treinamento de baixo rank. Isso pode introduzir algumas despesas gerais computacionais adicionais durante a fase de otimização de hiperparâmetro do treinamento do modelo. É importante pesquisar todos esses hiperparâmetros para obter o desempenho ideal. Para o grande conjunto de dados com mais de 100.000 exemplo de treinamento, seguimos o trabalho anterior (Vu et al., 2022) para treinar nosso departamento de método proposto com até 300.000 etapas. O treinamento de mais etapas é útil para melhorar o desempenho nos grandes conjuntos de dados. Além disso, à medida que o comprimento dos avisos suaves diminui, pode levar mais esforços para realizar a pesquisa de hiperparâmetro. Normalmente, o uso do prompt Soft com o comprimento PREFIX_LENGTH como 40 ou 60 deve ficar bem. O uso do aprendizado de transferência eficiente em parâmetro (PETL) pode ser útil para reduzir os esforços para a pesquisa de hiperparâmetro. No entanto, é importante observar que o processo de treinamento do modelo é um evento único, enquanto a inferência do modelo não é. Nesse contexto, os benefícios de eficiência do departamento se tornam especialmente valiosos durante a inferência.
Se você tiver alguma dúvida sobre o código ou o artigo, sinta -se à vontade para entrar em contato com Zhengxiang em [email protected] . Se você tiver alguma dificuldade ao usar o código ou precisar relatar um bug, fique à vontade para abrir um problema. Pedimos gentilmente que você forneça informações detalhadas sobre o problema para nos ajudar a fornecer suporte eficaz.
@inproceedings{shi2024dept,
title={DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning},
author={Zhengxiang Shi and Aldo Lipani},
booktitle={International Conference on Learning Representations},
year={2024},
url={http://arxiv.org/abs/2309.05173}
}
Este repositório é construído sobre os seguintes repositórios:


