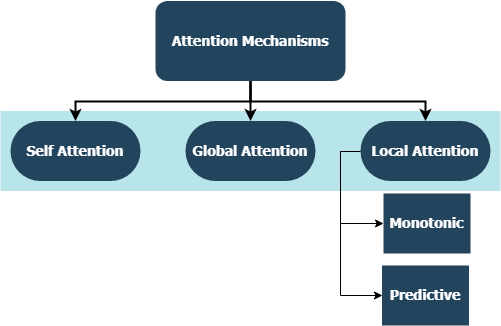
attention mechanisms
1.0.0
이 저장소에는 텐서 플로 및 케라 통합과 호환되는 온 가족주의 메커니즘을위한 맞춤형 레이어 구현이 포함되어 있습니다. 주의 메커니즘은 기계 번역의 환경을 변화 시켰으며, 다른 자연어 처리 및 이해의 다른 영역에서의 활용은 매일 증가하고 있습니다. 더 넓은 의미에서, 그들은 RNN에서 불리한 압축과 정보 손실을 제거하는 것을 목표로한다. 이들은 시퀀스-시퀀스 모델에서 재발 층에 의해 입력 시퀀스에서 파생 된 숨겨진 상태의 고정 길이 인코딩으로 인해 발생합니다. 이 저장소의 레이어는 다수 및 다중 시퀀스 작업 모두에 사용될 수 있습니다. 응용 프로그램에는 감정 분류 , 텍스트 생성 , 기계 번역 및 질문 응답이 포함됩니다. 이 프로젝트는 곧 파이썬 패키지로 배포 될 것이라고 언급하는 것도 가치가 있습니다. 이 프로젝트에 기여하는 방법에 대한 기고 하위 섹션을 확인하십시오.
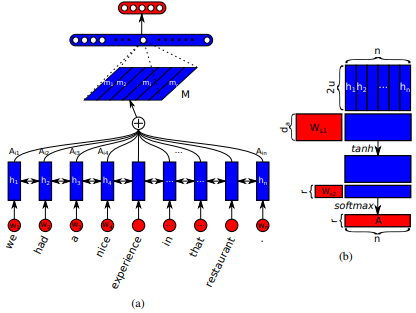
Jianpeng Cheng et al . 아이디어는 여러 구성 요소가 함께 시퀀스의 전체 의미를 형성한다는 주장에 기초하여 입력 순서에서 파생 된 동일한 숨겨진 상태 공간의 다른 위치를 관련시키는 것입니다. 이 접근법은 여러 홉 주의를 통해 이러한 다르게 배치 된 정보를 모았습니다. 이 특정 구현 은 Zhouhan Lin et al. 여기서 저자는주의 메커니즘이 항상 유사한 주석 가중치를 제공하는 경우 임베딩 행렬의 중복 문제를 방지하기 위해 정규화에 대한 추가 손실 메트릭을 제안합니다.
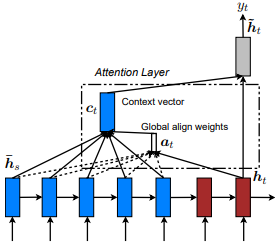
Dzmitry Bahdanau et al. 아이디어는 인코더 RNN의 모든 숨겨진 상태를 기반으로 컨텍스트 벡터를 도출하는 것입니다. 따라서 이러한 유형의주의는 전체 입력 상태 공간에 참석한다고 합니다.
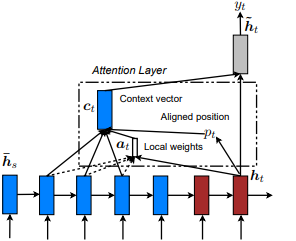
쇼, 참석 및 말하기 : Kelvin Xu et al. Minh -Thang Luong et al. 아이디어는 입력 순서에서 파생 된 숨겨진 상태에서 작은 토큰의 작은 하위 집합에 초점을 맞추면서 세심한 전 세계주의 비용을 제거하는 것입니다. 이 창은 [p_t-D, p_t+D] 로 제안되며, 여기서 D=width , 우리는 시퀀스 경계를 교차하는 위치를 무시합니다. 정렬 된 위치, p_t 는 a) 단조로운 정렬 : set p_t=t , 또는 b) 예측 정렬 : set p_t = S*sigmoid(FC1(tanh(FC2(h_t))) 통해 결정됩니다. 완전히 연결된 층이 훈련 할 수없는 무게 값이 비슷하기 때문에 tf.cast() 가 불가능합니다. 정렬 된 위치 플로트 값 및 가우스 분포를 사용하여 실제 창을 슬라이스하는 대신 모든 소스 숨겨진 상태의 h_t 을 조정합니다. C) 완전히 예측 된 정렬을 제안합니다. P_T는 h_s 에서 p_t 설정합니다. 그런 다음 상단 @window_width 위치를 선택하여 컨텍스트 벡터를 구축하고 나머지는 0을 제로하십시오. 현재이 옵션은 다중 시나리오에서만 유용 할 수 있습니다.
Zichao Yang et al. 아이디어는 문서 내에 존재하는 계층 구조를 반영하는 것입니다. 원래 논문은 단어 및 문장 수준에서 순차적으로주의 메커니즘을 적용함으로써 상향식 접근법을 제안하지만 하향식 접근법 (예 : 단어 및 문자 수준)도 적용됩니다. 따라서 이러한 유형의 메커니즘은 문서 표현을 구성 할 때 다수의 덜 중요한 컨텐츠에 다르게 참석한다고합니다.
각 함수는 대상 숨겨진 상태 ( h_t )와 소스 숨겨진 상태 ( h_s )가 주어지면 정렬 점수를 계산하려고합니다.
| 이름 | 공식 | 정의 |
|---|---|---|
| 도트 제품 | Luong et al. (2015) | |
| 스케일링 된 도트 제품 | Vaswani et al. (2017) | |
| 일반적인 | Luong et al. (2015) | |
| 콘서트 | Bahdanau et al. (2015) | |
| 위치 | Luong et al. (2015) |
여기서 H 는 인코더 RNN이 제공하는 숨겨진 상태의 수와 W_a 및 v_a 훈련 가능한 중량 매트릭스입니다.
tf.keras.layers.Layer() 의 서브 클래스입니다.__init__() 메소드는 부모의 초기화 메소드를 호출하고 각 레이어에 맞는 추가 속성을 정의합니다.get_config() 메소드는 부모의 구성 메소드를 호출하고 레이어에 소개 된 사용자 정의 속성을 정의합니다.build() 포함 된 경우 훈련 가능한 매개 변수가 포함되어 있습니다. 예를 들어 Attention() 레이어를 예를 들어, 더 많은주의를 기울일 수있는 입력을 입력하여 층의 가중치의 변화를 나타냅니다.call() 메소드는 입력 텐서에서 수행되는 실제 작업입니다.compute_output_shape() 메소드는 간격을 피합니다. 이 레이어는 Keras 통합 기능이있는 다른 텐서 플로우 레이어와 마찬가지로 몇 초 안에 프로젝트 (언어 모델 또는 다른 유형의 RNN)에 연결할 수 있습니다. 예를 들어 다음과 같이 아래의 일반 목적 예를 참조하십시오.
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from layers import Attention
X = Input(shape=(sequence_length,), batch_size=batch_size) # define input layer for summary
## Token Embedding (Pretrained or Not) ##
embedding = Embedding(input_dim=vocabulary_size, output_dim=embedded_dimensions)(X)
## Encoding Recurrent Layers ##
encoder = LSTM(units=recurrent_units, return_sequences=True)(embedding) # keep timesteps
## Decoding with Attention ##
decoder, attention_weights = Attention(context='many-to-one', alignment_type=attention_type, model_api='functional')(encoder)
## Prediction Layer ##
Y = Dense(units=vocabulary_size, activation='softmax')(decoder)
여기서 alignment_type 는 'global' , 'local-m' , 'local-p' 및 'local-p*' 중 하나입니다. 자기주의를 기울 이려면 대신 SelfAttention(size=attention_size) 레이어를 호출하십시오.
더 많은 예, 분석 및 비교는 아래 하위 지역을 확인하십시오. 공정한 비교를 위해, 모든 비교 모델은 유사한 매개 변수를 사용합니다. 예를 들어, 일부 예에서는 100 의 배치 크기와 20 개의 에포크가 선호되었습니다.
IMBD 검토 데이터 세트 내부의 examples/sentiment_classification.py 에서 감정 분류 (다-하나, 이진) 예제를 찾을 수 있습니다. 이 예제는 세 가지 별개의 tf.keras.Model() ( Functional API ) 모델 (모든 단어 수준)을 비교하고 기존 MLP (Multi Layer Perceptron) 모델에 대한 구현 된 자체 변환 계층의 효과를 측정하는 것을 목표로합니다. 메트릭은 아래 표를 참조하십시오.
| 모델 ID | 최대 유효성 검증 이진 정확도 |
|---|---|
| 간단한 다층 퍼셉트론 모델 | 0.8730 |
| 자체 변환이있는 간단한 다층 퍼셉트론 모델 (비 임금) | 0.8907 |
| 자체 변환 (처벌) w/ self-rayer perceptron 모델 | 0.8870 |
셰익스피어 데이터 세트 내부의 텍스트 생성 (다면) examples/text_generation.py 를 찾을 수 있습니다. 이 예제는 세 가지 별개의 tf.keras.Model() ( 기능적 API ) 모델 (모든 문자 수준)을 비교하고 기존 LSTM (긴 단기 메모리) 모델에 대한 구현 된 주의력 및 자체 변환 계층의 효과를 측정하는 것을 목표로합니다. 메트릭은 아래 표를 참조하십시오.
| 모델 ID | 최대 유효성 검사 범주 정확도 |
|---|---|
| LSTM 모델 | 0.5953 |
| 자체 변환 (비 임금) w/ lstm 모델 | 0.6049 |
| LSTM 모델로 LOCAL-P*주의 | 0.6234 |
로이터 데이터 세트 내부 examples/document_classification.py 에서 문서 (뉴스) 분류 (다중 클래스) 예제를 찾을 수 있습니다. 이 예제는 4 개의 별개의 tf.keras.Model() ( Functional API ) 모델 (모든 단어 수준)을 비교하고 기존의 LSTM (긴 단기 메모리) 모델에 대한 구현 된주의 및 자체 변환 계층의 효과를 측정하는 것을 목표로합니다. 메트릭은 아래 표를 참조하십시오.
| 모델 ID | 최대 유효성 검사 범주 정확도 |
|---|---|
| LSTM 모델 | 0.7210 |
| 자체 변환 (비 임금) w/ lstm 모델 | 0.7790 |
| 글로벌주의가있는 LSTM 모델 | 0.7496 |
| LSTM 모델로 LOCAL-P*주의 | 0.7446 |
English-to-Spanish 데이터 세트 내부의 Machine Translation (다수) examples/machine_translation.py 를 찾을 수 있습니다. 이 예제는 약간의 적응과 함께 Tensorflow의 기계 번역 예제를 따릅니다. 4 개의 별개의 tf.keras.Model() ( Functional API ) 모델 (모든 단어 수준)을 비교하고 구현 된주의 레이어의 효과를 측정하는 것을 목표로합니다. 메트릭은 아래 표를 참조하십시오.
| 모델 ID | 최대 유효성 검사 범주 정확도 |
|---|---|
| 인코더 디코더 모델 | 0.8848 |
| 글로벌주의가있는 인코더 디코더 모델 | 0.8860 |
| 로컬 M주의가있는 인코더 디코더 모델 | 0.9524 |
| 로컬 P주의가있는 인코더 디코더 모델 | 0.8873 |
만난 버그이든, 성능 문제 또는 염두에두고있는 모든 종류의 입력에 관계없이, 이것은 그것들을 공유하기에 완벽한시기입니다! 이 주제에 대한 자세한 정보 및 지침은 CONTRIBUTING.md 확인하십시오.


