attention mechanisms
1.0.0
该存储库包括针对整个注意机制的自定义层实现,与Tensorflow和Keras集成兼容。注意机制改变了机器翻译的景观,它们在自然语言处理和理解的其他领域的利用日益日益增加。从广义上讲,它们旨在消除RNN中不利的压缩和信息丢失。这些起源是由于通过序列到序列模型中复发层从输入序列得出的隐藏状态的固定长度编码。该存储库中的层可用于多对多和多一对序列任务。应用程序包括情感分类,文本生成,机器翻译和问题回答。还值得一提的是,该项目将很快被部署为Python包。检查有关如何为该项目贡献的贡献小节。
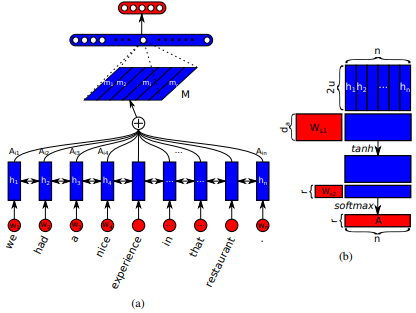
首先在长期短期内存网络中引入了Jianpeng Cheng等人的机器阅读。这个想法是基于以下论点,即从输入序列衍生出的相同隐藏状态空间的不同位置,即多个组件一起构成了序列的整体语义。这种方法通过多个啤酒花的注意将这些不同定位的信息汇总在一起。该特定的实现遵循Zhouhan Lin等人嵌入的结构化自我实践句子。如果注意机制始终提供相似的注释权重,则作者提出了额外的正规化损失度量,以防止嵌入矩阵的冗余问题。
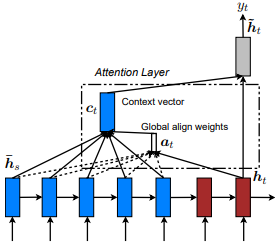
首先是通过共同学习与Dzmitry Bahdanau等人对齐和翻译的首次引入的。这个想法是根据编码器RNN的所有隐藏状态得出上下文向量。因此,据说这种类型的注意力集中在整个输入状态空间上。
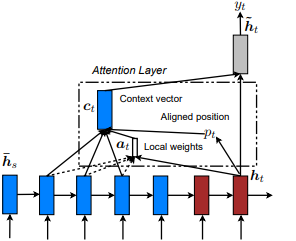
首次在节目中引入,参加和讲述:Kelvin Xu等人的视觉关注的神经图像字幕产生。并适用于NLP,以有效的方法对基于注意力的神经机器翻译,由Minh-thang Luong等人。这个想法是通过关注从输入序列得出的隐藏状态集中的一小部分令状子集来消除全球关注的细心成本。该窗口被提出为[p_t-D, p_t+D]其中D=width ,我们无视跨序列边界的位置。对齐的位置p_t是通过A)单调对准决定的: set p_t=t或b)预测性一致性:set p_t = S*sigmoid(FC1(tanh(FC2(h_t))) tf.cast()完全连接的层是可训练的重量矩阵。得出一个对齐的位置浮点值,并使用高斯分布来调整所有源隐藏状态的注意力权重,而不是切成实际的窗口,我们还提出了一种实验对准类型, c)完全预测的对齐方式:将其设置为II中的p_t ,但将其应用于所有源隐藏状态( h_s ),而不是目标隐藏状态( h_t )。然后,选择顶部@window_width位置以构建上下文向量,而将其余的位置为零。当前,此选项仅适用于多对一场景。
Zichao Yang等人在分层注意网络中首次引入文档分类。这个想法是反映文档中存在的层次结构。原始论文提出了一种自下而上的方法,通过在单词和句子级别上依次应用注意机制,但自上而下的方法(例如,词语和字符级别)也适用。因此,据说这种机制在构建文档表示时会差别地差与更重要的内容。
每个功能都试图计算给定目标隐藏状态( h_t )和源隐藏状态( h_s )的对齐分数。
| 姓名 | 公式 | 由 |
|---|---|---|
| 点产品 | Luong等。 (2015) | |
| 缩放点产品 | Vaswani等。 (2017) | |
| 一般的 | Luong等。 (2015) | |
| concat | Bahdanau等。 (2015) | |
| 地点 | Luong等。 (2015) |
其中H是编码器RNN给出的隐藏状态的数量,其中W_a和v_a是可训练的重量矩阵。
tf.keras.layers.Layer()的子类。__init__()方法调用其父级的初始化方法,并定义针对每一层特定的其他属性。get_config()方法调用其父级的配置方法,并定义与该图层引入的自定义属性。build() ,则它包含可训练的参数。以Attention()层为例,输入以提供更多护理的损耗信号的反向传播,因此表明该层的权重发生了变化。call()方法是在输入张量上执行的实际操作。compute_output_shape()方法用于间距。 这些层可以在几秒钟内插入您的项目(无论是语言模型还是其他类型的RNN),就像其他带有KERAS Integration的TensorFlow层一样。例如,请参见以下通用示例:例如:
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from layers import Attention
X = Input(shape=(sequence_length,), batch_size=batch_size) # define input layer for summary
## Token Embedding (Pretrained or Not) ##
embedding = Embedding(input_dim=vocabulary_size, output_dim=embedded_dimensions)(X)
## Encoding Recurrent Layers ##
encoder = LSTM(units=recurrent_units, return_sequences=True)(embedding) # keep timesteps
## Decoding with Attention ##
decoder, attention_weights = Attention(context='many-to-one', alignment_type=attention_type, model_api='functional')(encoder)
## Prediction Layer ##
Y = Dense(units=vocabulary_size, activation='softmax')(decoder)
其中alignment_type是'global' , 'local-m' , 'local-p'和'local-p*'之一。为了自我关注,请称呼SelfAttention(size=attention_size)层。
在下面查看子主题以获取更多示例,分析和比较。为了进行公平的比较,所有比较模型都利用相似的参数。例如,在某些示例中,首选的批量大小为100 ,而多个时期为20个。
您可以在IMBD评论examples/sentiment_classification.py中找到情感分类(多对一,二进制)示例。此示例比较了三个不同的tf.keras.Model() (函数API )模型(所有单词级),并旨在测量在常规MLP(多层PercePtron)模型上实现的自我注意力层的有效性。请参阅下表的指标:
| 模型ID | 最大验证二进制精度 |
|---|---|
| 简单的多层感知模型 | 0.8730 |
| 带有自我注意的简单多层感知器模型(非素化) | 0.8907 |
| 带有自我注意的简单多层感知器模型(受到惩罚) | 0.8870 |
您可以在examples/text_generation.py上找到文本生成(多对一)示例。此示例比较了三个不同的tf.keras.Model() (功能API )模型(所有字符级),并旨在衡量在常规LSTM(长期短期存储器)模型上实现的注意力和自我发挥层的有效性。请参阅下表的指标:
| 模型ID | 最大验证分类精度 |
|---|---|
| LSTM模型 | 0.5953 |
| LSTM模型带有自我注意力(非素化) | 0.6049 |
| LSTM型号W/ loc-p*注意 | 0.6234 |
您可以在路透社数据集中的examples/document_classification.py上找到一个文档(新闻)分类(多对一,多类)示例。此示例比较了四个不同的tf.keras.Model() (功能性API )模型(所有单词级),并旨在衡量在常规LSTM(长期短期存储器)模型上实现的注意力和自我发挥层的有效性。请参阅下表的指标:
| 模型ID | 最大验证分类精度 |
|---|---|
| LSTM模型 | 0.7210 |
| LSTM模型带有自我注意力(非素化) | 0.7790 |
| LSTM模型,全球关注 | 0.7496 |
| LSTM型号W/ loc-p*注意 | 0.7446 |
您可以在示例中的英语到西班牙数据集上找到一个机器翻译(多到多) examples/machine_translation.py 。这个示例几乎遵循Tensorflow的机器翻译示例,并进行了一些改编。它比较了四个不同的tf.keras.Model() (函数API )模型(所有单词级),并旨在衡量实现的注意力层的有效性。请参阅下表的指标:
| 模型ID | 最大验证分类精度 |
|---|---|
| 编码器模型 | 0.8848 |
| 编码器模型,带全球关注 | 0.8860 |
| 编码器模型w/ local-m注意 | 0.9524 |
| 编码器decoder模型,local-p注意 | 0.8873 |
无论是您遇到的错误,性能问题还是您想到的任何类型的输入,这都是分享它们的最佳时机!检查CONTRIBUTING.md以获取有关此主题的更多信息和指南。


