DePT
1.0.0
このリポジトリは、パラメーター効率の高い微調整のために、Dept:Decomposed Prompt Tuningというタイトルの論文のコードを提供し、他のプロジェクトへのコード貢献の統合をよりアクセスしやすくします。
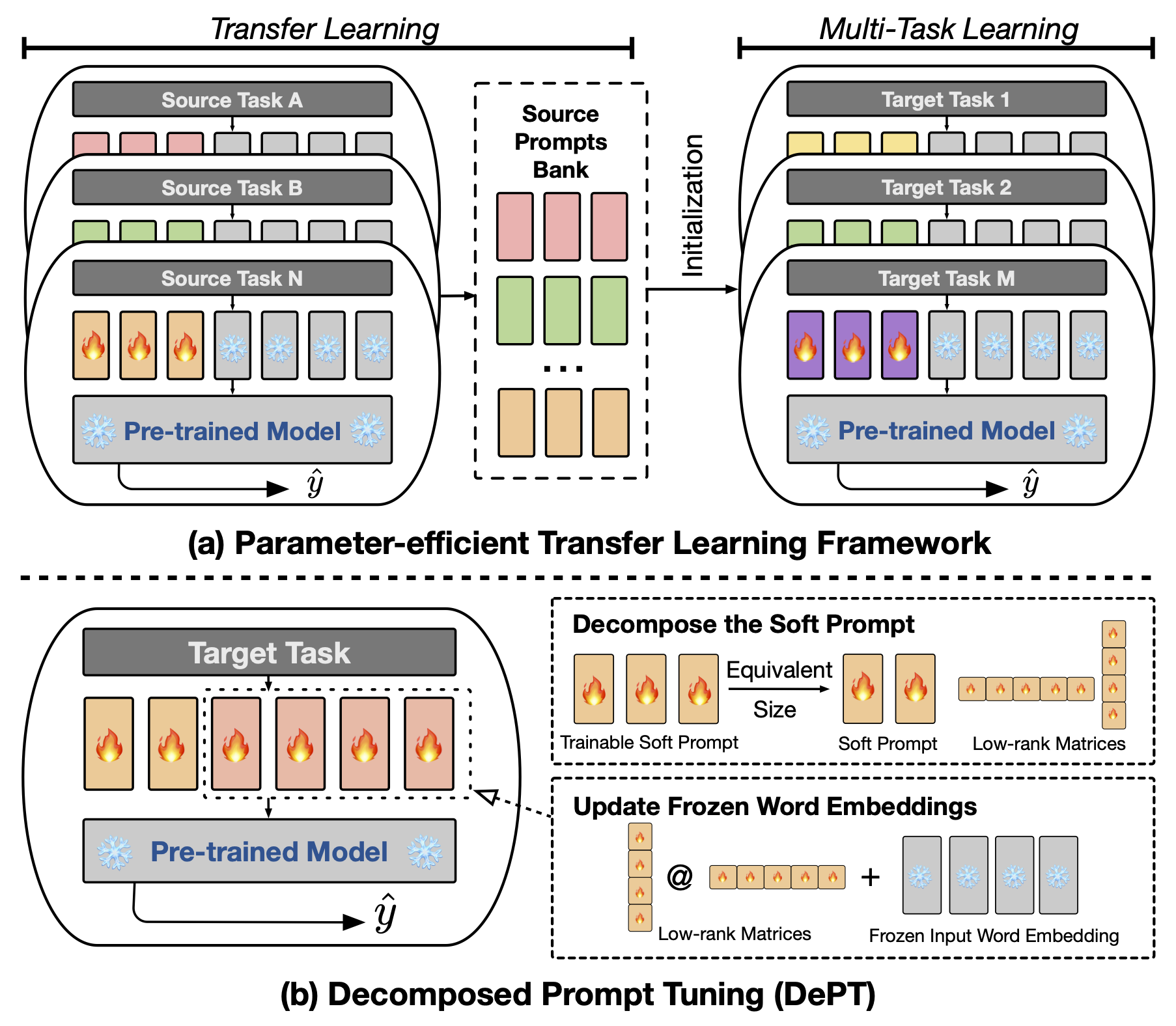
MODELを設定してください。紙部の実験を再現できます。パラメーター効率の高い微調整の分解されたプロンプトチューニング。
要約プロンプトチューニング(PT)(PT)は、言語モデル(LM)の入力に少量のトレーニング可能なソフト(連続)プロンプトベクトルが貼られており、パラメーター効率の高い微調整(PEFT)のさまざまなタスクとモデルで有望な結果を示しています。 PTは、より少ないトレーニング可能なパラメーターで競争力のあるパフォーマンスを維持し、モデルサイズが拡大するにつれてパラメーターを大幅に拡大しないため、他のPEFTアプローチから際立っています。ただし、PTは追加のソフトプロンプトトークンを導入し、より長い入力シーケンスにつながります。これは、変圧器の二次の複雑さによるトレーニングと推論の時間とメモリの使用に大きく影響します。特に、毎日の重いクエリに直面している大規模な言語モデル(LLM)の場合。この問題に対処するために、分解されたプロンプトチューニング(Dept)を提案します。これにより、ソフトプロンプトをより短いソフトプロンプトと2つの異なる学習レートで最適化される低ランクマトリックスのペアに分解します。これにより、Deptは、トレーニング可能なパラメーターサイズを変更することなく、バニラPTとそのバリアントに比べてかなりのメモリと時間コストを節約しながら、より良いパフォーマンスを達成できます。 23の自然言語処理(NLP)およびビジョン言語(VL)タスクに関する広範な実験を通じて、一部のシナリオでは、完全な微調整ベースラインを含む最先端のPEFTアプローチを上回ることを実証します。さらに、モデルサイズが増加するにつれて、部門がより効率的になることを経験的に示します。私たちのさらなる研究は、Deptが少数のショット学習設定でパラメーター効率の高い転送学習とシームレスに統合し、さまざまなモデルアーキテクチャやサイズへの適応性を強調することを明らかにしています。
プロンプトベースまたはCLSベースの微調整を実行するには、次のパッケージをインストールする必要があります。
実験では、次のNLPデータセットを使用します:接着剤、スーパーグルー、MRQA 2019共有タスク、Winogrande、Yelp-2、Scitail、Paws-Wiki。これらのすべてのデータセットは、Huggingfaceデータセットで利用でき、自動的にダウンロードできます。データセットの詳細については、ファイルsrc/tasks.pyを参照してください。
私たちの論文で主な実験を再現するためのスクリプトを提供します。たとえば、次のスクリプトを実行して、接着剤データセットにDeptの結果を再現できます。 PREFIX_LENGTH 、ペーパー内のソフトプロンプトmの長さを表します。 Rは、論文の低ランクマトリックスrのランクを表します。 lrはソフトプロンプトの学習率であり、 LORA_LR 、冷凍単語の埋め込みに追加される低ランクマトリックスのペアの学習率です。
MODEL=t5-base
MAX_LENGTH=256
MAX_STEPS=40000
PREFIX_LENGTH=40
R=45
for TASK_NAME in cola mrpc mnli qnli qqp rte sst2 stsb ; do
for LORA_LR in 5e-3 3e-1 5e-4 ; do
for lr in 3e-1 4e-1 ; do
CUDA_VISIBLE_DEVICES=0 python train.py
--peft_type PROMPT_TUNING_LORA
--lora_embedding_lr ${LORA_LR}
--learning_rate ${lr}
--prefix_length ${PREFIX_LENGTH}
--r ${R}
--task_name ${TASK_NAME}
--dataset_config_name en
--model_name_or_path ${MODEL}
--do_train
--do_eval
--do_predict
--per_device_train_batch_size 32
--per_device_eval_batch_size 32
--max_seq_length ${MAX_LENGTH}
--save_strategy steps
--evaluation_strategy steps
--max_steps ${MAX_STEPS}
--eval_steps 1000
--save_steps 1000
--warmup_steps 500
--weight_decay 1e-5
--load_best_model_at_end
--save_total_limit 1
--output_dir saved_ ${MODEL} / ${TASK_NAME} _lr ${lr} _loralr ${LORA_LR} _pl ${PREFIX_LENGTH} _r ${R} _st ${MAX_STEPS} ;
done ;
done ;
done TASK_NAME newsqa searchqa hotpotqa nq superglue-multirc superglue-wic superglue-wsc.fixed superglue-cb superglue-boolqにwinogrande yelp_polarityができscitail 。 Paws-Wikiデータセットのpaws 。
さらに、引数--peft_model_idを追加して、ソフトプロンプトと低ランクマトリックスのペアを、前処理されたプロンプトベクトルで初期化できます。引数--k_shot_examplesを追加して、少数のショット学習に使用される例の数を指定できます。
この作業の潜在的な制限の1つは、この作業の潜在的な制限の1つが、たとえば低ランクマトリックスとトレーニングステップの学習率を調整するための追加のハイパーパラメーターの導入です。これにより、モデルトレーニングのハイパーパラメーター最適化フェーズ中に追加の計算オーバーヘッドが導入される可能性があります。これらすべてのハイパーパラメーターを検索して、最適なパフォーマンスを得ることが重要です。 100,000を超えるトレーニングの例を備えた大規模なデータセットの場合、以前の作業(Vu et al。、2022)に従い、提案された方法を最大300,000ステップで訓練します。より多くの手順をトレーニングすることは、大規模なデータセットのパフォーマンスを改善するのに役立ちます。さらに、ソフトプロンプトの長さが減少すると、ハイパーパラメーター検索を実行するためにより多くの努力が必要になる場合があります。通常、長さのPREFIX_LENGTHでソフトプロンプトを40または60に使用すると問題ありません。パラメーター効率の高い転送学習(PETL)を使用することは、ハイパーパラメーター検索の努力を減らすのに役立ちます。ただし、モデルトレーニングプロセスは1回限りのイベントであり、モデル推論はそうではないことに注意することが重要です。これに関連して、Deptの効率の利点は、推論中に特に価値があります。
コードまたは論文に関してご質問がある場合は、 [email protected] ucl.ac.ukのZhengxiangにお気軽にお問い合わせください。コードを使用しているときに問題が発生したり、バグを報告する必要がある場合は、お気軽に問題を開いてください。問題に関する詳細な情報を提供して、効果的なサポートを提供するようお願いします。
@inproceedings{shi2024dept,
title={DePT: Decomposed Prompt Tuning for Parameter-Efficient Fine-tuning},
author={Zhengxiang Shi and Aldo Lipani},
booktitle={International Conference on Learning Representations},
year={2024},
url={http://arxiv.org/abs/2309.05173}
}
このリポジトリは、次のリポジトリの上に構築されています。


