DePT
1.0.0
Este repositorio proporciona el código para el documento titulado Dept: ajuste de inmediato descompuesto para el ajuste fino de los parámetros , lo que hace que la integración de nuestras contribuciones de código en otros proyectos sea más accesible.
MODEL en su ruta LLAMA-2 local para ejecutar los experimentos.Puede reproducir los experimentos de nuestro departamento de papel: ajuste de inmediato descompuesto para el ajuste fino de los parámetros.
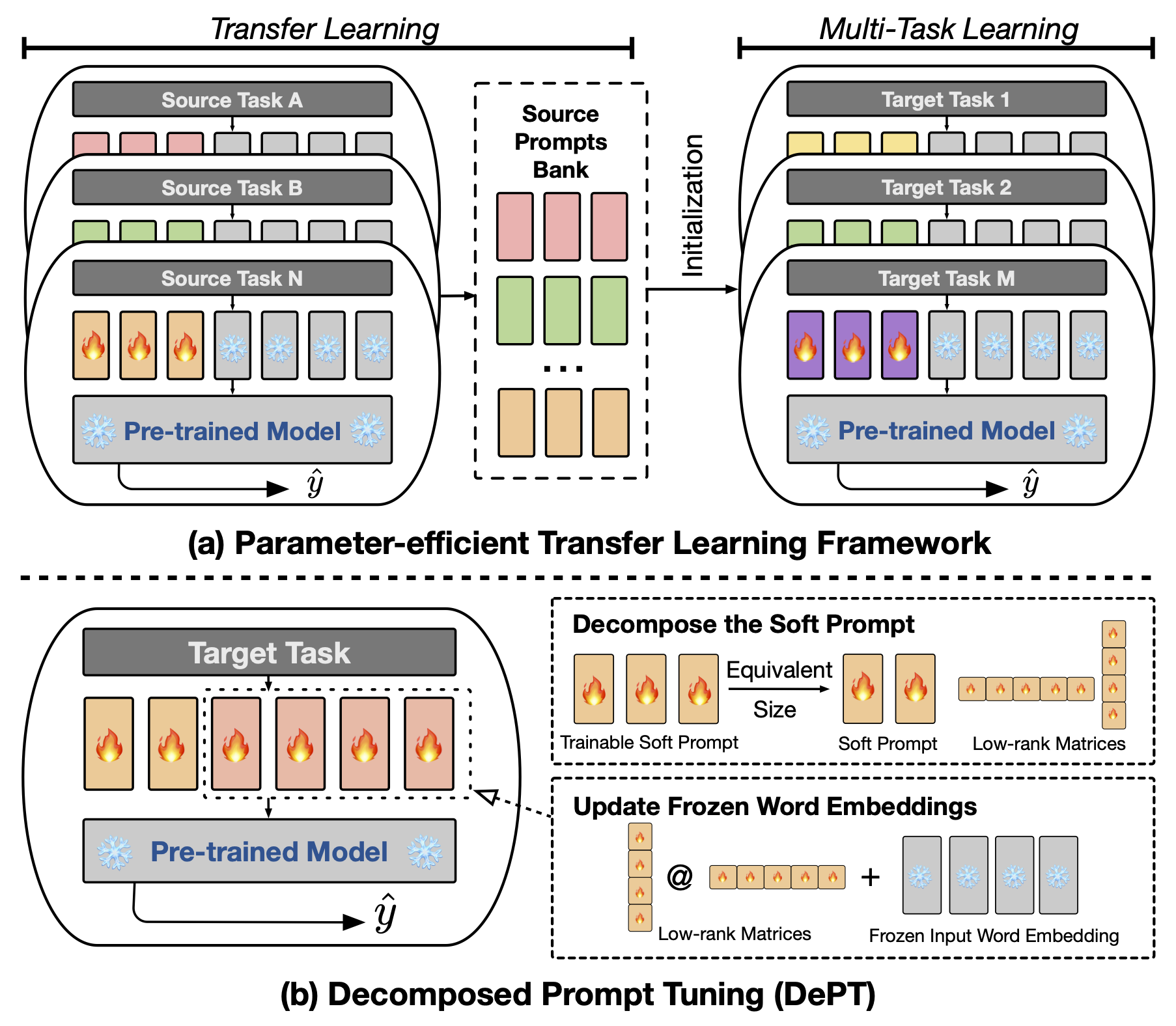
El ajuste de solicitud abstracto (PT), donde una pequeña cantidad de vectores de inmediato suaves (continuos) entrenables se fija a la entrada de modelos de lenguaje (LM), ha mostrado resultados prometedores en varias tareas y modelos para el ajuste fino de los parámetros (PEFT). PT se destaca de otros enfoques de PEFF porque mantiene un rendimiento competitivo con menos parámetros capacitables y no amplía drásticamente sus parámetros a medida que se expande el tamaño del modelo. Sin embargo, PT introduce tokens de inmediato suave adicionales, lo que lleva a secuencias de entrada más largas, lo que afecta significativamente el entrenamiento y el tiempo de inferencia y el uso de la memoria debido a la complejidad cuadrática del transformador. Particularmente preocupante para modelos de idiomas grandes (LLM) que enfrentan una fuerte consulta diaria. Para abordar este problema, proponemos un ajuste de inmediato descompuesto (departamento), que descompone el aviso suave en un aviso suave más corto y un par de matrices de bajo rango que luego se optimizan con dos tasas de aprendizaje diferentes. Esto permite a Dept lograr un mejor rendimiento al tiempo que ahorra la memoria y los costos de tiempo sustanciales en comparación con el PT de vainilla y sus variantes, sin cambiar los tamaños de parámetros capacitables. A través de extensos experimentos sobre 23 tareas de procesamiento del lenguaje natural (PNL) y lenguaje de visión (VL), demostramos que el departamento superan los enfoques de PEFT de última generación, incluida la línea de base completa de ajuste fino, en algunos escenarios. Además, mostramos empíricamente que el departamento se vuelve más eficiente a medida que aumenta el tamaño del modelo. Nuestro estudio adicional revela que el departamento se integra a la perfección con el aprendizaje de transferencia de parámetros-eficiente en la configuración de aprendizaje de pocos disparos y destaca su adaptabilidad a diversas arquitecturas y tamaños de modelos.
Para ejecutar el ajuste fino basado en el aviso o basado en CLS, debe instalar los siguientes paquetes.
Utilizamos los siguientes conjuntos de datos NLP en nuestros experimentos: Glue, Supergeglue, MRQA 2019 Tarea compartida, Winogrande, Yelp-2, Scitail y Paws-Wiki. Todos estos conjuntos de datos están disponibles en los conjuntos de datos Huggingface y se pueden descargar automáticamente. Consulte el archivo src/tasks.py para obtener los detalles de los conjuntos de datos.
Proporcionamos los guiones para reproducir los principales experimentos en nuestro artículo. Por ejemplo, puede ejecutar el siguiente script para reproducir los resultados del departamento en el conjunto de datos de pegamento. El PREFIX_LENGTH representa la longitud del indicador suave m en el papel. El R representa el rango de matrices de bajo rango r en el papel. lr es la tasa de aprendizaje para el aviso suave, y LORA_LR es la tasa de aprendizaje para el par de las matrices de bajo rango que se agregarán a las incrustaciones de palabras congeladas.
MODEL=t5-base
MAX_LENGTH=256
MAX_STEPS=40000
PREFIX_LENGTH=40
R=45
for TASK_NAME in cola mrpc mnli qnli qqp rte sst2 stsb ; do
for LORA_LR in 5e-3 3e-1 5e-4 ; do
for lr in 3e-1 4e-1 ; do
CUDA_VISIBLE_DEVICES=0 python train.py
--peft_type PROMPT_TUNING_LORA
--lora_embedding_lr ${LORA_LR}
--learning_rate ${lr}
--prefix_length ${PREFIX_LENGTH}
--r ${R}
--task_name ${TASK_NAME}
--dataset_config_name en
--model_name_or_path ${MODEL}
--do_train
--do_eval
--do_predict
--per_device_train_batch_size 32
--per_device_eval_batch_size 32
--max_seq_length ${MAX_LENGTH}
--save_strategy steps
--evaluation_strategy steps
--max_steps ${MAX_STEPS}
--eval_steps 1000
--save_steps 1000
--warmup_steps 500
--weight_decay 1e-5
--load_best_model_at_end
--save_total_limit 1
--output_dir saved_ ${MODEL} / ${TASK_NAME} _lr ${lr} _loralr ${LORA_LR} _pl ${PREFIX_LENGTH} _r ${R} _st ${MAX_STEPS} ;
done ;
done ;
done You can replace the TASK_NAME with superglue-multirc superglue-wic superglue-wsc.fixed superglue-cb superglue-boolq for the SuperGLUE benchmark, newsqa searchqa hotpotqa nq for the MRQA 2019 Shared Task, winogrande for the WinoGrande dataset, yelp_polarity for the Yelp-2 dataset, scitail for the SciTail dataset, and paws para el conjunto de datos de patas de patas.
Además, puede agregar el argumento --peft_model_id para inicializar el indicador suave y el par de matrices de bajo rango con los vectores de inmediato previos a los vectores. Puede agregar el argumento --k_shot_examples para especificar el número de ejemplos utilizados para el aprendizaje de pocos disparos.
A medida que dictaminamos en el documento, una de las limitaciones potenciales de este trabajo es la introducción de hiperparámetros adicionales para el ajuste, por ejemplo , la tasa de aprendizaje de las matrices de bajo rango y los pasos de entrenamiento. Esto podría introducir una sobrecarga computacional adicional durante la fase de optimización de hiperparameter del entrenamiento modelo. Es importante buscar en todos estos hiperparámetros para obtener el rendimiento óptimo. Para el gran conjunto de datos con más de 100,000 ejemplo de entrenamiento, seguimos el trabajo anterior (Vu et al., 2022) para capacitar nuestro departamento de método propuesto con hasta 300,000 pasos. Entrenar más pasos es útil para mejorar el rendimiento en los grandes conjuntos de datos. Aditonalmente, a medida que disminuye la longitud de las indicaciones suaves, puede requerir más esfuerzos para realizar la búsqueda de hiperparameter. Por lo general, el uso del indicador suave con la longitud PREFIX_LENGTH como 40 o 60 debería estar bien. El uso de aprendizaje de transferencia de parámetros-eficiente (PETL) puede ser útil para reducir los esfuerzos para la búsqueda de hiperparameter. Sin embargo, es importante tener en cuenta que el proceso de capacitación del modelo es un evento único, mientras que la inferencia del modelo no lo es. En este contexto, los beneficios de eficiencia del departamento se vuelven especialmente valiosos durante la inferencia.
Si tiene alguna pregunta sobre el código o el documento, no dude en comunicarse con Zhengxiang en [email protected] . Si experimenta alguna dificultad mientras usa el código o necesita informar un error, no dude en abrir un problema. Pedimos amablemente que proporcione información detallada sobre el problema para ayudarnos a proporcionar un soporte efectivo.
@inproceedings{shi2024dept,
title={DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning},
author={Zhengxiang Shi and Aldo Lipani},
booktitle={International Conference on Learning Representations},
year={2024},
url={http://arxiv.org/abs/2309.05173}
}
Este repositorio se basa en los siguientes repositorios:


