DePT
1.0.0
Этот репозиторий предоставляет код для статьи под названием «Департамент: разложенная настройка быстрого настройки для параметров точной настройки , что делает интеграцию наших вкладов кода в другие проекты более доступной.
MODEL на свой локальный путь Llama-2, чтобы запустить эксперименты.Вы можете воспроизвести эксперименты нашего бумажного отделения: разложенная настройка быстрого настройки для точной настройки параметров.
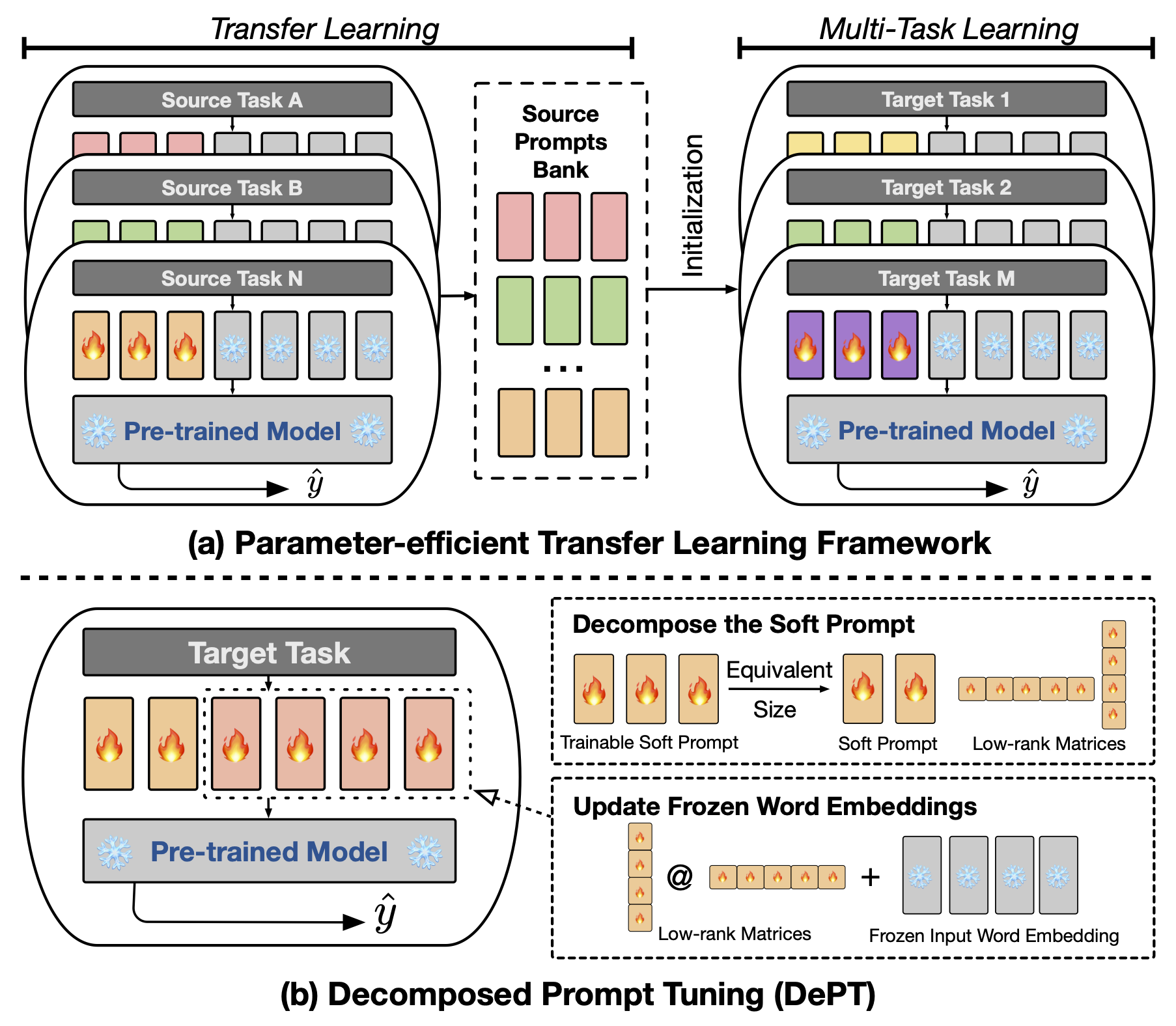
Абстрактная настройка быстрого приглашения (PT), где небольшое количество тренировочных (непрерывных) оперативных векторов прикрепляется к вводу языковых моделей (LM), показал многообещающие результаты по различным задачам и моделям для эффективной настройки параметров (PEFT). PT выделяется среди других подходов PEFT, потому что он поддерживает конкурентную производительность с меньшим количеством обучения параметров и не значительно увеличивает свои параметры по мере расширения размера модели. Тем не менее, PT вводит дополнительные токены Soft Prompt, что приводит к более длинным входным последовательностям, что значительно влияет на время обучения и времени вывода и использование памяти из -за квадратичной сложности трансформатора. Особенно касается крупных языковых моделей (LLMS), которые сталкиваются с тяжелыми ежедневными запросами. Чтобы решить эту проблему, мы предлагаем разложить настройку быстрого быстрого настройки (DEPT), которая разлагает мягкую подсказку на более короткую мягкую подсказку и пару матриц с низким уровнем ранга, которые затем оптимизируются с двумя различными скоростями обучения. Это позволяет отделу достигать лучшей производительности, сохраняя при этом существенные затраты на память и по времени по сравнению с ванильным PT и его вариантами, без изменения обучаемых размеров параметров. Благодаря обширным экспериментам по 23 задачам обработки естественного языка (NLP) и зрительном языке (VL) мы демонстрируем, что Dept Ourfers превзошли современные подходы PEFT, включая полную базовую линию с точной настройкой, в некоторых сценариях. Кроме того, мы эмпирически показываем, что отдел становится все более эффективным по мере увеличения размера модели. Наше дальнейшее исследование показывает, что DEPT легко интегрируется с параметром, эффективным для переноса, в условиях нескольких выстрелов и подчеркивает ее адаптивность к различным модельным архитектурам и размерам.
Чтобы запустить точную настройку на основе быстрого или CLS, вам необходимо установить следующие пакеты.
В наших экспериментах мы используем следующие наборы NLP: Glue, SuperGlue, MRQA 2019 общая задача, Winogrande, Yelp-2, Scitail и Paws-Wiki. Все эти наборы данных доступны в наборах данных HuggingFace и могут быть загружены автоматически. Пожалуйста, обратитесь к файлу src/tasks.py для получения информации о наборах данных.
Мы предоставляем сценарии для воспроизведения основных экспериментов в нашей статье. Например, вы можете запустить следующий сценарий, чтобы воспроизвести результаты отделения на наборе данных клей. PREFIX_LENGTH представляет длину мягкой подсказки m в бумаге. R представляет собой ранг матриц с низким рейтингом r в статье. lr -это скорость обучения для мягкой подсказки, а LORA_LR -это скорость обучения для пары матриц с низким рейтингом, которые будут добавлены в замороженные встроенные слова.
MODEL=t5-base
MAX_LENGTH=256
MAX_STEPS=40000
PREFIX_LENGTH=40
R=45
for TASK_NAME in cola mrpc mnli qnli qqp rte sst2 stsb ; do
for LORA_LR in 5e-3 3e-1 5e-4 ; do
for lr in 3e-1 4e-1 ; do
CUDA_VISIBLE_DEVICES=0 python train.py
--peft_type PROMPT_TUNING_LORA
--lora_embedding_lr ${LORA_LR}
--learning_rate ${lr}
--prefix_length ${PREFIX_LENGTH}
--r ${R}
--task_name ${TASK_NAME}
--dataset_config_name en
--model_name_or_path ${MODEL}
--do_train
--do_eval
--do_predict
--per_device_train_batch_size 32
--per_device_eval_batch_size 32
--max_seq_length ${MAX_LENGTH}
--save_strategy steps
--evaluation_strategy steps
--max_steps ${MAX_STEPS}
--eval_steps 1000
--save_steps 1000
--warmup_steps 500
--weight_decay 1e-5
--load_best_model_at_end
--save_total_limit 1
--output_dir saved_ ${MODEL} / ${TASK_NAME} _lr ${lr} _loralr ${LORA_LR} _pl ${PREFIX_LENGTH} _r ${R} _st ${MAX_STEPS} ;
done ;
done ;
done You can replace the TASK_NAME with superglue-multirc superglue-wic superglue-wsc.fixed superglue-cb superglue-boolq for the SuperGLUE benchmark, newsqa searchqa hotpotqa nq for the MRQA 2019 Shared Task, winogrande for the WinoGrande dataset, yelp_polarity for the Yelp-2 dataset, scitail for the SciTail dataset, and paws для набора данных Paws-Wiki.
Кроме того, вы можете добавить аргумент- --peft_model_id , чтобы инициализировать мягкую подсказку и пару матриц с низким уровнем ранга с предварительными векторами. Вы можете добавить аргумент --k_shot_examples , чтобы указать количество примеров, используемых для нескольких выстрелов.
Как мы обсуждали в статье, одним из потенциальных ограничений этой работы является введение дополнительных гиперпараметров для настройки, например , скорость обучения матриц с низким рейтингом и этапы обучения. Это может ввести некоторые дополнительные вычислительные накладные расходы во время фазы оптимизации гиперпараметрической оптимизации. Важно искать все эти гиперпараметры, чтобы получить оптимальную производительность. Для большого набора данных с более чем 100 000 примеров обучения мы следуем предыдущей работе (Vu et al., 2022), чтобы обучить предлагаемый наш отдел метода с до 300 000 шагов. Обучение больше шагов полезно для повышения производительности в больших наборах данных. Additonally, поскольку длина мягких подсказок уменьшается, может потребоваться больше усилий для выполнения поиска гиперпараметрических. Как правило, использование мягкой подсказки с PREFIX_LENGTH длиной, как 40 или 60 должно быть хорошо. Использование параметров-эффективного обучения передачи (PETL) может быть полезно для уменьшения усилий по поиску гиперпараметрических. Тем не менее, важно отметить, что процесс обучения модели является единовременным событием, а модельный вывод-нет. В этом контексте преимущества эффективности департамента становятся особенно ценными во время вывода.
Если у вас есть какие -либо вопросы относительно кода или статьи, пожалуйста, не стесняйтесь обратиться к Zhengxiang по адресу [email protected] . Если вы испытываете какие -либо трудности при использовании кода или вам нужно сообщать об ошибке, не стесняйтесь открывать проблему. Мы просим, чтобы вы предоставили подробную информацию о проблеме, чтобы помочь нам оказать эффективную поддержку.
@inproceedings{shi2024dept,
title={DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning},
author={Zhengxiang Shi and Aldo Lipani},
booktitle={International Conference on Learning Representations},
year={2024},
url={http://arxiv.org/abs/2309.05173}
}
Этот репозиторий построен на следующих репозиториях:


