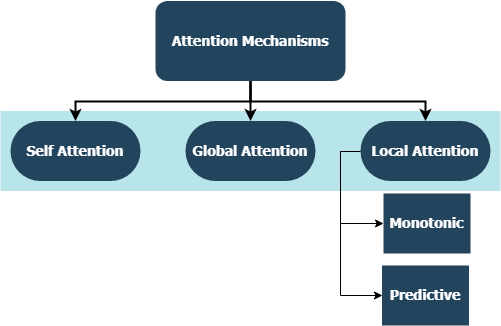
attention mechanisms
1.0.0
يتضمن هذا المستودع تطبيقات طبقة مخصصة لعائلة كاملة من آليات الاهتمام ، متوافقة مع TensorFlow و Keras Integration. حولت آليات الانتباه المشهد للترجمة الآلية ، واستخدامها في مجالات أخرى من معالجة اللغة الطبيعية وتفاهمها تزداد يومًا بعد يوم. بمعنى أوسع ، يهدفون إلى القضاء على الضغط غير الموات وفقدان المعلومات في RNNs. وتنشأ هذه بسبب ترميز الطول الثابت للحالات المخفية المستمدة من تسلسل الإدخال بواسطة طبقات متكررة في نماذج التسلسل إلى التسلسل. يمكن استخدام الطبقات في هذا المستودع في كل من المهام المتسلسلة للعديد من العدد والعديد من إلى واحد . تتضمن التطبيقات تصنيف المشاعر وتوليد النصوص والترجمة الآلية والإجابة على الأسئلة . تجدر الإشارة أيضًا إلى أن هذا المشروع سيتم نشره قريبًا كحزمة بيثون. تحقق من القسم الفرعي المساهمة حول كيفية المساهمة في هذا المشروع.
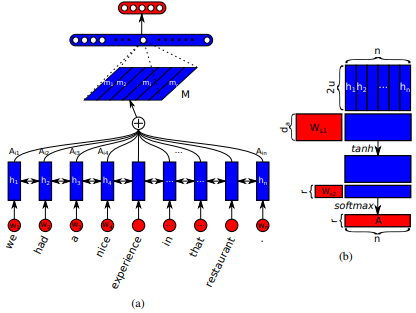
تم تقديمه لأول مرة في شبكات الذاكرة على المدى القصير على المدى الطويل لقراءة الجهاز بواسطة Jianpeng Cheng et al. تتمثل الفكرة في ربط المواضع المختلفة لنفس مساحة الحالة المخفية المستمدة من تسلسل الإدخال ، بناءً على الوسيطة التي تشكل مكونات متعددة معًا الدلالات الشاملة للتسلسل. يجمع هذا النهج بين هذه المعلومات الموقوتة بشكل مختلف من خلال اهتمام القفزات المتعددة . يتبع هذا التنفيذ بالذات جملة منظمة ذاتية التضمين من قبل Zhouhan Lin et al. عندما يقترح المؤلفون مقياسًا إضافيًا لخسارة للتنظيم لمنع مشاكل التكرار في مصفوفة التضمين إذا كانت آلية الانتباه توفر دائمًا أوزان شرحية مماثلة.
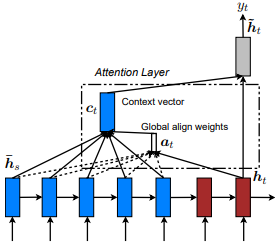
تم تقديمه لأول مرة في الترجمة الآلية العصبية عن طريق التعلم المشترك للمحاذاة والترجمة بواسطة Dzmitry Bahdanau et al. والفكرة هي استخلاص ناقل سياق استنادًا إلى جميع الحالات المخفية لـ Encoder RNN. وبالتالي ، يقال أن هذا النوع من الاهتمام يحضر إلى مساحة حالة الإدخال بأكملها.
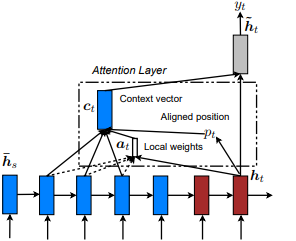
تم تقديمه لأول مرة في العرض والحضور والاحتفال: توليد تسميات تسميات الصورة العصبية مع الاهتمام البصري من قبل Kelvin Xu et al. وتكييف مع NLP في الأساليب الفعالة للترجمة الآلية العصبية القائمة على الانتباه من قبل Minh-thang Luong et al. تتمثل الفكرة في القضاء على التكلفة اليقظة للاهتمام العالمي من خلال التركيز بدلاً من ذلك على مجموعة فرعية صغيرة من الرموز في الحالات المخفية التي تم تعيينها من تسلسل الإدخال. يُقترح هذه النافذة على أنها [p_t-D, p_t+D] حيث D=width ، ونتجاهل المواقف التي تتقاطع مع حدود التسلسل. يتم تحديد الموضع المحاذاة ، p_t ، إما من خلال أ) محاذاة رتابة: تعيين p_t=t tf.cast() أو ب) المحاذاة التنبؤية : تعيين p_t = S*sigmoid(FC1(tanh(FC2(h_t))) عندما تكون الطبقات المتصلة بشكل كامل قابلة للدرار. الموضع المحاذاة قيمة تعويم ويستخدم التوزيع الغوسي لضبط p_t الانتباه لجميع الحالات المخفية المصدر h_s من h_t النافذة الفعلية. بعد ذلك ، اختر مواضع @window_width TOP لإنشاء متجه السياق وتصدر الباقي. حاليًا ، هذا الخيار لا يمكن إلا للسيناريوهات للعديد إلى واحد.
تم تقديمه لأول مرة في شبكات الاهتمام الهرمية لتصنيف المستندات بواسطة Zichao Yang et al. والفكرة هي أن تعكس الهيكل الهرمي الموجود داخل المستندات. تقترح الورقة الأصلية اتباع نهج من أسفل إلى أعلى من خلال تطبيق آليات الانتباه بالتتابع على مستويات الكلمات والجملة ، ولكن النهج من أعلى إلى أسفل (على سبيل المثال ، مستويات الكلمة والشخصيات) ينطبق أيضًا. وبالتالي ، يقال إن هذا النوع من الآليات يحضر بشكل مختلف إلى محتوى أكثر وأقل أهمية عند بناء تمثيل المستند.
تحاول كل وظيفة حساب درجة المحاذاة بالنظر إلى حالة خفية مستهدفة ( h_t ) والحالات المخفية المصدر ( h_s ).
| اسم | صيغة ل | حددها |
|---|---|---|
| منتج DOT | Luong et al. (2015) | |
| منتج DOT المحجوز | فاسواني وآخرون. (2017) | |
| عام | Luong et al. (2015) | |
| CONCAT | بهداناو وآخرون. (2015) | |
| موقع | Luong et al. (2015) |
عندما يكون H هو عدد الحالات المخفية التي قدمها المشفر RNN ، وحيثما يكون W_a و v_a مصفوفات وزن قابلة للتدريب.
tf.keras.layers.Layer() .__init__() لكل فئة مخصصة طريقة التهيئة الخاصة به وتحدد سمات إضافية محددة لكل طبقة.get_config() طريقة التكوين الخاصة بها وتحدد السمات المخصصة التي تم تقديمها مع الطبقة.build() ، فإنها تحتوي على معلمات قابلة للتدريب. خذ الطبقة Attention() على سبيل المثال ، على سبيل المثال ، تشير الإشارات الخلفية لإشارات الخسارة التي تدخل لإعطاء مزيد من الرعاية له ، وبالتالي يشير إلى تغيير في أوزان الطبقة.call() هي العملية الفعلية التي يتم تنفيذها على موترات الإدخال.compute_output_shape() للتباعد. يمكن توصيل هذه الطبقات بمشاريعك (سواء كانت نماذج اللغة أو أنواع أخرى من RNNs) في غضون ثوانٍ ، تمامًا مثل أي طبقة أخرى من TensorFlow مع تكامل Keras. انظر المثال أدناه للأغراض العامة على سبيل المثال:
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from layers import Attention
X = Input(shape=(sequence_length,), batch_size=batch_size) # define input layer for summary
## Token Embedding (Pretrained or Not) ##
embedding = Embedding(input_dim=vocabulary_size, output_dim=embedded_dimensions)(X)
## Encoding Recurrent Layers ##
encoder = LSTM(units=recurrent_units, return_sequences=True)(embedding) # keep timesteps
## Decoding with Attention ##
decoder, attention_weights = Attention(context='many-to-one', alignment_type=attention_type, model_api='functional')(encoder)
## Prediction Layer ##
Y = Dense(units=vocabulary_size, activation='softmax')(decoder)
حيث تعد alignment_type واحدة من 'global' و 'local-m' و 'local-p' و 'local-p*' . من أجل الاهتمام الذاتي ، اتصل بطبقة SelfAttention(size=attention_size) بدلاً من ذلك.
تحقق أدناه من المواطن الفرعية لمزيد من الأمثلة والتحليلات والمقارنات. للمقارنة العادلة ، تستخدم جميع النماذج المقارنة معلمات مماثلة. على سبيل المثال ، تم تفضيل حجم الدُفعة 100 وعدد من الحقبة من 20 على بعض الأمثلة.
يمكنك العثور على مثال على تصنيف المشاعر (العديد إلى واحد ، ثنائي) على مجموعة بيانات مراجعة IMBD داخل examples/sentiment_classification.py . يقارن هذا المثال ثلاثة نماذج متميزة tf.keras.Model() ( API الوظيفية ) (جميع مستوى الكلمات) ويهدف إلى قياس فعالية طبقة الاهتمام الذاتي المنفذة على نموذج MLP التقليدي (متعدد الطبقة). الرجوع إلى الجدول أدناه للمقاييس:
| معرف النموذج | أقصى دقة ثنائية التحقق من الصحة |
|---|---|
| نموذج بسيط متعدد الطبقات | 0.8730 |
| نموذج بسيط متعدد الطبقات Perceptron مع الالتحاق الذاتي (غير مستقر) | 0.8907 |
| نموذج بسيط متعدد الطبقات Perceptron مع الاهتمام الذاتي (معاقبة) | 0.8870 |
يمكنك العثور على مثال لتوليد النص (العديد إلى واحد) على مجموعة بيانات شكسبير داخل examples/text_generation.py . يقارن هذا المثال ثلاثة نماذج متميزة tf.keras.Model() ( API الوظيفية ) (جميعها على مستوى الأحرف) وتهدف إلى قياس فعالية طبقات الانتباه والاعتداء الذاتي المنفذة على نماذج LSTM التقليدية (الذاكرة طويلة المدى الطويلة). الرجوع إلى الجدول أدناه للمقاييس:
| معرف النموذج | أقصى دقة فئوية التحقق من الصحة |
|---|---|
| نموذج LSTM | 0.5953 |
| نموذج LSTM مع الاهتمام الذاتي ( | 0.6049 |
| طراز LSTM w/ local-p* الاهتمام | 0.6234 |
يمكنك العثور على تصنيف مستند (أخبار) مثال (العديد إلى واحد ، متعدد الفوضى) على مجموعة بيانات رويترز داخل examples/document_classification.py . يقارن هذا المثال أربعة نماذج متميزة tf.keras.Model() ( API الوظيفية ) (جميع مستوى الكلمات) ويهدف إلى قياس فعالية طبقات الانتباه والاعتداء الذاتي المنفذة على نماذج LSTM التقليدية (الذاكرة طويلة المدى الطويلة). الرجوع إلى الجدول أدناه للمقاييس:
| معرف النموذج | أقصى دقة فئوية التحقق من الصحة |
|---|---|
| نموذج LSTM | 0.7210 |
| نموذج LSTM مع الاهتمام الذاتي ( | 0.7790 |
| نموذج LSTM مع الاهتمام العالمي | 0.7496 |
| طراز LSTM w/ local-p* الاهتمام | 0.7446 |
يمكنك العثور على مثال للترجمة الآلية (العديد من العدد) على مجموعة البيانات الإنجليزية إلى الإسبانية داخل examples/machine_translation.py . يتبع هذا المثال إلى حد كبير مثال الترجمة الآلية لـ TensorFlow مع بعض التكيف. يقارن أربعة نماذج متميزة tf.keras.Model() ( API الوظيفية ) (جميع مستوى الكلمات) وتهدف إلى قياس فعالية طبقة الانتباه المنفذة. الرجوع إلى الجدول أدناه للمقاييس:
| معرف النموذج | أقصى دقة فئوية التحقق من الصحة |
|---|---|
| نموذج التشفير-ترميز | 0.8848 |
| نموذج التشفير والرفض مع الاهتمام العالمي | 0.8860 |
| نموذج التشفير والرفض مع الاهتمام المحلي M | 0.9524 |
| نموذج التشفير والرفض مع الانتباه المحلي p | 0.8873 |
سواء أكانت أخطاء واجهتها أو مخاوف الأداء أو أي نوع من المدخلات التي تفكر فيها ، فهذا هو الوقت المثالي لمشاركتها! تحقق من CONTRIBUTING.md لمزيد من المعلومات والإرشادات حول هذا الموضوع.


