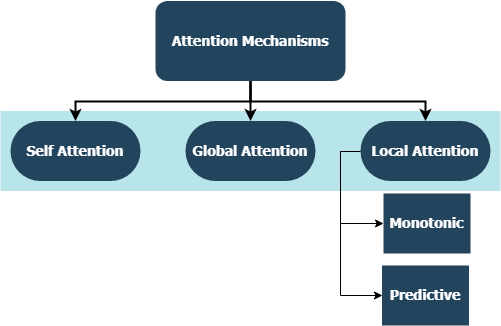
attention mechanisms
1.0.0
Dieses Repository enthält kundenspezifische Schicht -Implementierungen für eine ganze Familie von Aufmerksamkeitsmechanismen, die mit TensorFlow und Keras -Integration kompatibel sind. Aufmerksamkeitsmechanismen haben die Landschaft der maschinellen Übersetzung verändert, und ihre Verwendung in anderen Bereichen der Verarbeitung und des Verständnisses der natürlichen Sprache nimmt von Tag zu Tag zu. In einem breiteren Sinne wollen sie die nachteilige Komprimierung und den Informationsverlust in RNNs beseitigen. Diese entstehen aufgrund der Codierung von versteckten Zuständen mit fester Länge, die aus Eingangssequenzen durch wiederkehrende Schichten in Sequenz-zu-Sequenz-Modellen abgeleitet wurden. Die Ebenen in diesem Repository können sowohl für viele und viele Sequenzaufgaben verwendet werden. Zu den Anwendungen gehören die Klassifizierung der Stimmung , die Textgenerierung , die maschinelle Übersetzung und die Beantwortung von Fragen . Es lohnt sich auch zu erwähnen, dass dieses Projekt bald als Python -Paket eingesetzt wird. Überprüfen Sie, wie Sie einen Beitrag zum Beitrag zu diesem Projekt leisten können.
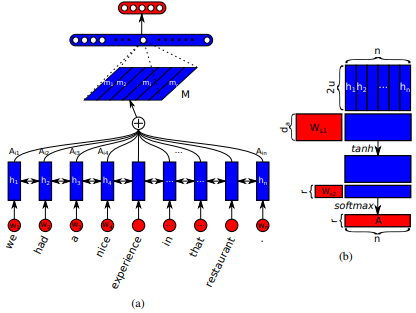
Erste Einführung in langen Kurzzeit-Speicher-Networks für das Lesen von Maschinen von Jianpeng Cheng et al. Die Idee ist, verschiedene Positionen desselben versteckten Zustandsraums in Beziehung zu setzen, die aus der Eingabesequenz abgeleitet wurden, basierend auf dem Argument, dass mehrere Komponenten zusammen die Gesamtsemantik einer Sequenz bilden. Dieser Ansatz bringt diese unterschiedlich positionierten Informationen durch mehrere Hops -Aufmerksamkeit zusammen. Diese spezielle Implementierung folgt einer strukturierten selbstangestellten Satzung von Zhouhan Lin et al. Wenn Autoren eine zusätzliche Verlustmetrik für die Regularisierung vorschlagen, um die Redundanzprobleme der Einbettungsmatrix zu verhindern, wenn der Aufmerksamkeitsmechanismus immer ähnliche Annotationsgewichte liefert.
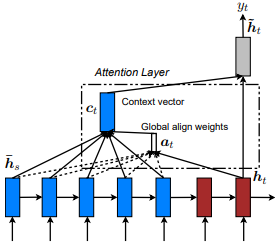
Erste Einführung in neuronaler Maschinenübersetzung durch gemeinsames Lernen, um von Dzmitry Bahdanau et al. Die Idee ist, einen Kontextvektor abzuleiten, der auf allen versteckten Zuständen des Encoder -RNN basiert. Daher wird gesagt, dass diese Art von Aufmerksamkeit den gesamten Eingabestatusraum betraf .
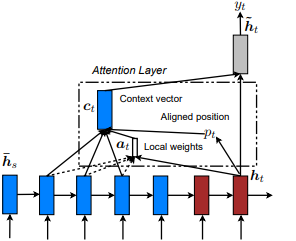
Erste Einführung in Show, Take and Tell: Neural Image Caption Generation mit visueller Aufmerksamkeit von Kelvin Xu et al. und an NLP in effektiven Ansätzen für aufmerksamkeitsbasierte neuronale maschinelle Übersetzung von Minh-Thang Luong et al. Die Idee ist, die aufmerksamen Kosten der globalen Aufmerksamkeit zu beseitigen, indem sie sich stattdessen auf eine kleine Untergruppe von Token in versteckten Zuständen konzentrieren, die aus der Eingabebedingsequenz abgeleitet wurden. Dieses Fenster wird als [p_t-D, p_t+D] vorgeschlagen, wobei D=width , und wir ignorieren Positionen, die die Sequenzgrenzen überschreiten. Die ausgerichtete Position p_t wird entweder durch a) monotonische Ausrichtung entschieden: Set p_t=t oder b) Vorhersageausrichtung : Set p_t = S*Sigmaid (FC1 tf.cast() p_t = S*sigmoid(FC1(tanh(FC2(h_t))) Ein ausgerichteter Positionswert und verwendet p_t Gaußsche Verteilung , h_t die Aufmerksamkeitsgewichte aller versteckten Zapfen der Quelle anzupassen h_s anstatt das tatsächliche Fenster zu schneiden. Wählen Sie dann Top @window_width -Positionen aus, um den Kontextvektor zu erstellen und den Rest zu null. Derzeit ist diese Option nur für viele Szenarien ausreichbar.
Erste Einführung in hierarchischen Aufmerksamkeitsnetzwerken zur Klassifizierung der Dokumente von Zichao Yang et al. Die Idee ist, die hierarchische Struktur widerzuspiegeln, die in Dokumenten existiert. Das ursprüngliche Papier schlägt einen Bottom-up- Ansatz vor, indem Aufmerksamkeitsmechanismen auf Wort- und Satzebene nacheinander angewendet werden, aber auch ein Top-Down- Ansatz (z. B. Wort- und Charakterebene) ist auch anwendbar. Daher soll diese Art von Mechanismen bei der Erstellung der Dokumentdarstellung unterschiedlich zu mehr und weniger wichtigen Inhalten betrafen.
Jede Funktion versucht, eine Ausrichtungsbewertung bei einem versteckten Zustand ( h_t ) und Hidden States ( h_s ) zu berechnen.
| Name | Formel für | Definiert durch |
|---|---|---|
| Punktprodukt | Luong et al. (2015) | |
| Skaliertes Punktprodukt | Vaswani et al. (2017) | |
| Allgemein | Luong et al. (2015) | |
| Concat | Bahdanau et al. (2015) | |
| Standort | Luong et al. (2015) |
wobei H die Anzahl der vom Encoder RNN versteckten Zustände ist und wo W_a und v_a trainierbare Gewichtsmatrizen sind.
tf.keras.layers.Layer() .__init__() -Methode jeder benutzerdefinierten Klasse ruft die Initialisierungsmethode ihres übergeordneten und definiert zusätzliche Attribute, die für jede Schicht spezifisch sind.get_config() ruft die Konfigurationsmethode ihres übergeordneten und definiert benutzerdefinierte Attribute, die mit der Ebene eingeführt wurden.build() enthält, enthält sie trainierbare Parameter. Nehmen Sie beispielsweise die Backpropagation der Verlustsignale () die Attention() auf. Die Eingaben, die mehr Pflege geben, zeigt eine Änderung der Gewichte der Schicht an.call() -Methode ist die tatsächliche Operation, die an den Eingangstensoren durchgeführt wird.compute_output_shape() Methoden werden für den Abstand vermieden. Diese Ebenen können innerhalb von Sekunden in Ihre Projekte (ob Sprachmodelle oder andere Arten von RNNs) angeschlossen werden, genau wie jede andere Tensorflow-Ebene mit Keras-Integration. Siehe zum Beispiel das Beispiel für das unten stehende Beispiel:
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from layers import Attention
X = Input(shape=(sequence_length,), batch_size=batch_size) # define input layer for summary
## Token Embedding (Pretrained or Not) ##
embedding = Embedding(input_dim=vocabulary_size, output_dim=embedded_dimensions)(X)
## Encoding Recurrent Layers ##
encoder = LSTM(units=recurrent_units, return_sequences=True)(embedding) # keep timesteps
## Decoding with Attention ##
decoder, attention_weights = Attention(context='many-to-one', alignment_type=attention_type, model_api='functional')(encoder)
## Prediction Layer ##
Y = Dense(units=vocabulary_size, activation='softmax')(decoder)
wo alignment_type eines von 'global' , 'local-m' , 'local-p' und 'local-p*' ist. Nennen Sie sich für die Selbstbehandlung stattdessen die SelfAttention(size=attention_size) .
Weitere Beispiele, Analysen und Vergleiche finden Sie unter den Unterthemen. Für einen fairen Vergleich verwenden alle verglichenen Modelle ähnliche Parameter. Beispielsweise wurden an einigen Beispielen eine Chargengröße von 100 und eine Reihe von Epochen von 20 bevorzugt.
Sie finden eine Sentiment-Klassifizierung (viele zu eins, binäre) Beispiele für IMBD-Überprüfungsdatensatz in examples/sentiment_classification.py . Dieses Beispiel vergleicht drei verschiedene tf.keras.Model() ( funktionale API ) -Modelle (alle Wortebene) und zielt darauf ab, die Wirksamkeit der implementierten Selbstbekämpfungsschicht über das herkömmliche MLP-Modell (Multi-Layer-Perzeptron) zu messen. In der folgenden Tabelle finden Sie Metriken:
| Modell ID | Maximale Validierung binärer Genauigkeit |
|---|---|
| Einfaches Mehrschicht-Perzeptron-Modell | 0,8730 |
| Einfaches Mehrschicht-Perzeptron-Modell mit Selbstbekämpfung (nicht penalisiert) | 0,8907 |
| Einfaches Mehrschicht-Perzeptron-Modell mit Selbstbekämpfung (bestraft) | 0,8870 |
Sie finden ein Beispiel für eine Textgenerierung (viele zu eins) auf Shakespeare-Datensatz in examples/text_generation.py . Dieses Beispiel vergleicht drei verschiedene tf.keras.Model() ( funktionale API ) -Modelle (alle Charakterebene) und zielt darauf ab, die Wirksamkeit der implementierten Aufmerksamkeits- und Selbstbekämpfungsschichten gegenüber den herkömmlichen LSTM-Modellen (Long-Time-Memory) (Long-kurzfristigem Speicher) zu messen. In der folgenden Tabelle finden Sie Metriken:
| Modell ID | Maximale Validierungsgenauigkeit |
|---|---|
| LSTM -Modell | 0,5953 |
| LSTM-Modell mit Selbstbekämpfung (nicht penalisiert) | 0,6049 |
| LSTM-Modell mit Lokal-P* Aufmerksamkeit | 0,6234 |
In der Reuters-Datensatz finden Sie in examples/document_classification.py eine Dokumentklassifizierung (viele zu einem, Multi-Class). Dieses Beispiel vergleicht vier verschiedene tf.keras.Model() ( funktionale API ) -Modelle (alle Wortebene) und zielt darauf ab, die Wirksamkeit der implementierten Aufmerksamkeits- und Selbstbekämpfungsschichten gegenüber den herkömmlichen LSTM-Modellen (Long-Time-Memory) (Long-kurzfristigem Speicher) zu messen. In der folgenden Tabelle finden Sie Metriken:
| Modell ID | Maximale Validierungsgenauigkeit |
|---|---|
| LSTM -Modell | 0,7210 |
| LSTM-Modell mit Selbstbekämpfung (nicht penalisiert) | 0,7790 |
| LSTM -Modell mit globaler Aufmerksamkeit | 0,7496 |
| LSTM-Modell mit Lokal-P* Aufmerksamkeit | 0,7446 |
Sie finden ein Beispiel für maschinelle Übersetzung (Viele zu viel) Beispiel für Englisch-zu-spanischer Datensatz in examples/machine_translation.py . In diesem Beispiel folgt das maschinelle Übersetzungsbeispiel von TensorFlow mit einigen Anpassungen. Es vergleicht vier verschiedene tf.keras.Model() ( funktionale API ) -Modelle (alle Wortebene) und zielt darauf ab, die Wirksamkeit der implementierten Aufmerksamkeitsschicht zu messen. In der folgenden Tabelle finden Sie Metriken:
| Modell ID | Maximale Validierungsgenauigkeit |
|---|---|
| Encoder-Decoder-Modell | 0,8848 |
| Encoder-Decoder-Modell mit globaler Aufmerksamkeit | 0,8860 |
| Encoder-Decoder-Modell mit Lokal-M-Aufmerksamkeit | 0,9524 |
| Encoder-Decoder-Modell mit Lokal-P-Aufmerksamkeit | 0,8873 |
Egal, ob es sich um Fehler handelt, die Sie begegnet sind, Leistungsbedenken oder jede Art von Eingaben, die Sie im Sinn haben, dies ist der perfekte Zeitpunkt, um sie zu teilen! Weitere Informationen und Richtlinien zu diesem Thema finden Sie unter CONTRIBUTING.md .


