DePT
1.0.0
该存储库提供了标题为“ Dept:分解的及时调整”的论文代码,以进行参数有效调整,从而使我们的代码贡献集成到其他项目中。
MODEL设置为您本地的Llama-2路径以运行实验。您可以重现我们论文部的实验:分解的及时调整以进行参数有效调整。
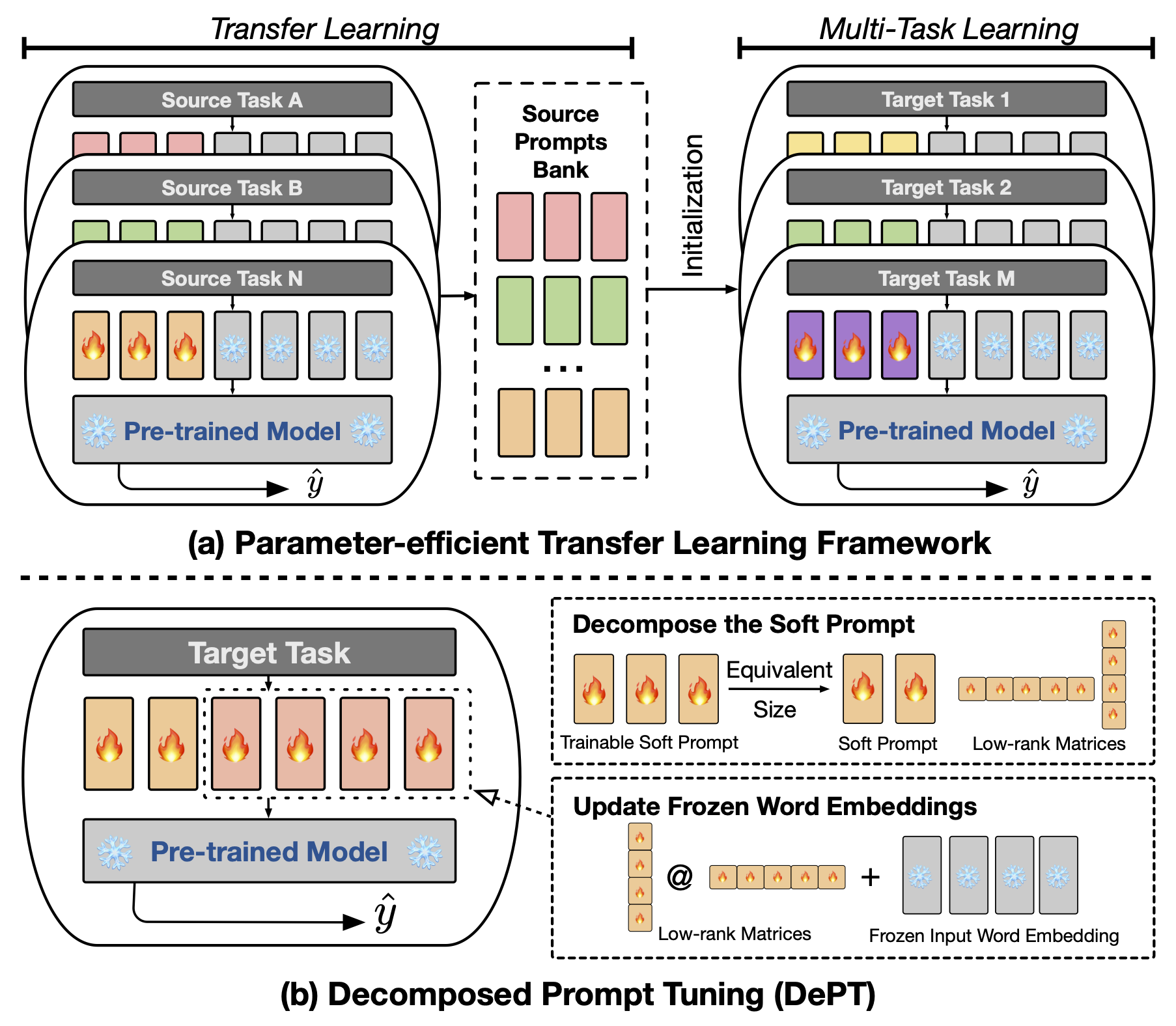
抽象提示调整(PT),其中少量可训练的软(连续)提示向量固定在语言模型的输入中,它显示了各种任务和模型的有希望的结果,用于参数有效的微调(PEFT)。 PT从其他PEFT方法中脱颖而出,因为它以更少的可训练参数保持竞争性能,并且随着模型大小的扩展,它不会大大扩展其参数。但是,PT引入了额外的软提示令牌,导致输入序列更长,这显着影响训练,推理时间和记忆使用,这是由于变压器的二次复杂性。特别是针对每日大量查询的大型语言模型(LLM)。为了解决这个问题,我们提出了分解的提示调整(DEPT),将软提示分解为较短的软提示和一对低级矩阵,然后通过两个不同的学习率进行了优化。与Vanilla PT及其变体相比,这使该部门能够实现更好的性能,同时节省大量的内存和时间成本,而无需更改可训练的参数尺寸。通过对23种自然语言处理(NLP)和视觉语言(VL)任务进行的广泛实验,我们证明在某些情况下,部门的表现优于最先进的PEFT方法,包括完整的微调基线。此外,我们从经验上表明,随着模型大小的增加,部门的效率更加有效。我们的进一步研究表明,部门与参数有效的转移学习无缝地集成在几个图中,并突出了其对各种模型体系结构和大小的适应性。
要运行基于及时或基于CLS的微调,您需要安装以下软件包。
我们在实验中使用以下NLP数据集:胶水,Superglue,MRQA 2019共享任务,Winogrande,Yelp-2,Scitail和Paws Wiki。所有这些数据集都在HuggingFace数据集中可用,可以自动下载。有关数据集的详细信息,请参考文件src/tasks.py 。
我们提供脚本来复制论文中的主要实验。例如,您可以运行以下脚本来重现胶数据集上的部门的结果。 PREFIX_LENGTH表示纸张中软提示m的长度。 R代表纸张中低级矩阵r的等级。 lr是软提示的学习率,而LORA_LR是将添加到冷冻单词嵌入中的低级矩阵的学习率。
MODEL=t5-base
MAX_LENGTH=256
MAX_STEPS=40000
PREFIX_LENGTH=40
R=45
for TASK_NAME in cola mrpc mnli qnli qqp rte sst2 stsb ; do
for LORA_LR in 5e-3 3e-1 5e-4 ; do
for lr in 3e-1 4e-1 ; do
CUDA_VISIBLE_DEVICES=0 python train.py
--peft_type PROMPT_TUNING_LORA
--lora_embedding_lr ${LORA_LR}
--learning_rate ${lr}
--prefix_length ${PREFIX_LENGTH}
--r ${R}
--task_name ${TASK_NAME}
--dataset_config_name en
--model_name_or_path ${MODEL}
--do_train
--do_eval
--do_predict
--per_device_train_batch_size 32
--per_device_eval_batch_size 32
--max_seq_length ${MAX_LENGTH}
--save_strategy steps
--evaluation_strategy steps
--max_steps ${MAX_STEPS}
--eval_steps 1000
--save_steps 1000
--warmup_steps 500
--weight_decay 1e-5
--load_best_model_at_end
--save_total_limit 1
--output_dir saved_ ${MODEL} / ${TASK_NAME} _lr ${lr} _loralr ${LORA_LR} _pl ${PREFIX_LENGTH} _r ${R} _st ${MAX_STEPS} ;
done ;
done ;
done You can replace the TASK_NAME with superglue-multirc superglue-wic superglue-wsc.fixed superglue-cb superglue-boolq for the SuperGLUE benchmark, newsqa searchqa hotpotqa nq for the MRQA 2019 Shared Task, winogrande for the WinoGrande dataset, yelp_polarity for the Yelp-2 dataset, scitail for the SciTail数据集和PAWS Wiki数据集的paws 。
此外,您可以添加参数--peft_model_id来初始化软提示,并使用预算的提示向量来初始化柔软的提示。您可以添加参数--k_shot_examples来指定用于几次学习的示例数量。
正如我们在论文中引起的那样,这项工作的潜在局限性之一是引入了用于调整的额外的超参数,例如,低级矩阵的学习率和训练步骤。这可能会在模型训练的超参数优化阶段引入一些其他计算开销。搜索所有这些超参数以获得最佳性能很重要。对于具有100,000多个培训示例的大型数据集,我们遵循先前的工作(Vu等,2022),以最多300,000步培训我们提出的方法部门。培训更多步骤有助于提高大型数据集的性能。随着软提示的长度减少,可以进行超参数搜索,这可能需要更多的努力。通常,使用PREFIX_LENGTH的软提示为40或60 。使用参数有效的转移学习(PETL)可能有助于减少超参数搜索的努力。但是,重要的是要注意,模型训练过程是一次性事件,而模型推断不是。在这种情况下,在推断期间,部门的效率优势变得特别有价值。
如果您对代码或论文有任何疑问,请随时通过[email protected]与Zhengxiang联系。如果您在使用代码时遇到任何困难或需要报告错误,请随时打开问题。我们请要求您提供有关问题的详细信息,以帮助我们提供有效的支持。
@inproceedings{shi2024dept,
title={DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning},
author={Zhengxiang Shi and Aldo Lipani},
booktitle={International Conference on Learning Representations},
year={2024},
url={http://arxiv.org/abs/2309.05173}
}
该存储库建立在以下存储库上:


