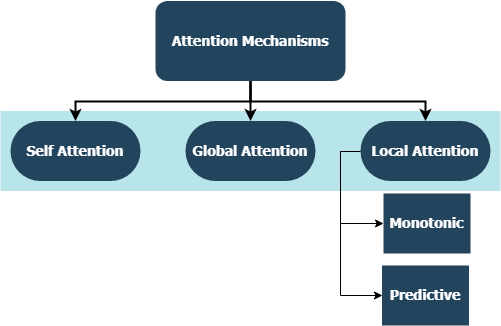
attention mechanisms
1.0.0
該存儲庫包括針對整個注意機制的自定義層實現,與Tensorflow和Keras集成兼容。注意機制改變了機器翻譯的景觀,它們在自然語言處理和理解的其他領域的利用日益日益增加。從廣義上講,它們旨在消除RNN中不利的壓縮和信息丟失。這些起源是由於通過序列到序列模型中復發層從輸入序列得出的隱藏狀態的固定長度編碼。該存儲庫中的層可用於多對多和多一對序列任務。應用程序包括情感分類,文本生成,機器翻譯和問題回答。還值得一提的是,該項目將很快被部署為Python包。檢查有關如何為該項目貢獻的貢獻小節。
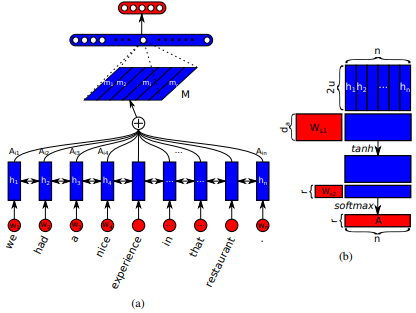
首先在長期短期內存網絡中引入了Jianpeng Cheng等人的機器閱讀。這個想法是基於以下論點,即從輸入序列衍生出的相同隱藏狀態空間的不同位置,即多個組件一起構成了序列的整體語義。這種方法通過多個啤酒花的注意將這些不同定位的信息匯總在一起。該特定的實現遵循Zhouhan Lin等人嵌入的結構化自我實踐句子。如果注意機制始終提供相似的註釋權重,則作者提出了額外的正規化損失度量,以防止嵌入矩陣的冗餘問題。
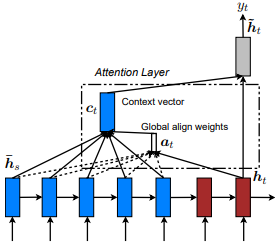
首先是通過共同學習與Dzmitry Bahdanau等人對齊和翻譯的首次引入的。這個想法是根據編碼器RNN的所有隱藏狀態得出上下文向量。因此,據說這種類型的注意力集中在整個輸入狀態空間上。
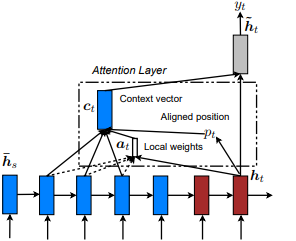
首次在節目中引入,參加和講述:Kelvin Xu等人的視覺關注的神經圖像字幕產生。並適用於NLP,以有效的方法對基於注意力的神經機器翻譯,由Minh-thang Luong等人。這個想法是通過關注從輸入序列得出的隱藏狀態集中的一小部分令狀子集來消除全球關注的細心成本。該窗口被提出為[p_t-D, p_t+D]其中D=width ,我們無視跨序列邊界的位置。對齊的位置p_t是通過A)單調對準決定的: set p_t=t或b)預測性一致性:set p_t = S*sigmoid(FC1(tanh(FC2(h_t))) tf.cast()完全連接的層是可訓練的重量矩陣。得出一個對齊的位置浮點值,並使用高斯分佈來調整所有源隱藏狀態的注意力權重,而不是切成實際的窗口,我們還提出了一種實驗對準類型, c)完全預測的對齊方式:將其設置為II中的p_t ,但將其應用於所有源隱藏狀態( h_s ),而不是目標隱藏狀態( h_t )。然後,選擇頂部@window_width位置以構建上下文向量,而將其餘的位置為零。當前,此選項僅適用於多對一場景。
Zichao Yang等人在分層注意網絡中首次引入文檔分類。這個想法是反映文檔中存在的層次結構。原始論文提出了一種自下而上的方法,通過在單詞和句子級別上依次應用注意機制,但自上而下的方法(例如,詞語和字符級別)也適用。因此,據說這種機制在構建文檔表示時會差別地差與更重要的內容。
每個功能都試圖計算給定目標隱藏狀態( h_t )和源隱藏狀態( h_s )的對齊分數。
| 姓名 | 公式 | 由 |
|---|---|---|
| 點產品 | Luong等。 (2015) | |
| 縮放點產品 | Vaswani等。 (2017) | |
| 一般的 | Luong等。 (2015) | |
| concat | Bahdanau等。 (2015) | |
| 地點 | Luong等。 (2015) |
其中H是編碼器RNN給出的隱藏狀態的數量,其中W_a和v_a是可訓練的重量矩陣。
tf.keras.layers.Layer()的子類。__init__()方法調用其父級的初始化方法,並定義針對每一層特定的其他屬性。get_config()方法調用其父級的配置方法,並定義與該圖層引入的自定義屬性。build() ,則它包含可訓練的參數。以Attention()層為例,輸入以提供更多護理的損耗信號的反向傳播,因此表明該層的權重發生了變化。call()方法是在輸入張量上執行的實際操作。compute_output_shape()方法用於間距。 這些層可以在幾秒鐘內插入您的項目(無論是語言模型還是其他類型的RNN),就像其他帶有KERAS Integration的TensorFlow層一樣。例如,請參見以下通用示例:例如:
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from layers import Attention
X = Input(shape=(sequence_length,), batch_size=batch_size) # define input layer for summary
## Token Embedding (Pretrained or Not) ##
embedding = Embedding(input_dim=vocabulary_size, output_dim=embedded_dimensions)(X)
## Encoding Recurrent Layers ##
encoder = LSTM(units=recurrent_units, return_sequences=True)(embedding) # keep timesteps
## Decoding with Attention ##
decoder, attention_weights = Attention(context='many-to-one', alignment_type=attention_type, model_api='functional')(encoder)
## Prediction Layer ##
Y = Dense(units=vocabulary_size, activation='softmax')(decoder)
其中alignment_type是'global' , 'local-m' , 'local-p'和'local-p*'之一。為了自我關注,請稱呼SelfAttention(size=attention_size)層。
在下面查看子主題以獲取更多示例,分析和比較。為了進行公平的比較,所有比較模型都利用相似的參數。例如,在某些示例中,首選的批量大小為100 ,而多個時期為20個。
您可以在IMBD評論examples/sentiment_classification.py中找到情感分類(多對一,二進制)示例。此示例比較了三個不同的tf.keras.Model() (函數API )模型(所有單詞級),並旨在測量在常規MLP(多層PercePtron)模型上實現的自我注意力層的有效性。請參閱下表的指標:
| 模型ID | 最大驗證二進制精度 |
|---|---|
| 簡單的多層感知模型 | 0.8730 |
| 帶有自我注意的簡單多層感知器模型(非素化) | 0.8907 |
| 帶有自我注意的簡單多層感知器模型(受到懲罰) | 0.8870 |
您可以在examples/text_generation.py上找到文本生成(多對一)示例。此示例比較了三個不同的tf.keras.Model() (功能API )模型(所有字符級),並旨在衡量在常規LSTM(長期短期存儲器)模型上實現的注意力和自我發揮層的有效性。請參閱下表的指標:
| 模型ID | 最大驗證分類精度 |
|---|---|
| LSTM模型 | 0.5953 |
| LSTM模型帶有自我注意力(非素化) | 0.6049 |
| LSTM型號W/ loc-p*注意 | 0.6234 |
您可以在路透社數據集中的examples/document_classification.py上找到一個文檔(新聞)分類(多對一,多類)示例。此示例比較了四個不同的tf.keras.Model() (功能性API )模型(所有單詞級),並旨在衡量在常規LSTM(長期短期存儲器)模型上實現的注意力和自我發揮層的有效性。請參閱下表的指標:
| 模型ID | 最大驗證分類精度 |
|---|---|
| LSTM模型 | 0.7210 |
| LSTM模型帶有自我注意力(非素化) | 0.7790 |
| LSTM模型,全球關注 | 0.7496 |
| LSTM型號W/ loc-p*注意 | 0.7446 |
您可以在示例中的英語到西班牙數據集上找到一個機器翻譯(多到多) examples/machine_translation.py 。這個示例幾乎遵循Tensorflow的機器翻譯示例,並進行了一些改編。它比較了四個不同的tf.keras.Model() (函數API )模型(所有單詞級),並旨在衡量實現的注意力層的有效性。請參閱下表的指標:
| 模型ID | 最大驗證分類精度 |
|---|---|
| 編碼器模型 | 0.8848 |
| 編碼器模型,帶全球關注 | 0.8860 |
| 編碼器模型w/ local-m注意 | 0.9524 |
| 編碼器decoder模型,local-p注意 | 0.8873 |
無論是您遇到的錯誤,性能問題還是您想到的任何類型的輸入,這都是分享它們的最佳時機!檢查CONTRIBUTING.md以獲取有關此主題的更多信息和指南。


