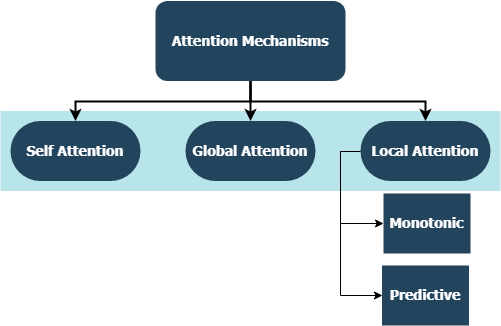
attention mechanisms
1.0.0
Ce référentiel comprend des implémentations de couche personnalisées pour toute une famille de mécanismes d'attention, compatibles avec l'intégration TensorFlow et Keras. Les mécanismes d'attention ont transformé le paysage de la traduction automatique, et leur utilisation dans d'autres domaines de traitement et de compréhension du langage naturel augmente de jour en jour. Dans un sens plus large, ils visent à éliminer la compression désavantageuse et la perte d'informations dans les RNN. Ceux-ci proviennent du codage de longueur fixe des états cachés dérivés de séquences d'entrée par des couches récurrentes dans des modèles de séquence à séquence. Les couches de ce référentiel peuvent être utilisées pour les tâches de séquence plusieurs à plusieurs et plusieurs . Les applications incluent la classification des sentiments , la génération de texte , la traduction machine et la réponse aux questions . Il convient également de mentionner que ce projet sera bientôt déployé comme un package Python. Vérifiez le paragraphe contribuant sur la façon de contribuer à ce projet.
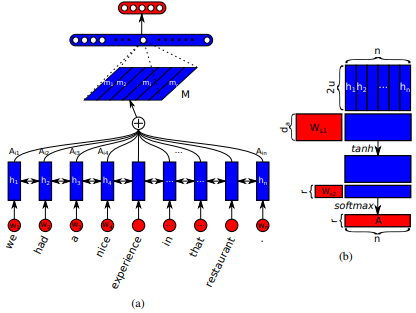
Introduit pour la première fois dans les réseaux de mémoire à court terme pour la lecture des machines par Jianpeng Cheng et al. L'idée est de relier différentes positions du même espace d'état caché dérivé de la séquence d'entrée, basée sur l'argument selon lequel plusieurs composants forment ensemble la sémantique globale d'une séquence. Cette approche rassemble ces informations positionnées différemment grâce à l'attention multiple du houblon . Cette mise en œuvre particulière suit une phrase auto-attentive structurée intégrée par Zhouhan Lin et al. Lorsque les auteurs proposent une métrique de perte supplémentaire pour la régularisation afin d'éviter les problèmes de redondance de la matrice d'intégration si le mécanisme d'attention fournit toujours des poids d'annotation similaires.
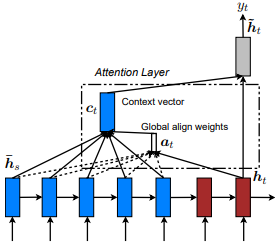
Introduit d'abord dans la traduction de la machine neurale en apprenant conjointement à aligner et à traduire par Dzmitry Bahdanau et al. L'idée est de dériver un vecteur de contexte basé sur tous les états cachés du RNN de l'encodeur. Par conséquent, on dit que ce type d'attention porte sur l'ensemble de l'espace d'état d'entrée.
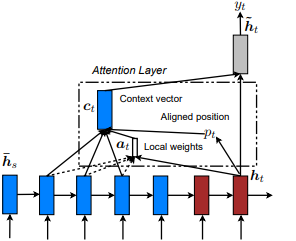
Introduit pour la première fois dans Show, Assister and Tell: Neural Image Legend Generation avec une attention visuelle par Kelvin Xu et al. et adapté à la PNL dans des approches efficaces de la traduction de la machine neuronale basée sur l'attention par Minh-Thang Luong et al. L'idée est d'éliminer le coût attentif de l'attention mondiale en se concentrant plutôt sur un petit sous-ensemble de jetons dans des états cachés définis dérivés de la séquence d'entrée. Cette fenêtre est proposée comme [p_t-D, p_t+D] où D=width , et nous ne tenons pas compte des positions qui traversent les limites de séquence. La position alignée, p_t , est décidée soit via a) l'alignement monotonique: définir p_t=t , soit b) Alignement prédictif : SET p_t = S*sigmoid(FC1(tanh(FC2(h_t))) tf.cast() les couches entièrement connectées sont des matrices de poids formé Position alignée Valeur du flotteur et utilise la distribution gaussienne pour ajuster p_t poids d' attention de tous les états cachés de h_s au lieu de trancher la fenêtre h_t . Ensuite, choisissez les positions top @window_width pour construire le vecteur de contexte et zero out le reste. Actuellement, cette option n'est avaiable que pour les scénarios de plusieurs à un.
Introduit pour la première fois dans les réseaux d'attention hiérarchiques pour la classification des documents par Zichao Yang et al. L'idée est de refléter la structure hiérarchique qui existe dans les documents. L'article d'origine propose une approche ascendante en appliquant des mécanismes d'attention séquentiellement au niveau des mots et des phrases, mais une approche descendante (ex. Au niveau des mots et des caractères) est également applicable. Par conséquent, ce type de mécanismes s'occuperait de contenu de plus en plus important lors de la construction de la représentation des documents.
Chaque fonction essaie de calculer un score d'alignement étant donné un état caché cible ( h_t ) et les états cachés de source ( h_s ).
| Nom | Formule pour | Défini par |
|---|---|---|
| Produit DOT | Luong et al. (2015) | |
| Produit à point à l'échelle | Vaswani et al. (2017) | |
| Général | Luong et al. (2015) | |
| Concat | Bahdanau et al. (2015) | |
| Emplacement | Luong et al. (2015) |
où H est le nombre d'états cachés donnés par le RNN de l'encodeur, et où W_a et v_a sont des matrices de poids entraînables.
tf.keras.layers.Layer() .__init__() de chaque classe personnalisée appelle la méthode d'initialisation de son parent et définit des attributs supplémentaires spécifiques à chaque couche.get_config() appelle la méthode de configuration de son parent et définit les attributs personnalisés introduits avec la couche.build() , elle contient des paramètres formables. Prenons l'exemple de la couche Attention() par exemple, la rétropropagation des signaux de perte qui apprend pour donner plus de soin et indique donc un changement de poids de la couche.call() est l'opération réelle qui est effectuée sur les tenseurs d'entrée.compute_output_shape() sont évitées pour l'espacement. Ces couches peuvent être branchées sur vos projets (que ce soit des modèles de langue ou d'autres types de RNN) en quelques secondes, comme toute autre couche TensorFlow avec intégration Keras. Voir l'exemple à usage général ci-dessous par exemple:
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from layers import Attention
X = Input(shape=(sequence_length,), batch_size=batch_size) # define input layer for summary
## Token Embedding (Pretrained or Not) ##
embedding = Embedding(input_dim=vocabulary_size, output_dim=embedded_dimensions)(X)
## Encoding Recurrent Layers ##
encoder = LSTM(units=recurrent_units, return_sequences=True)(embedding) # keep timesteps
## Decoding with Attention ##
decoder, attention_weights = Attention(context='many-to-one', alignment_type=attention_type, model_api='functional')(encoder)
## Prediction Layer ##
Y = Dense(units=vocabulary_size, activation='softmax')(decoder)
où alignment_type est l'un des 'global' , 'local-m' , 'local-p' et 'local-p*' . Pour l'attention de soi, appelez plutôt la calque SelfAttention(size=attention_size) .
Vérifiez ci-dessous les sous-thèmes pour plus d'exemples, d'analyses et de comparaisons. Pour une comparaison équitable, tous les modèles comparés utilisent des paramètres similaires. Par exemple, une taille de lot de 100 et un certain nombre d'époches de 20 ont été préférées sur certains exemples.
Vous pouvez trouver un exemple de classification des sentiments (plusieurs à un, binaire) sur IMBD Reviews DataSet à l'intérieur examples/sentiment_classification.py . Cet exemple compare trois modèles tf.keras.Model() ( API fonctionnels ) (tout le niveau des mots) et vise à mesurer l'efficacité de la couche d'auto-agence d'auto-atténuation mise en œuvre par rapport au modèle MLP conventionnel (multi-couche Perceptron). Reportez-vous au tableau ci-dessous pour les mesures:
| ID de modèle | Précision binaire de validation maximale |
|---|---|
| Modèle de perceptron multicouche simple | 0,8730 |
| Modèle de perceptron multicouche simple avec Auto-Attention (non pénalisé) | 0,8907 |
| Modèle de perceptron multicouche simple avec l'auto-atténuer (pénalisé) | 0,8870 |
Vous pouvez trouver un exemple de génération de texte (plusieurs à un) sur le jeu de données Shakespeare à l'intérieur examples/text_generation.py . Cet exemple compare trois modèles tf.keras.Model() ( API fonctionnels ) (tous au niveau des caractéristiques) et vise à mesurer l'efficacité des couches d'attention et d'auto-admission mises en œuvre par rapport aux modèles LSTM conventionnels (mémoire à court terme à court terme). Reportez-vous au tableau ci-dessous pour les mesures:
| ID de modèle | Précision catégorique de validation maximale |
|---|---|
| Modèle LSTM | 0,5953 |
| Modèle LSTM avec Auto-Assetention (non pénalisé) | 0,6049 |
| Modèle LSTM avec attention locale-p * | 0,6234 |
Vous pouvez trouver un exemple de classification de document (nouvelles) (plusieurs à un, multi-classes) sur l'ensemble de données Reuters à l'intérieur examples/document_classification.py . Cet exemple compare quatre modèles tf.keras.Model() ( API fonctionnels ) (tous au niveau des mots) et vise à mesurer l'efficacité des couches d'attention et d'auto-addition mise en œuvre par rapport aux modèles LSTM conventionnels (mémoire à court terme à court terme). Reportez-vous au tableau ci-dessous pour les mesures:
| ID de modèle | Précision catégorique de validation maximale |
|---|---|
| Modèle LSTM | 0,7210 |
| Modèle LSTM avec Auto-Assetention (non pénalisé) | 0,7790 |
| Modèle LSTM avec attention globale | 0,7496 |
| Modèle LSTM avec attention locale-p * | 0,7446 |
Vous pouvez trouver un exemple de traduction machine (plusieurs-à-plusieurs) sur l'ensemble de données anglaise à spaniste à l'intérieur examples/machine_translation.py . Cet exemple suit à peu près l'exemple de traduction machine de TensorFlow avec quelques adaptations. Il compare quatre modèles distincts tf.keras.Model() ( API fonctionnels ) (tout niveau de mot) et vise à mesurer l'efficacité de la couche d'attention mise en œuvre. Reportez-vous au tableau ci-dessous pour les mesures:
| ID de modèle | Précision catégorique de validation maximale |
|---|---|
| Modèle d'encodeur-décodeur | 0,8848 |
| Modèle d'encodeur-décodeur avec attention globale | 0,8860 |
| Modèle d'encodeur-décodeur avec attention locale | 0,9524 |
| Modèle d'encodeur-décodeur avec attention locale | 0,8873 |
Que ce soit des bugs que vous avez rencontrés, des problèmes de performance ou tout type de contribution que vous avez en tête, c'est le moment idéal pour les partager! Vérifiez CONTRIBUTING.md pour plus d'informations et de directives sur ce sujet.


