DePT
1.0.0
이 저장소는 Dept : Dept : Parameter 효율적인 미세 조정을위한 분해 된 프롬프트 튜닝 코드에 대한 코드를 제공하여 코드 기여를 다른 프로젝트에 통합 할 수 있도록합니다.
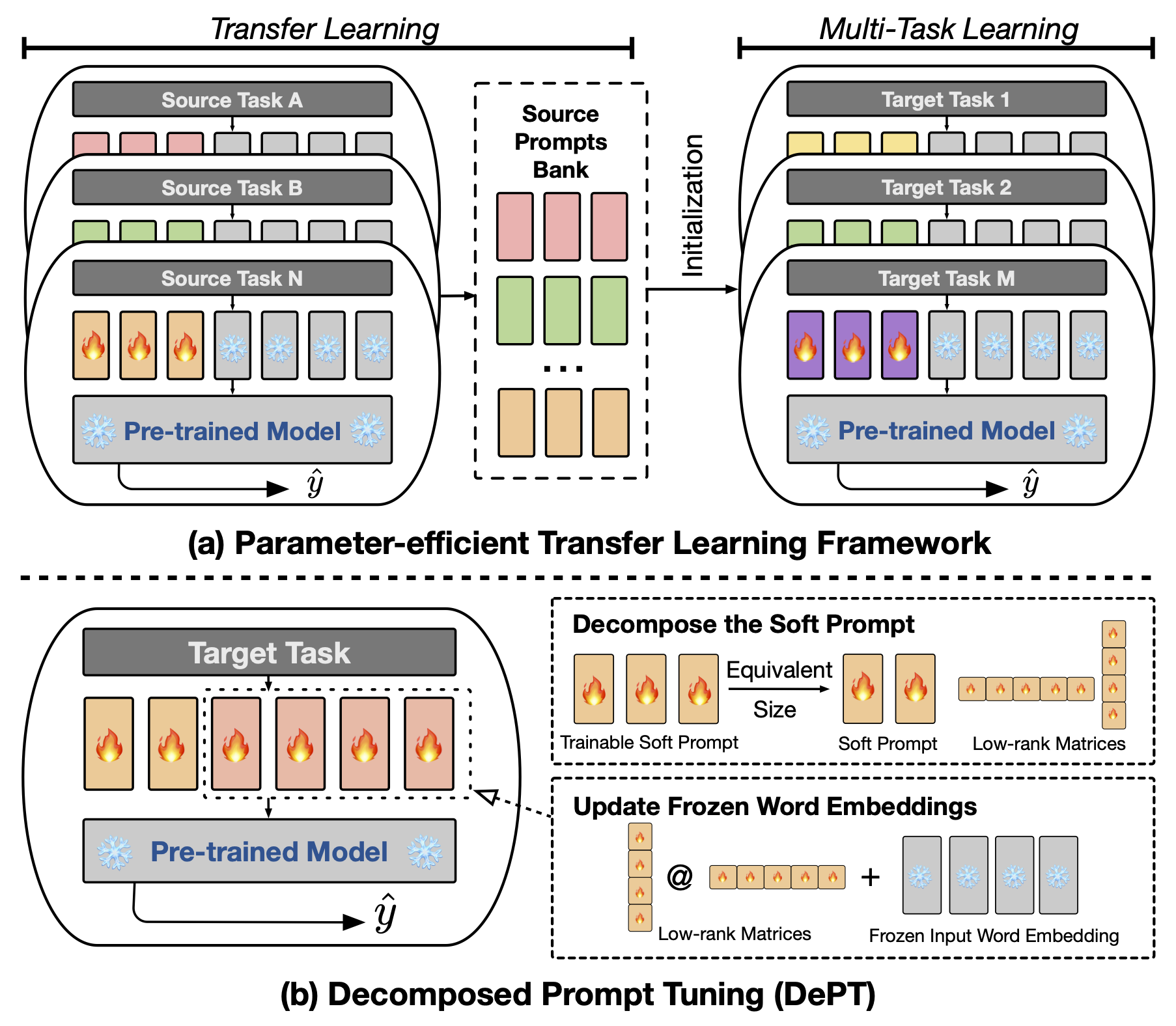
MODEL 설정하십시오.파라미터 효율적인 미세 조정을위한 분해 된 프롬프트 튜닝 : 분해 된 프롬프트 튜닝의 실험을 재현 할 수 있습니다.
소량의 훈련 가능한 소프트 (연속) 프롬프트 벡터가 언어 모델 (LM)의 입력에 부착 된 초록 프롬프트 튜닝 (PT)은 매개 변수 효율적인 미세 조정 (PEFT)에 대한 다양한 작업 및 모델에서 유망한 결과를 보여주었습니다. PT는 다른 PEFT 접근 방식에서 두드러집니다. 훈련 가능한 매개 변수가 적은 경쟁력을 유지하고 모델 크기가 확장됨에 따라 매개 변수를 크게 확장하지 않기 때문입니다. 그러나 PT는 추가 소프트 프롬프트 토큰을 도입하여 입력 시퀀스가 길어져 변압기의 2 차 복잡성으로 인해 훈련 및 추론 시간 및 메모리 사용에 큰 영향을 미칩니다. 특히 매일 쿼리가 심한 대형 언어 모델 (LLM)에 관한 것입니다. 이 문제를 해결하기 위해 소프트 프롬프트를 더 짧은 소프트 프롬프트로 분해하고 두 가지 다른 학습 속도로 최적화되는 저급 매트릭스 쌍으로 분해되는 분해 프롬프트 튜닝 (Dept)을 제안합니다. 이를 통해 DEPT는 더 나은 성능을 달성하면서 훈련 가능한 매개 변수 크기를 변경하지 않고 바닐라 PT 및 변형에 비해 상당한 메모리 및 시간 비용을 절약 할 수 있습니다. 23 개의 NLP (Natural Language Processing) 및 VL (Vision-Language) 작업에 대한 광범위한 실험을 통해 부서는 일부 시나리오에서 전체 미세 조정 기준을 포함한 최첨단 PEFT 접근 방식을 능가한다는 것을 보여줍니다. 또한, 우리는 모델 크기가 증가함에 따라 부서가 더 효율적임을 경험적으로 보여줍니다. 우리의 추가 연구에 따르면 Dept는 소수의 학습 환경에서 매개 변수 효율적인 전송 학습과 완벽하게 통합되며 다양한 모델 아키텍처 및 크기에 대한 적응성을 강조합니다.
프롬프트 기반 또는 CLS 기반 미세 조정을 실행하려면 다음 패키지를 설치해야합니다.
우리는 실험에서 다음 NLP 데이터 세트를 사용합니다 : Glue, SuperGlue, MRQA 2019 공유 작업, Winogrande, Yelp-2, Scitail 및 Paws-Wiki. 이러한 모든 데이터 세트는 Huggingface 데이터 세트에서 사용할 수 있으며 자동으로 다운로드 할 수 있습니다. 데이터 세트의 세부 사항은 src/tasks.py 파일을 참조하십시오.
우리는 논문의 주요 실험을 재현하기위한 스크립트를 제공합니다. 예를 들어, 다음 스크립트를 실행하여 접착제 데이터 세트에서 부서 결과를 재현 할 수 있습니다. PREFIX_LENGTH 는 용지에서 소프트 프롬프트 m 의 길이를 나타냅니다. R 은 용지에서 저 순위 행렬 r 의 순위를 나타냅니다. lr 은 소프트 프롬프트의 학습 속도이며 LORA_LR 냉동 단어 임베딩에 추가 될 저급 행렬 쌍의 학습 속도입니다.
MODEL=t5-base
MAX_LENGTH=256
MAX_STEPS=40000
PREFIX_LENGTH=40
R=45
for TASK_NAME in cola mrpc mnli qnli qqp rte sst2 stsb ; do
for LORA_LR in 5e-3 3e-1 5e-4 ; do
for lr in 3e-1 4e-1 ; do
CUDA_VISIBLE_DEVICES=0 python train.py
--peft_type PROMPT_TUNING_LORA
--lora_embedding_lr ${LORA_LR}
--learning_rate ${lr}
--prefix_length ${PREFIX_LENGTH}
--r ${R}
--task_name ${TASK_NAME}
--dataset_config_name en
--model_name_or_path ${MODEL}
--do_train
--do_eval
--do_predict
--per_device_train_batch_size 32
--per_device_eval_batch_size 32
--max_seq_length ${MAX_LENGTH}
--save_strategy steps
--evaluation_strategy steps
--max_steps ${MAX_STEPS}
--eval_steps 1000
--save_steps 1000
--warmup_steps 500
--weight_decay 1e-5
--load_best_model_at_end
--save_total_limit 1
--output_dir saved_ ${MODEL} / ${TASK_NAME} _lr ${lr} _loralr ${LORA_LR} _pl ${PREFIX_LENGTH} _r ${R} _st ${MAX_STEPS} ;
done ;
done ;
done TASK_NAME superglue-multirc superglue-wic superglue-wsc.fixed superglue-cb superglue-boolq SuperGlue 벤치 마크, MRQA 2019 공유 작업을위한 newsqa searchqa hotpotqa nq 위한 SuperGlue-CB SuperGlue-Boolq, Winogrande 데이터 세트, Winogrande의 winogrande , yelp_polarity for the Scitaile, 및 Scitaile, and the Scitaile, scitail Scitaile, and the Scital. Paws-Wiki 데이터 세트의 paws .
또한, 인수 --peft_model_id 추가하여 소프트 프롬프트와 저택 행렬 쌍을 초기 프롬프트 벡터로 초기화 할 수 있습니다. 인수 --k_shot_examples 추가하여 소수의 학습에 사용되는 예제 수를 지정할 수 있습니다.
우리가 논문에서 혐오감을 느끼면서,이 작업 의 잠재적 한계 중 하나는 튜닝을위한 추가 과다 모수를 도입하는 것입니다. 이것은 모델 훈련의 과다 파라미터 최적화 단계에서 일부 추가 계산 오버 헤드를 소개 할 수 있습니다. 최적의 성능을 얻으려면 이러한 과부색 변수 미터를 검색하는 것이 중요합니다. 10 만 개 이상의 교육 예제가있는 대형 데이터 세트의 경우, 우리는 이전 작업 (Vu et al., 2022)을 따라 제안 된 방법 부서를 최대 300,000 단계로 훈련시킵니다. 더 많은 단계를 훈련하면 대규모 데이터 세트의 성능을 향상시키는 데 도움이됩니다. 또한 소프트 프롬프트의 길이가 감소함에 따라 하이퍼 파라미터 검색을 수행하는 데 더 많은 노력이 필요할 수 있습니다. 일반적으로 길이 PREFIX_LENGTH 로 40 또는 60 으로 소프트 프롬프트를 사용하는 것은 정상입니다. PETL (Parameter 효율적인 전송 학습)을 사용하면 초 파라미터 검색의 노력을 줄이는 데 도움이 될 수 있습니다. 그러나 모델 교육 프로세스는 일회성 이벤트이며 모델 추론은 그렇지 않습니다. 이와 관련하여, 부서의 효율성 혜택은 추론 중에 특히 가치가 있습니다.
코드 나 논문에 관한 궁금한 점이 있으면 [email protected] 의 Zhengxiang에 문의하십시오. 코드를 사용하는 동안 어려움을 겪거나 버그를보고 해야하는 경우 자유롭게 문제를여십시오. 우리는 효과적인 지원을 제공하는 데 도움이되는 문제에 대한 자세한 정보를 제공하도록 친절하게 요청합니다.
@inproceedings{shi2024dept,
title={DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning},
author={Zhengxiang Shi and Aldo Lipani},
booktitle={International Conference on Learning Representations},
year={2024},
url={http://arxiv.org/abs/2309.05173}
}
이 저장소는 다음 리포지토리를 기반으로합니다.


