DePT
1.0.0
ที่เก็บนี้ให้รหัสสำหรับกระดาษชื่อ Dept: การปรับแต่งการปรับแต่งการปรับแต่งสำหรับการปรับแต่งพารามิเตอร์อย่างประหยัด ทำให้การรวมรหัสของเราเข้ากับโครงการอื่น ๆ ที่เข้าถึงได้ง่ายขึ้น
MODEL เป็นเส้นทาง Llama-2 ในพื้นที่ของคุณเพื่อเรียกใช้การทดลองคุณสามารถทำซ้ำการทดลองของแผนกกระดาษของเรา: การปรับแต่งการปรับแต่งการปรับแต่งสำหรับการปรับแต่งพารามิเตอร์ที่มีประสิทธิภาพ
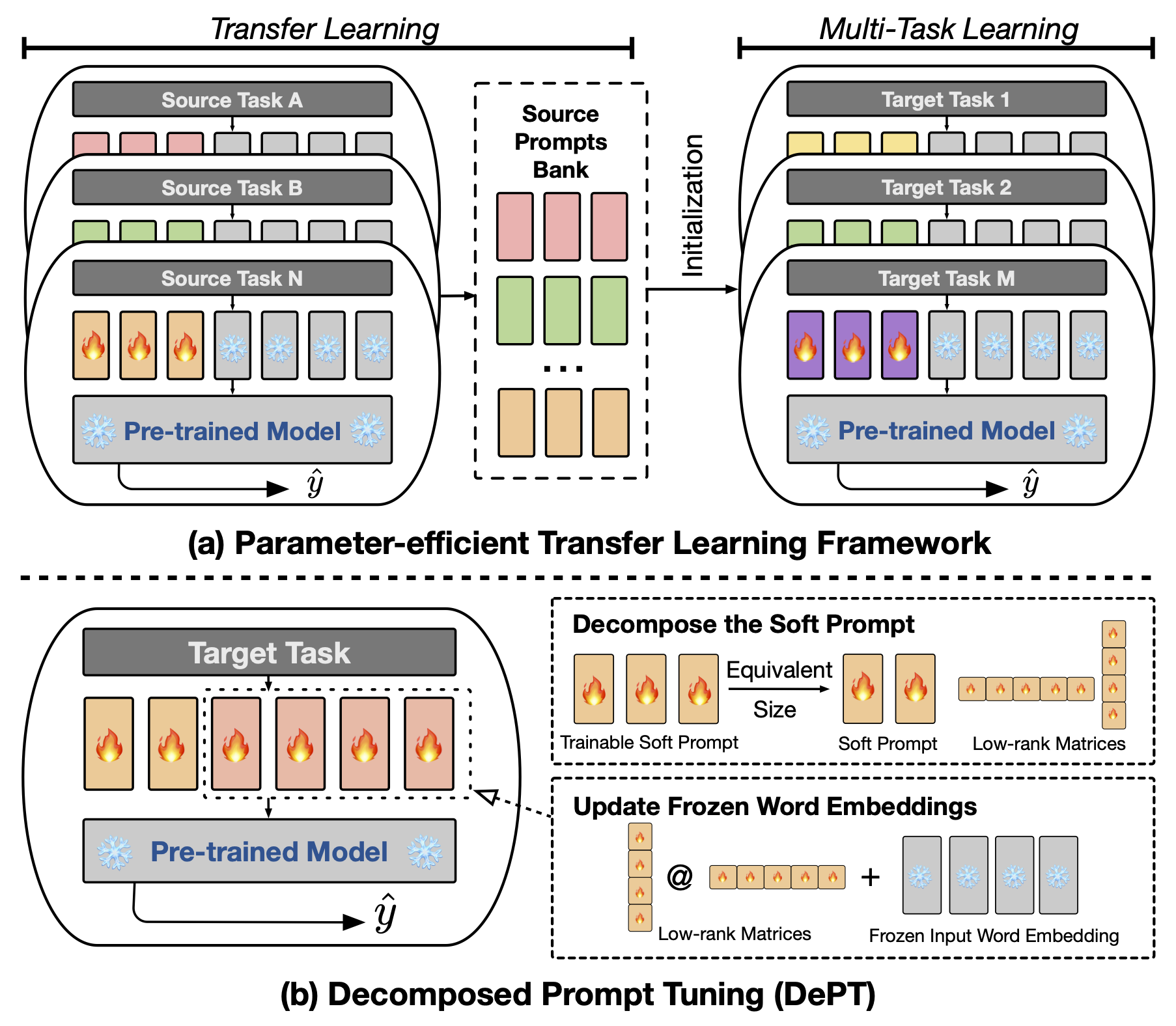
บทคัดย่อ การปรับจูน (PT) ซึ่งมีเวกเตอร์พรอมต์ที่มีความนุ่มนวล (ต่อเนื่อง) จำนวนเล็กน้อยที่ติดอยู่กับอินพุตของแบบจำลองภาษา (LM) ได้แสดงผลลัพธ์ที่มีแนวโน้มในงานและรุ่นต่าง ๆ สำหรับการปรับจูนพารามิเตอร์ (PEFT) PT โดดเด่นจากวิธีการ PEFT อื่น ๆ เพราะมันรักษาประสิทธิภาพการแข่งขันโดยมีพารามิเตอร์ที่สามารถฝึกอบรมได้น้อยลงและไม่ขยายพารามิเตอร์ของมันอย่างมากเมื่อขนาดของรุ่นขยายตัว อย่างไรก็ตาม PT แนะนำโทเค็น Soft Prompt เพิ่มเติมซึ่งนำไปสู่ลำดับการป้อนข้อมูลที่ยาวนานขึ้นซึ่งส่งผลกระทบต่อการฝึกอบรมและเวลาการอนุมานและการใช้หน่วยความจำอย่างมีนัยสำคัญเนื่องจากความซับซ้อนของการเป็นกำลังสองของหม้อแปลง โดยเฉพาะอย่างยิ่งเกี่ยวกับโมเดลภาษาขนาดใหญ่ (LLMs) ที่ต้องเผชิญกับการสืบค้นทุกวันอย่างหนัก เพื่อแก้ไขปัญหานี้เราเสนอการปรับแต่งการปรับแต่ง (DEPT) ซึ่งย่อยสลายซึ่งย่อยสลายได้ด้วยพรอมต์ที่อ่อนนุ่มลงในพรอมต์ที่สั้นกว่าและเมทริกซ์ระดับต่ำคู่หนึ่งซึ่งได้รับการปรับให้เหมาะสมด้วยอัตราการเรียนรู้ที่แตกต่างกันสองอัตรา สิ่งนี้ช่วยให้แผนกสามารถบรรลุประสิทธิภาพที่ดีขึ้นในขณะที่ประหยัดค่าใช้จ่ายหน่วยความจำและเวลาที่สำคัญเมื่อเทียบกับวานิลลา PT และตัวแปรของมันโดยไม่ต้องเปลี่ยนขนาดพารามิเตอร์ที่สามารถฝึกอบรมได้ ผ่านการทดลองอย่างกว้างขวางเกี่ยวกับการประมวลผลภาษาธรรมชาติ 23 รายการ (NLP) และงาน Vision-Language (VL) เราแสดงให้เห็นว่าแผนกมีประสิทธิภาพสูงกว่าแนวทาง PEFT ที่ล้ำสมัยรวมถึงพื้นฐานการปรับแต่งแบบเต็มในบางสถานการณ์ นอกจากนี้เรายังแสดงให้เห็นว่า DEPT เติบโตอย่างมีประสิทธิภาพมากขึ้นเมื่อขนาดของโมเดลเพิ่มขึ้น การศึกษาเพิ่มเติมของเราแสดงให้เห็นว่าแผนกรวมเข้ากับการเรียนรู้การถ่ายโอนพารามิเตอร์อย่างมีประสิทธิภาพอย่างราบรื่นในการตั้งค่าการเรียนรู้ไม่กี่ครั้งและเน้นการปรับตัวให้เข้ากับสถาปัตยกรรมและขนาดของแบบจำลองต่างๆ
ในการเรียกใช้การปรับจูนตามพรอมต์หรือ CLS คุณต้องติดตั้งแพ็คเกจต่อไปนี้
เราใช้ชุดข้อมูล NLP ต่อไปนี้ในการทดลองของเรา: กาว, Superglue, งานที่ใช้ร่วมกันของ MRQA 2019, Winogrande, Yelp-2, Scitail และ Paws-Wiki ชุดข้อมูลทั้งหมดเหล่านี้มีอยู่ในชุดข้อมูล HuggingFace และสามารถดาวน์โหลดได้โดยอัตโนมัติ โปรดดูไฟล์ src/tasks.py สำหรับรายละเอียดของชุดข้อมูล
เราให้สคริปต์เพื่อทำซ้ำการทดลองหลักในบทความของเรา ตัวอย่างเช่นคุณสามารถเรียกใช้สคริปต์ต่อไปนี้เพื่อทำซ้ำผลลัพธ์ของ DEPT ในชุดข้อมูลกาว PREFIX_LENGTH แสดงถึงความยาวของ Soft Prompt m ในกระดาษ R หมายถึงอันดับของเมทริกซ์ r ต่ำในกระดาษ lr คืออัตราการเรียนรู้สำหรับพรอมต์ที่นุ่มนวลและ LORA_LR เป็นอัตราการเรียนรู้สำหรับคู่ของเมทริกซ์ระดับต่ำที่จะถูกเพิ่มเข้าไปในการฝังคำแช่แข็ง
MODEL=t5-base
MAX_LENGTH=256
MAX_STEPS=40000
PREFIX_LENGTH=40
R=45
for TASK_NAME in cola mrpc mnli qnli qqp rte sst2 stsb ; do
for LORA_LR in 5e-3 3e-1 5e-4 ; do
for lr in 3e-1 4e-1 ; do
CUDA_VISIBLE_DEVICES=0 python train.py
--peft_type PROMPT_TUNING_LORA
--lora_embedding_lr ${LORA_LR}
--learning_rate ${lr}
--prefix_length ${PREFIX_LENGTH}
--r ${R}
--task_name ${TASK_NAME}
--dataset_config_name en
--model_name_or_path ${MODEL}
--do_train
--do_eval
--do_predict
--per_device_train_batch_size 32
--per_device_eval_batch_size 32
--max_seq_length ${MAX_LENGTH}
--save_strategy steps
--evaluation_strategy steps
--max_steps ${MAX_STEPS}
--eval_steps 1000
--save_steps 1000
--warmup_steps 500
--weight_decay 1e-5
--load_best_model_at_end
--save_total_limit 1
--output_dir saved_ ${MODEL} / ${TASK_NAME} _lr ${lr} _loralr ${LORA_LR} _pl ${PREFIX_LENGTH} _r ${R} _st ${MAX_STEPS} ;
done ;
done ;
done คุณสามารถแทนที่ TASK_NAME ด้วย superglue-multirc superglue-wic superglue-wsc.fixed superglue-cb superglue-boolq winogrande yelp_polarity มาตรฐาน superglue, newsqa searchqa hotpotqa nq สำหรับ Datas- scitail -datas paws สำหรับชุดข้อมูล Paws-Wiki
นอกจากนี้คุณสามารถเพิ่มอาร์กิวเมนต์ --peft_model_id เพื่อเริ่มต้นพรอมต์ซอฟต์และคู่ของเมทริกซ์ระดับต่ำด้วยเวกเตอร์พรอมต์ที่ได้รับการฝึกฝน คุณสามารถเพิ่มอาร์กิวเมนต์ --k_shot_examples เพื่อระบุจำนวนตัวอย่างที่ใช้สำหรับการเรียนรู้ไม่กี่นัด
ในขณะที่เราแยกแยะในกระดาษหนึ่งในข้อ จำกัด ที่เป็นไปได้ของงานนี้คือการแนะนำพารามิเตอร์พิเศษสำหรับการปรับจูน เช่น อัตราการเรียนรู้ของเมทริกซ์ระดับต่ำและขั้นตอนการฝึกอบรม สิ่งนี้อาจแนะนำค่าใช้จ่ายในการคำนวณเพิ่มเติมในระหว่างขั้นตอนการเพิ่มประสิทธิภาพของไฮเปอร์พารามิเตอร์ของการฝึกอบรมแบบจำลอง มันเป็นสิ่งสำคัญที่จะค้นหาพารามิเตอร์ hyperparameters เหล่านี้ทั้งหมดเพื่อให้ได้ประสิทธิภาพที่ดีที่สุด สำหรับชุดข้อมูลขนาดใหญ่ที่มีตัวอย่างการฝึกอบรมมากกว่า 100,000 ตัวอย่างเราทำตามงานก่อนหน้า (Vu et al., 2022) เพื่อฝึกอบรมแผนกวิธีการที่เราเสนอด้วยขั้นตอนมากถึง 300,000 ขั้นตอน การฝึกอบรมขั้นตอนมากขึ้นมีประโยชน์สำหรับการปรับปรุงประสิทธิภาพในชุดข้อมูลขนาดใหญ่ ในขณะที่ความยาวของพรอมต์อ่อนลงอาจใช้ความพยายามมากขึ้นในการค้นหา hyperparameter โดยทั่วไปการใช้พรอมต์ซอฟต์ที่มีความยาว PREFIX_LENGTH เป็น 40 หรือ 60 ควรจะดี การใช้การเรียนรู้การถ่ายโอนพารามิเตอร์ (PETL) มีประโยชน์ในการลดความพยายามในการค้นหา hyperparameter อย่างไรก็ตามเป็นสิ่งสำคัญที่จะต้องทราบว่ากระบวนการฝึกอบรมแบบจำลองเป็นเหตุการณ์ครั้งเดียวในขณะที่การอนุมานแบบจำลองไม่ได้ ในบริบทนี้ผลประโยชน์ประสิทธิภาพของแผนกมีค่าโดยเฉพาะอย่างยิ่งในระหว่างการอนุมาน
หากคุณมีคำถามใด ๆ เกี่ยวกับรหัสหรือกระดาษโปรดอย่าลังเลที่จะติดต่อ Zhengxiang ที่ [email protected] หากคุณประสบปัญหาใด ๆ ในขณะที่ใช้รหัสหรือจำเป็นต้องรายงานข้อผิดพลาดอย่าลังเลที่จะเปิดปัญหา เราขอให้คุณให้ข้อมูลโดยละเอียดเกี่ยวกับปัญหาเพื่อช่วยให้เราให้การสนับสนุนที่มีประสิทธิภาพ
@inproceedings{shi2024dept,
title={DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning},
author={Zhengxiang Shi and Aldo Lipani},
booktitle={International Conference on Learning Representations},
year={2024},
url={http://arxiv.org/abs/2309.05173}
}
ที่เก็บนี้สร้างขึ้นบนที่เก็บต่อไปนี้:


