DePT
1.0.0
Ce référentiel fournit le code pour l'article intitulé Dept: Détrage invite en décomposé pour un réglage fin économe en paramètres , rendant l'intégration de nos contributions de code dans d'autres projets plus accessibles.
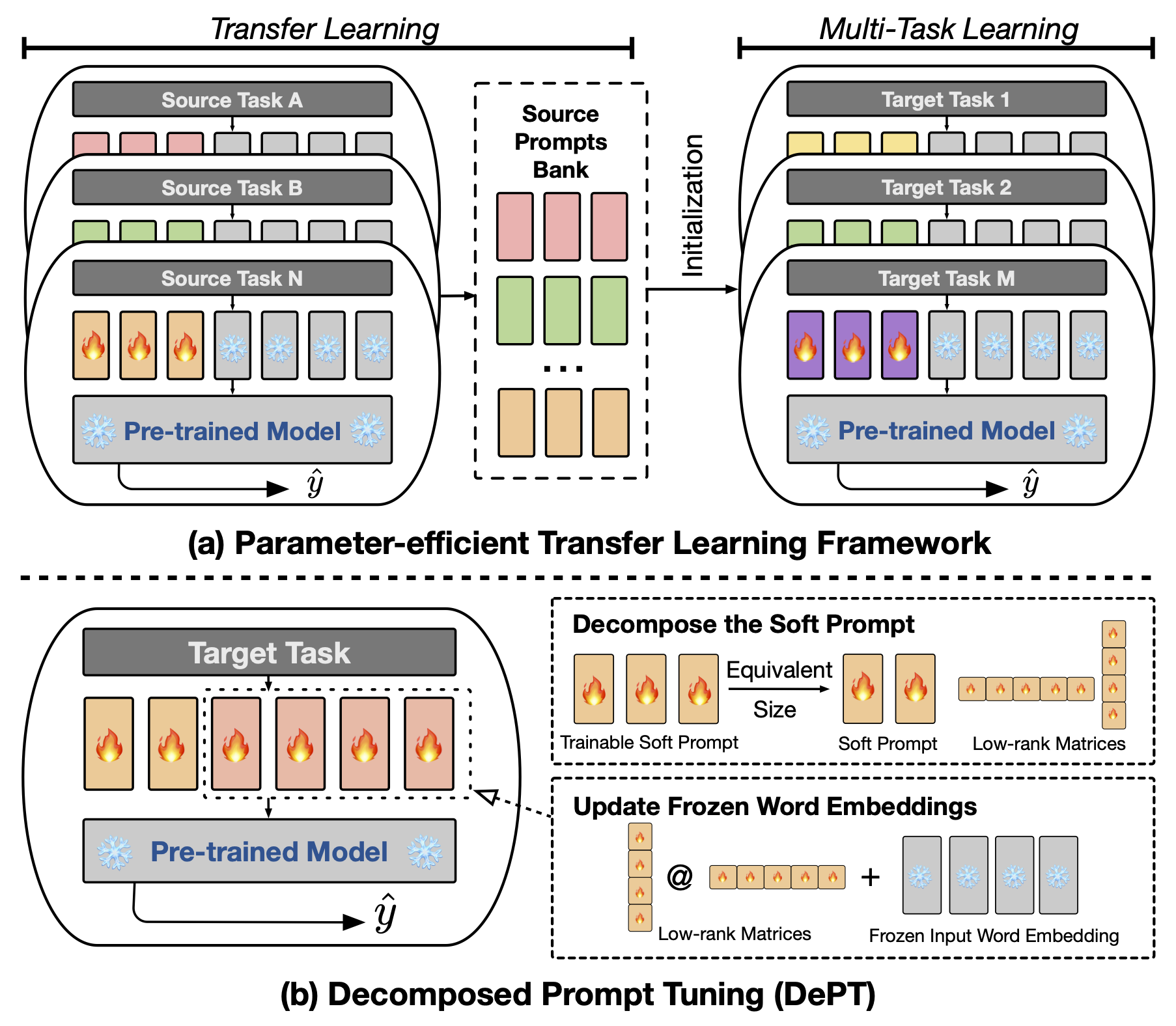
MODEL sur votre chemin LLAMA-2 local pour exécuter les expériences.Vous pouvez reproduire les expériences de notre département de papier: réglage rapide décomposé pour un réglage fin économe en paramètres.
Le réglage invite (PT) abstrait , où une petite quantité de vecteurs invites softs (continus) formables est fixée à l'entrée des modèles de langage (LM), a montré des résultats prometteurs entre diverses tâches et modèles pour le réglage fin et efficace par les paramètres (PEFT). PT se démarque des autres approches PEFT car elle maintient des performances concurrentielles avec moins de paramètres formables et n'étend pas radicalement ses paramètres à mesure que la taille du modèle se développe. Cependant, PT introduit des jetons invites softs supplémentaires, conduisant à des séquences d'entrée plus longues, ce qui a un impact significatif sur la formation et le temps d'inférence et l'utilisation de la mémoire en raison de la complexité quadratique du transformateur. Particulièrement concernant les modèles de grands langues (LLM) qui sont confrontés à une requête quotidienne lourde. Pour résoudre ce problème, nous proposons un réglage rapide décomposé (département), qui décompose l'invite douce dans une invite douce plus courte et une paire de matrices de bas rang qui sont ensuite optimisées avec deux taux d'apprentissage différents. Cela permet au département d'obtenir de meilleures performances tout en économisant des coûts de mémoire et des temps substantiels par rapport à la vanille PT et à ses variantes, sans modifier les tailles de paramètres formables. Grâce à de vastes expériences sur 23 tâches de traitement du langage naturel (NLP) et de langue de vision (VL), nous démontrons que le département surpasse les approches de pointe de pointe, y compris la ligne de base à réglage fin complet, dans certains scénarios. De plus, nous montrons empiriquement que le département devient plus efficace à mesure que la taille du modèle augmente. Notre étude plus approfondie révèle que le département s'intègre parfaitement à l'apprentissage du transfert économe en paramètres dans le cadre d'apprentissage à quelques coups et met en évidence son adaptabilité à diverses architectures et tailles de modèle.
Pour exécuter le réglage fin basé sur l'invite ou basé sur CLS, vous devez installer les packages suivants.
Nous utilisons les ensembles de données NLP suivants dans nos expériences: Glue, Superglue, MRQA 2019 Tâche partagée, Winogrande, Yelp-2, Scitail et Paws-Wiki. Tous ces ensembles de données sont disponibles dans les ensembles de données HuggingFace et peuvent être téléchargés automatiquement. Veuillez vous référer au fichier src/tasks.py pour les détails des ensembles de données.
Nous fournissons les scripts pour reproduire les principales expériences de notre article. Par exemple, vous pouvez exécuter le script suivant pour reproduire les résultats du département sur l'ensemble de données de colle. Le PREFIX_LENGTH représente la longueur de l'invite molle m dans le papier. Le R représente le rang des matrices de bas rang r dans le papier. lr est le taux d'apprentissage de l'invite souple, et LORA_LR est le taux d'apprentissage de la paire des matrices de bas rang qui seront ajoutées aux incorporations de mots gelées.
MODEL=t5-base
MAX_LENGTH=256
MAX_STEPS=40000
PREFIX_LENGTH=40
R=45
for TASK_NAME in cola mrpc mnli qnli qqp rte sst2 stsb ; do
for LORA_LR in 5e-3 3e-1 5e-4 ; do
for lr in 3e-1 4e-1 ; do
CUDA_VISIBLE_DEVICES=0 python train.py
--peft_type PROMPT_TUNING_LORA
--lora_embedding_lr ${LORA_LR}
--learning_rate ${lr}
--prefix_length ${PREFIX_LENGTH}
--r ${R}
--task_name ${TASK_NAME}
--dataset_config_name en
--model_name_or_path ${MODEL}
--do_train
--do_eval
--do_predict
--per_device_train_batch_size 32
--per_device_eval_batch_size 32
--max_seq_length ${MAX_LENGTH}
--save_strategy steps
--evaluation_strategy steps
--max_steps ${MAX_STEPS}
--eval_steps 1000
--save_steps 1000
--warmup_steps 500
--weight_decay 1e-5
--load_best_model_at_end
--save_total_limit 1
--output_dir saved_ ${MODEL} / ${TASK_NAME} _lr ${lr} _loralr ${LORA_LR} _pl ${PREFIX_LENGTH} _r ${R} _st ${MAX_STEPS} ;
done ;
done ;
done Vous pouvez remplacer le TASK_NAME par superglue-multirc superglue-wic superglue-wsc.fixed superglue-cb superglue-boolq pour la référence Superglue, newsqa searchqa hotpotqa nq pour la MRQA 2019 Task partagée, winogrande pour le jeu de données Winogrande, le yelp_polarity de données SCITAIL pour le DataSet Yelp-2, scitail pour le SCITAIL TETAL paws pour l'ensemble de données Paws-Wiki.
De plus, vous pouvez ajouter l'argument --peft_model_id pour initialiser l'invite douce et la paire de matrices de bas rang avec les vecteurs d'invite pré-entraînés. Vous pouvez ajouter l'argument --k_shot_examples pour spécifier le nombre d'exemples utilisés pour l'apprentissage à quelques coups.
Comme nous l'avons dicussé dans le document, l'une des limites potentielles de ce travail est l'introduction d'hyperparamètres supplémentaires pour le réglage, par exemple , le taux d'apprentissage des matrices et étapes de formation de faible rang. Cela pourrait introduire quelques frais généraux supplémentaires pendant la phase d'optimisation de l'hyperparamètre de la formation des modèles. Il est important de rechercher tous ces hyperparamètres pour obtenir les performances optimales. Pour le grand ensemble de données avec plus de 100 000 exemple de formation, nous suivons les travaux antérieurs (Vu et al., 2022) pour former notre département de méthode proposé avec jusqu'à 300 000 étapes. La formation de plus d'étapes est utile pour améliorer les performances des grands ensembles de données. De plus, à mesure que la longueur des invites souples diminue, cela peut prendre plus d'efforts pour effectuer la recherche hyperparamètre. En règle générale, l'utilisation de l'invite souple avec la longueur PREFIX_LENGTH en tant que 40 ou 60 devrait être bien. L'utilisation de l'apprentissage par transfert économe en paramètres (PETL) peut être utile pour réduire les efforts pour la recherche d'hyperparamètre. Cependant, il est important de noter que le processus de formation du modèle est un événement unique, alors que l'inférence du modèle ne l'est pas. Dans ce contexte, les avantages de l'efficacité du département deviennent particulièrement précieux pendant l'inférence.
Si vous avez des questions concernant le code ou le journal, n'hésitez pas à contacter Zhengxiang à [email protected] . Si vous rencontrez des difficultés tout en utilisant le code ou devez signaler un bogue, n'hésitez pas à ouvrir un problème. Nous vous demandons de fournir des informations détaillées sur le problème pour nous aider à fournir un soutien efficace.
@inproceedings{shi2024dept,
title={DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning},
author={Zhengxiang Shi and Aldo Lipani},
booktitle={International Conference on Learning Representations},
year={2024},
url={http://arxiv.org/abs/2309.05173}
}
Ce référentiel est construit sur les référentiels suivants:


