attention mechanisms
1.0.0
Repositori ini mencakup implementasi lapisan khusus untuk seluruh keluarga mekanisme perhatian, kompatibel dengan integrasi TensorFlow dan Kera. Mekanisme perhatian telah mengubah lanskap terjemahan mesin, dan pemanfaatannya di domain lain dari pemrosesan & pemahaman bahasa alami semakin meningkat dari hari ke hari. Dalam arti yang lebih luas, mereka bertujuan untuk menghilangkan kompresi yang tidak menguntungkan dan kehilangan informasi dalam RNN. Ini berasal karena pengkodean panjang tetap dari keadaan tersembunyi yang berasal dari urutan input oleh lapisan berulang dalam model urutan-ke-urutan. Lapisan-lapisan dalam repositori ini dapat digunakan untuk tugas-tugas yang banyak-ke-banyak dan banyak-ke-satu . Aplikasi termasuk klasifikasi sentimen , pembuatan teks , terjemahan mesin , dan menjawab pertanyaan . Penting juga untuk menyebutkan bahwa proyek ini akan segera digunakan sebagai paket Python. Periksa kontribusi yang berkontribusi tentang cara berkontribusi pada proyek ini.
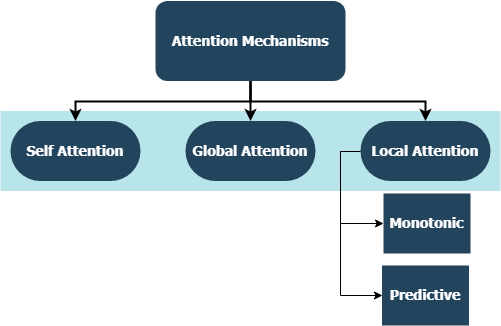
Pertama kali diperkenalkan dalam jaringan memori jangka pendek untuk membaca mesin oleh Jianpeng Cheng et al. Idenya adalah untuk menghubungkan posisi yang berbeda dari ruang keadaan tersembunyi yang sama yang berasal dari urutan input, berdasarkan argumen bahwa beberapa komponen bersama -sama membentuk semantik keseluruhan dari suatu urutan. Pendekatan ini menyatukan informasi yang diposisikan secara berbeda ini melalui banyak perhatian. Implementasi khusus ini mengikuti kalimat-kalimat diri terstruktur yang menanamkan oleh Zhouhan Lin et al. di mana penulis mengusulkan metrik kerugian tambahan untuk regularisasi untuk mencegah masalah redundansi dari matriks embedding jika mekanisme perhatian selalu memberikan bobot anotasi yang serupa.
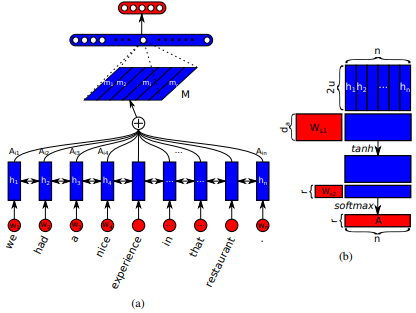
Pertama kali diperkenalkan dalam terjemahan mesin saraf dengan belajar bersama untuk menyelaraskan dan menerjemahkan oleh Dzmitry Bahdanau et al. Idenya adalah untuk memperoleh vektor konteks berdasarkan semua keadaan tersembunyi dari rnn encoder. Oleh karena itu, dikatakan bahwa jenis perhatian ini menghadiri seluruh ruang keadaan input.
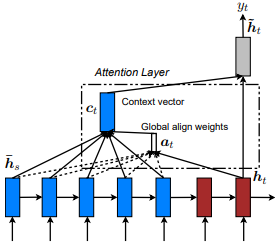
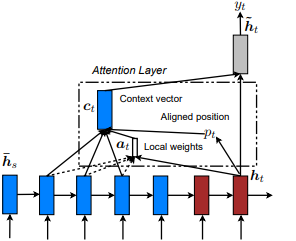
Pertama kali diperkenalkan dalam pertunjukan, hadir, dan katakan: Generasi Keterangan Gambar Saraf dengan Perhatian Visual oleh Kelvin Xu et al. dan disesuaikan dengan NLP dalam pendekatan yang efektif untuk terjemahan mesin saraf berbasis perhatian oleh Minh-Ther Luong et al. Idenya adalah untuk menghilangkan biaya perhatian yang penuh perhatian dengan malah berfokus pada subset kecil token di negara -negara tersembunyi yang ditetapkan dari urutan input. Jendela ini diusulkan sebagai [p_t-D, p_t+D] di mana D=width , dan kami mengabaikan posisi yang melintasi batas urutan. Posisi yang selaras, p_t , diputuskan baik melalui A) Alignment monotonik: Set p_t=t , atau b) Penyelarasan prediktif : Set p_t = S*sigmoid(FC1(tanh(FC2(h_t))) di mana lapisan yang sama-sama tidak dapat dilatih, karena tidak ada pada nilai-metode yang tidak dapat tf.cast() . Nilai float posisi yang selaras dan menggunakan distribusi Gaussian untuk menyesuaikan p_t perhatian dari semua status tersembunyi sumber alih -alih mengiris jendela h_t h_s . Kemudian, pilih posisi @window_width untuk membangun vektor konteks dan nol sisanya. Saat ini, opsi ini hanya tersedia untuk banyak skenario.
Pertama kali diperkenalkan dalam jaringan perhatian hierarkis untuk klasifikasi dokumen oleh Zichao Yang et al. Idenya adalah untuk mencerminkan struktur hierarkis yang ada di dalam dokumen. Makalah asli mengusulkan pendekatan bottom-up dengan menerapkan mekanisme perhatian secara berurutan pada tingkat kata dan kalimat, tetapi pendekatan top-down (mis. Level Word- dan karakter) juga berlaku. Oleh karena itu, jenis mekanisme ini dikatakan menghadiri konten yang lebih berbeda dengan yang lebih penting ketika membangun representasi dokumen.
Setiap fungsi mencoba menghitung skor penyelarasan yang diberikan Target Hidden State ( h_t ) dan Sumber Hidden States ( h_s ).
| Nama | Formula untuk | Didefinisikan oleh |
|---|---|---|
| Produk titik | Luong et al. (2015) | |
| Produk DOT yang diskalakan | Vaswani et al. (2017) | |
| Umum | Luong et al. (2015) | |
| Concat | Bahdanau et al. (2015) | |
| Lokasi | Luong et al. (2015) |
di mana H adalah jumlah status tersembunyi yang diberikan oleh rnn encoder, dan di mana W_a dan v_a adalah matriks berat yang dapat dilatih.
tf.keras.layers.Layer() .__init__() dari setiap kelas khusus memanggil metode inisialisasi induknya dan mendefinisikan atribut tambahan yang spesifik untuk setiap lapisan.get_config() memanggil metode konfigurasi induknya dan mendefinisikan atribut khusus yang diperkenalkan dengan lapisan.build() , maka itu berisi parameter yang dapat dilatih. Ambil Lapisan Attention() misalnya, backpropagasi dari sinyal kerugian yang input untuk memberikan lebih banyak perawatan dan karenanya menunjukkan perubahan bobot lapisan.call() adalah operasi aktual yang dilakukan pada tensor input.compute_output_shape() dihindari untuk jarak. Lapisan-lapisan ini dapat dicolokkan ke proyek Anda (apakah model bahasa atau jenis RNN lainnya) dalam hitungan detik, seperti halnya lapisan tensorflow lainnya dengan integrasi keras. Lihat contoh tujuan umum di bawah ini misalnya:
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from layers import Attention
X = Input(shape=(sequence_length,), batch_size=batch_size) # define input layer for summary
## Token Embedding (Pretrained or Not) ##
embedding = Embedding(input_dim=vocabulary_size, output_dim=embedded_dimensions)(X)
## Encoding Recurrent Layers ##
encoder = LSTM(units=recurrent_units, return_sequences=True)(embedding) # keep timesteps
## Decoding with Attention ##
decoder, attention_weights = Attention(context='many-to-one', alignment_type=attention_type, model_api='functional')(encoder)
## Prediction Layer ##
Y = Dense(units=vocabulary_size, activation='softmax')(decoder)
di mana alignment_type adalah salah satu dari 'global' , 'local-m' , 'local-p' , dan 'local-p*' . Untuk perhatian diri, hubungi lapisan SelfAttention(size=attention_size) sebagai gantinya.
Periksa di bawah subtopik untuk lebih banyak contoh, analisis, dan perbandingan. Untuk perbandingan yang adil, semua model dibandingkan menggunakan parameter yang sama. Misalnya, ukuran batch 100 dan sejumlah zaman 20 lebih disukai pada beberapa contoh.
Anda dapat menemukan contoh klasifikasi sentimen (banyak-ke-satu, biner) pada dataset ulasan IMBD di dalam examples/sentiment_classification.py . Contoh ini membandingkan tiga model tf.keras.Model() ( API fungsional ) yang berbeda (semua tingkat kata) dan bertujuan untuk mengukur efektivitas lapisan perhatian diri yang diimplementasikan pada model MLP (multi-lapisan Perceptron) konvensional. Lihat tabel di bawah ini untuk metrik:
| ID Model | Akurasi biner validasi maksimum |
|---|---|
| Model Perceptron Multi-Layer Sederhana | 0.8730 |
| Model Perceptron Multi-Layer Sederhana dengan Perhatian Mandiri (Non-Penalized) | 0.8907 |
| Model Perceptron Multi-Layer Sederhana W/ Self-Itention (dihukum) | 0.8870 |
Anda dapat menemukan contoh generasi teks (banyak-ke-satu) pada dataset Shakespeare di dalam examples/text_generation.py . Contoh ini membandingkan tiga model tf.keras.Model() ( API fungsional ) yang berbeda (semua tingkat karakter) dan bertujuan untuk mengukur efektivitas perhatian yang diimplementasikan dan lapisan-lapisan perhatian pada model LSTM (memori jangka pendek) konvensional. Lihat tabel di bawah ini untuk metrik:
| ID Model | Akurasi kategori validasi maksimum |
|---|---|
| Model LSTM | 0.5953 |
| Model LSTM dengan perhatian diri (non-penal) | 0.6049 |
| Model LSTM dengan Lokal-P* Perhatian | 0.6234 |
Anda dapat menemukan Contoh Klasifikasi Dokumen (Berita) (banyak-ke-satu, multi-kelas) pada dataset Reuters di dalam examples/document_classification.py . Contoh ini membandingkan empat model tf.keras.Model() ( API fungsional ) yang berbeda (semua tingkat kata) dan bertujuan untuk mengukur efektivitas perhatian yang diimplementasikan dan lapisan-lapisan perhatian pada model LSTM (memori jangka pendek) konvensional. Lihat tabel di bawah ini untuk metrik:
| ID Model | Akurasi kategori validasi maksimum |
|---|---|
| Model LSTM | 0.7210 |
| Model LSTM dengan perhatian diri (non-penal) | 0.7790 |
| Model LSTM dengan perhatian global | 0.7496 |
| Model LSTM dengan Lokal-P* Perhatian | 0.7446 |
Anda dapat menemukan contoh terjemahan mesin (banyak-ke-banyak) pada dataset bahasa Inggris-ke-Spanyol di dalam examples/machine_translation.py . Contoh ini cukup banyak mengikuti contoh terjemahan mesin TensorFlow dengan beberapa adaptasi. Ini membandingkan empat model tf.keras.Model() ( API fungsional ) yang berbeda (semua tingkat kata) dan bertujuan untuk mengukur efektivitas lapisan perhatian yang diimplementasikan. Lihat tabel di bawah ini untuk metrik:
| ID Model | Akurasi kategori validasi maksimum |
|---|---|
| Model Encoder-Decoder | 0.8848 |
| Model encoder-decoder dengan perhatian global | 0.8860 |
| Model Encoder-Decoder W/ Local-M Perhatian | 0.9524 |
| Model Encoder-Decoder W/ Local-P Perhatian | 0.8873 |
Apakah itu bug yang telah Anda temui, masalah kinerja, atau input apa pun yang ada dalam pikiran Anda, ini adalah waktu yang tepat untuk membagikannya! Periksa CONTRIBUTING.md untuk informasi lebih lanjut dan pedoman tentang topik ini.


