attention mechanisms
1.0.0
Este repositorio incluye implementaciones de capas personalizadas para una familia completa de mecanismos de atención, compatibles con la integración de TensorFlow y Keras. Los mecanismos de atención han transformado el panorama de la traducción automática, y su utilización en otros dominios del procesamiento y comprensión del lenguaje natural aumenta día a día. En un sentido más amplio, su objetivo es eliminar la compresión y pérdida de información en desventaja en los RNN. Estos se originan debido a la codificación de longitud fija de estados ocultos derivados de secuencias de entrada por capas recurrentes en modelos de secuencia a secuencia. Las capas en este repositorio se pueden usar para tareas de secuencia de muchos a muchos a uno . Las aplicaciones incluyen clasificación de sentimientos , generación de texto , traducción automática y respuesta de preguntas . También vale la pena mencionar que este proyecto pronto se implementará como un paquete de Python. Verifique la subsección contribuyente sobre cómo contribuir a este proyecto.
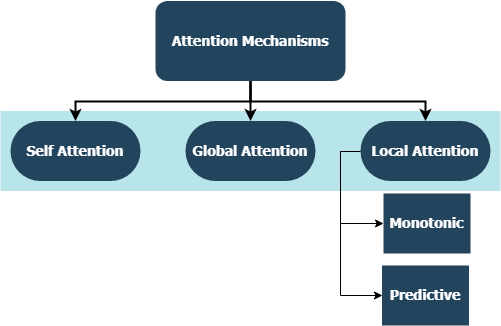
Primero introducido en las redes de memoria a corto plazo para la lectura de la máquina por Jianpeng Cheng et al. La idea es relacionar diferentes posiciones del mismo espacio de estado oculto derivado de la secuencia de entrada, en base al argumento de que múltiples componentes juntos forman la semántica general de una secuencia. Este enfoque reúne esta información posicionada de manera diferente a través de la atención de múltiples lúpulos . Esta implementación en particular sigue una oración estructurada de atención autoensejada integrada por Zhouhan Lin et al. Cuando los autores proponen una métrica de pérdida adicional para la regularización para evitar los problemas de redundancia de la matriz de incrustación si el mecanismo de atención siempre proporciona pesos de anotación similares.
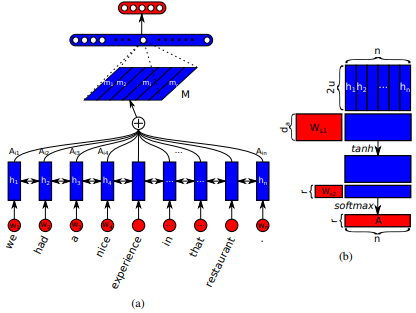
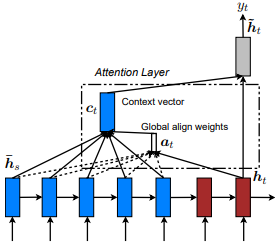
Introducido por primera vez en la traducción del automóvil neural mediante el aprendizaje conjunta para alinearse y traducir por Dzmitry Bahdanau et al. La idea es derivar un vector de contexto basado en todos los estados ocultos del codificador RNN. Por lo tanto, se dice que este tipo de atención atiende a todo el espacio de estado de entrada.
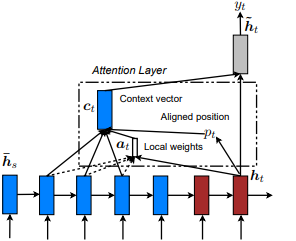
Presentado por primera vez en Show, Asistir y contar: Generación de subtítulos de imágenes neuronales con atención visual de Kelvin Xu et al. y adaptado a la PNL en enfoques efectivos para la traducción de la máquina neuronal basada en la atención por Minh-Thang Luong et al. La idea es eliminar el costo atento de la atención global al centrarse en un pequeño subconjunto de tokens en estados ocultos establecidos derivados de la secuencia de entrada. Esta ventana se propone como [p_t-D, p_t+D] donde D=width , y ignoramos las posiciones que cruzan los límites de la secuencia. La posición alineada, p_t , se decide a través de a) alineación monotónica: set p_t=t , o b) alineación predictiva : establecer p_t = S*sigmoid(FC1(tanh(FC2(h_t))) tf.cast() las capas totalmente conectadas son un peso entrenable. Un valor de flota de posición alineada y utiliza la distribución gaussiana para ajustar p_t pesos de atención de todos los estados ocultos de la h_s en lugar de cortar la ventana h_t . Luego, elija posiciones Top @window_width para construir el vector de contexto y cero el resto. Actualmente, esta opción solo es disponible para escenarios de muchos a uno.
Primero introducido en redes de atención jerárquica para la clasificación de documentos por Zichao Yang et al. La idea es reflejar la estructura jerárquica que existe dentro de los documentos. El documento original propone un enfoque ascendente aplicando mecanismos de atención secuencialmente a nivel de palabra y oración, pero también es aplicable un enfoque de arriba hacia abajo (por ejemplo de palabras y caracteres). Por lo tanto, se dice que este tipo de mecanismos asista de manera diferencial a un contenido cada vez menos importante al construir la representación del documento.
Cada función está tratando de calcular una puntuación de alineación dado un estado oculto de destino ( h_t ) y estados ocultos de origen ( h_s ).
| Nombre | Fórmula para | Definido por |
|---|---|---|
| Producto de punto | Luong et al. (2015) | |
| Producto de puntos a escala | Vaswani et al. (2017) | |
| General | Luong et al. (2015) | |
| Concatismo | Bahdanau et al. (2015) | |
| Ubicación | Luong et al. (2015) |
donde H es el número de estados ocultos dados por el codificador RNN, y donde W_a y v_a son matrices de peso entrenables.
tf.keras.layers.Layer() .__init__() de cada clase personalizada llama al método de inicialización de su padre y define atributos adicionales específicos para cada capa.get_config() llama al método de configuración de su padre y define los atributos personalizados introducidos con la capa.build() , entonces contiene parámetros capacitables. Tome la capa Attention() Por ejemplo, la retropropagación de las señales de pérdida que ingresa para dar más cuidado y, por lo tanto, indica un cambio en los pesos de la capa.call() es la operación real que se realiza en los tensores de entrada.compute_output_shape() se evitan para el espacio. Estas capas se pueden conectar a sus proyectos (ya sean modelos de lenguaje u otros tipos de RNN) en segundos, al igual que cualquier otra capa de flujo de tensor con integración de Keras. Vea el siguiente ejemplo de propósito general, por ejemplo:
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from layers import Attention
X = Input(shape=(sequence_length,), batch_size=batch_size) # define input layer for summary
## Token Embedding (Pretrained or Not) ##
embedding = Embedding(input_dim=vocabulary_size, output_dim=embedded_dimensions)(X)
## Encoding Recurrent Layers ##
encoder = LSTM(units=recurrent_units, return_sequences=True)(embedding) # keep timesteps
## Decoding with Attention ##
decoder, attention_weights = Attention(context='many-to-one', alignment_type=attention_type, model_api='functional')(encoder)
## Prediction Layer ##
Y = Dense(units=vocabulary_size, activation='softmax')(decoder)
donde alignment_type es uno de 'global' , 'local-m' , 'local-p' y 'local-p*' . Para la atención propia, llame a la capa de SelfAttention(size=attention_size) en su lugar.
Consulte a continuación los subtópicos para obtener más ejemplos, análisis y comparaciones. Para una comparación justa, todos los modelos comparados utilizan parámetros similares. Por ejemplo, se prefirió un tamaño de lote de 100 y varias épocas de 20 en algunos ejemplos.
Puede encontrar un ejemplo de clasificación de sentimientos (muchos a uno, binario) en el conjunto de datos de revisión de IMBD dentro de examples/sentiment_classification.py . Este ejemplo compara tres modelos distintos de tf.keras.Model() ( API funcional ) (todo el nivel de palabra) y tiene como objetivo medir la efectividad de la capa de autoatención implementada sobre el modelo MLP convencional (múltiples capas perceptron). Consulte la tabla a continuación para ver las métricas:
| ID de modelo | Precisión binaria de validación máxima |
|---|---|
| Modelo simple de perceptrones de múltiples capas | 0.8730 |
| Modelo de perceptrones de múltiples capas simple con autoatención (no penalizado) | 0.8907 |
| Modelo de perceptrones de múltiples capas simple con autoatención (penalizado) | 0.8870 |
Puede encontrar un ejemplo de generación de texto (muchos a uno) en el conjunto de datos Shakespeare dentro de examples/text_generation.py . Este ejemplo compara tres modelos distintos de tf.keras.Model() ( API funcional ) (todo a nivel de caracteres) y tiene como objetivo medir la efectividad de la atención implementada y las capas de autoatensión sobre los modelos LSTM convencionales (memoria a largo plazo). Consulte la tabla a continuación para ver las métricas:
| ID de modelo | Precisión categórica de validación máxima |
|---|---|
| Modelo LSTM | 0.5953 |
| Modelo LSTM con autoatención (no penalizado) | 0.6049 |
| Modelo LSTM con la atención local-P* | 0.6234 |
Puede encontrar un ejemplo de clasificación de documento (noticias) (muchos a uno, múltiples clases) en el conjunto de datos de Reuters dentro de examples/document_classification.py . Este ejemplo compara cuatro modelos distintos de tf.keras.Model() ( API funcional ) (todo el nivel de palabra) y tiene como objetivo medir la efectividad de la atención implementada y las capas de autoatensión sobre los modelos LSTM convencionales (memoria a largo plazo). Consulte la tabla a continuación para ver las métricas:
| ID de modelo | Precisión categórica de validación máxima |
|---|---|
| Modelo LSTM | 0.7210 |
| Modelo LSTM con autoatención (no penalizado) | 0.7790 |
| Modelo LSTM con atención global | 0.7496 |
| Modelo LSTM con la atención local-P* | 0.7446 |
Puede encontrar un ejemplo de traducción automática (muchos a muchos) en el conjunto de datos en inglés a español dentro de examples/machine_translation.py . Este ejemplo sigue el ejemplo de traducción automática de Tensorflow con algunas adaptaciones. Compara cuatro modelos distintos de tf.keras.Model() ( API funcional ) (todo el nivel de palabras) y tiene como objetivo medir la efectividad de la capa de atención implementada. Consulte la tabla a continuación para ver las métricas:
| ID de modelo | Precisión categórica de validación máxima |
|---|---|
| Modelo de codificador | 0.8848 |
| Modelo de codificador codificador con atención global | 0.8860 |
| Modelo de codificador codificador con atención local-M | 0.9524 |
| Modelo de codificador codificador con atención local-P | 0.8873 |
Ya sea que se trate de errores que haya encontrado, preocupaciones de rendimiento o cualquier tipo de aporte que tenga en mente, ¡este es el momento perfecto para compartirlos! Verifique CONTRIBUTING.md para obtener más información y pautas sobre este tema.


