attention mechanisms
1.0.0
このリポジトリには、TensorflowとKerasの統合と互換性のある、注意メカニズムの家族全員向けのカスタムレイヤー実装が含まれています。注意メカニズムは機械翻訳の景観を変え、自然言語の処理と理解の他の領域でのそれらの利用は日々増加しています。より広い意味で、彼らはRNNの不利な圧縮と情報の喪失を排除することを目指しています。これらは、シーケンスからシーケンスモデルの再発層によって入力シーケンスから導出された隠された状態の固定長エンコードが原因で発生します。このリポジトリのレイヤーは、多目的および多くのシーケンスタスクの両方に使用できます。アプリケーションには、感情分類、テキスト生成、機械翻訳、および質問応答が含まれます。また、このプロジェクトがまもなくPythonパッケージとして展開されることに言及する価値があります。このプロジェクトに貢献する方法について、寄稿サブセクションを確認してください。
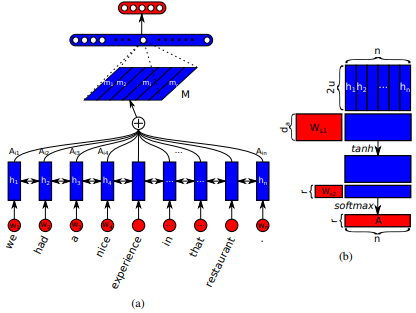
Jianpeng Cheng et al 。アイデアは、複数のコンポーネントが一緒になってシーケンスの全体的なセマンティクスを形成するという議論に基づいて、入力シーケンスから派生した同じ隠された状態空間の異なる位置を関連付けることです。このアプローチは、複数のホップの注意を通して、これらの異なる位置付けられた情報をまとめます。この特定の実装は、Zhouhan Lin et alによる構造化された自己触媒文の埋め込みに従います。著者が、注意メカニズムが常に同様の注釈の重みを提供する場合、埋め込みマトリックスの冗長性の問題を防ぐために、正規化のための追加の損失メトリックを提案しています。
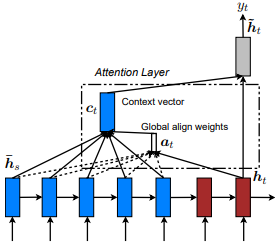
Dzmitry Bahdanau et al 。アイデアは、エンコーダーRNNのすべての非表示された状態に基づいてコンテキストベクトルを導出することです。したがって、このタイプの注意は、入力状態空間全体に注意していると言われています。
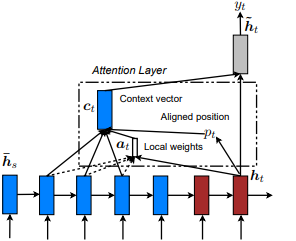
ショー、出席、テルで最初に紹介されました: Kelvin Xu et al。 Minh- Thang Luong et al。アイデアは、入力シーケンスから派生した非表示状態のトークンの小さなサブセットに焦点を当てることにより、グローバルな注意の注意コストを排除することです。このウィンドウは[p_t-D, p_t+D]として提案されています。ここで、 D=widthあり、シーケンス境界を横断する位置を無視します。整列した位置p_tは、 a)単調アライメント: Set p_t=t 、またはb)予測アライメント: p_t = S*sigmoid(FC1(tanh(FC2(h_t))) tf.cast()介して決定されます。アラインド位置フロート値とガウス分布を使用してp_t実際のウィンドウをスライスする代わりに、すべてのソースの隠された状態の注意h_s h_t調整します。次に、TOP @window_width位置を選択して、コンテキストベクトルを構築し、残りをゼロにします。現在、このオプションは、多くのシナリオに対してのみAvaveableです。
Zichao Yang et al 。アイデアは、ドキュメント内に存在する階層構造を反映することです。元の論文では、ワードレベルと文レベルで注意メカニズムを順番に適用することによりボトムアップアプローチを提案しますが、トップダウンアプローチ(例とキャラクターレベルとキャラクターレベル)も適用されます。したがって、このタイプのメカニズムは、ドキュメントの表現を構築する際に、より重要性の低いコンテンツと差別的に出席すると言われています。
各関数は、ターゲットの隠された状態( h_t )とソースの非表示状態( h_s )を考慮して、アライメントスコアを計算しようとしています。
| 名前 | フォーフォーミュラ | 定義されています |
|---|---|---|
| ドット製品 | Luong et al。 (2015) | |
| スケーリングされたドット製品 | Vaswani et al。 (2017) | |
| 一般的な | Luong et al。 (2015) | |
| concat | Bahdanau et al。 (2015) | |
| 位置 | Luong et al。 (2015) |
ここで、 HエンコーダーRNNによって与えられる隠された状態の数であり、 W_aとv_aトレーニング可能な重量行列です。
tf.keras.layers.Layer()のサブクラスです。__init__()メソッドは、親の初期化方法を呼び出し、各レイヤーに固有の追加属性を定義します。get_config()メソッドは、親の構成メソッドを呼び出し、レイヤーで導入されたカスタム属性を定義します。build()が含まれている場合、トレーニング可能なパラメーターが含まれます。たとえば、 Attention()レイヤーを使用して、より多くの注意を払うために入力し、レイヤーの重みの変化を示す損失信号のバックプロパゲーション。call()メソッドは、入力テンソルで実行される実際の操作です。compute_output_shape()メソッドは間隔で回避されます。 これらのレイヤーは、Keras統合を備えた他のTensorflow層と同様に、数秒以内にプロジェクト(言語モデルまたは他のタイプのRNN)に接続できます。以下の汎用の例を参照してください。
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from layers import Attention
X = Input(shape=(sequence_length,), batch_size=batch_size) # define input layer for summary
## Token Embedding (Pretrained or Not) ##
embedding = Embedding(input_dim=vocabulary_size, output_dim=embedded_dimensions)(X)
## Encoding Recurrent Layers ##
encoder = LSTM(units=recurrent_units, return_sequences=True)(embedding) # keep timesteps
## Decoding with Attention ##
decoder, attention_weights = Attention(context='many-to-one', alignment_type=attention_type, model_api='functional')(encoder)
## Prediction Layer ##
Y = Dense(units=vocabulary_size, activation='softmax')(decoder)
alignment_typeは、 'global' 、 'local-m' 、 'local-p' 、および'local-p*'の1つです。自己注意のために、代わりにSelfAttention(size=attention_size)レイヤーに電話してください。
その他の例、分析、および比較については、以下のサブトピックを確認してください。公正な比較のために、すべての比較モデルは同様のパラメーターを利用します。たとえば、いくつかの例では、 100のバッチサイズと20のエポックの多数が好まれました。
IMBDレビューデータセット内のexamples/sentiment_classification.pyのセンチメント分類(多面、バイナリ)の例を見つけることができます。この例では、3つの異なるtf.keras.Model() ( functional api )モデル(すべての単語レベル)を比較し、従来のMLP(マルチ層パーセプトロン)モデルで実装された自己触媒層の有効性を測定することを目的としています。メトリックについては、以下の表を参照してください。
| モデルID | 最大検証バイナリ精度 |
|---|---|
| 単純な多層パーセプトロンモデル | 0.8730 |
| 単純な多層パーセプトロンモデルを備えた自己触媒(非ペナライズ) | 0.8907 |
| 単純なマルチレイヤーパーセプトロンモデルを備えた自己告発(ペナルティ化) | 0.8870 |
examples/text_generation.py内のシェークスピアデータセットでテキスト生成(多〜1対1)の例を見つけることができます。この例では、3つの異なるtf.keras.Model() ( functional api )モデル(すべてのキャラクターレベル)を比較し、従来のLSTM(長期記憶)モデルに対する実装された注意層と自己関節層の有効性を測定することを目的としています。メトリックについては、以下の表を参照してください。
| モデルID | 最大検証カテゴリの精度 |
|---|---|
| LSTMモデル | 0.5953 |
| LSTMモデルw/ selftention(非包括的) | 0.6049 |
| LSTMモデルw/ local-p*注意 | 0.6234 |
examples/document_classification.py内のロイターデータセットでドキュメント(ニュース)分類(多面1対1のマルチクラス)の例を見つけることができます。この例では、4つの異なるtf.keras.Model() ( functional api )モデル(すべての単語レベル)を比較し、従来のLSTM(長期記憶)モデルにおける実装された注意と自己関節層の有効性を測定することを目的としています。メトリックについては、以下の表を参照してください。
| モデルID | 最大検証カテゴリの精度 |
|---|---|
| LSTMモデル | 0.7210 |
| LSTMモデルw/ selftention(非包括的) | 0.7790 |
| グローバルな注意付きLSTMモデル | 0.7496 |
| LSTMモデルw/ local-p*注意 | 0.7446 |
examples/machine_translation.py内の英語からスペインへのデータセットの機械翻訳の例を見つけることができます。この例は、いくつかの適応を伴うTensorflowの機械翻訳の例にかなり続きます。 4つの異なるtf.keras.Model() ( functional api )モデル(すべての単語レベル)を比較し、実装された注意層の有効性を測定することを目的としています。メトリックについては、以下の表を参照してください。
| モデルID | 最大検証カテゴリの精度 |
|---|---|
| エンコーダデコーダーモデル | 0.8848 |
| グローバルな注意付きエンコーダデコーダーモデル | 0.8860 |
| ローカル-Mの注意付きエンコーダデコーダーモデル | 0.9524 |
| ローカルPの注意付きエンコーダデコーダーモデル | 0.8873 |
遭遇したバグ、パフォーマンスの懸念、または念頭に置いているあらゆる種類の入力であろうと、これはそれらを共有するのに最適な時期です!このトピックの詳細とガイドラインについては、 CONTRIBUTING.md確認してください。


