attention mechanisms
1.0.0
ที่เก็บนี้รวมถึงการใช้เลเยอร์ที่กำหนดเองสำหรับกลไกความสนใจทั้งครอบครัวเข้ากันได้กับการรวม Tensorflow และ Keras กลไกความสนใจได้เปลี่ยนภูมิทัศน์ของการแปลด้วยเครื่องและการใช้ประโยชน์ในโดเมนอื่น ๆ ของการประมวลผลภาษาธรรมชาติและความเข้าใจกำลังเพิ่มขึ้นทุกวัน ในแง่ที่กว้างขึ้นพวกเขามุ่งมั่นที่จะกำจัดการบีบอัดที่เสียเปรียบและการสูญเสียข้อมูลใน RNNs สิ่งเหล่านี้เกิดขึ้นเนื่องจากการเข้ารหัสความยาวคงที่ของสถานะที่ซ่อนอยู่ที่ได้มาจากลำดับอินพุตโดยเลเยอร์กำเริบในรุ่นลำดับต่อลำดับ เลเยอร์ในที่เก็บนี้สามารถใช้สำหรับงานลำดับแบบ หลายต่อหลาย และ หลายต่อหนึ่ง แอปพลิเคชันรวมถึง การจำแนกความเชื่อมั่น การสร้างข้อความ การแปลเครื่อง และ การตอบคำถาม นอกจากนี้ยังคุ้มค่าที่จะพูดถึงว่าโครงการนี้จะถูก นำไปใช้ เป็นแพ็คเกจ Python ในไม่ช้า ตรวจสอบส่วนย่อย ที่มีส่วนร่วม ในการมีส่วนร่วมในโครงการนี้
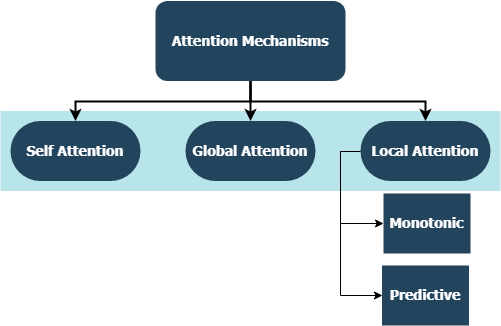
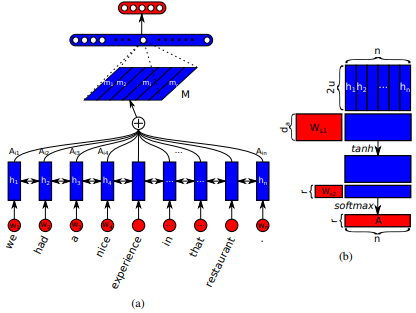
เปิดตัวครั้งแรกใน เครือข่ายหน่วยความจำระยะยาวระยะยาวสำหรับการอ่านเครื่อง โดย Jianpeng Cheng และคณะ แนวคิดคือการเชื่อมโยงตำแหน่งที่แตกต่างกันของพื้นที่สถานะที่ซ่อนอยู่เดียวกันที่ได้มาจากลำดับอินพุตโดยอิงจากอาร์กิวเมนต์ที่หลายองค์ประกอบเข้าด้วยกันเป็นรูปแบบความหมายโดยรวมของลำดับ วิธีการนี้รวบรวมข้อมูลที่อยู่ในตำแหน่งที่แตกต่างกันเหล่านี้ผ่านความสนใจ หลายครั้ง การใช้งานนี้เป็นไปตาม ประโยคที่มีโครงสร้างด้วยตนเองที่ฝัง โดย Zhouhan Lin et al ในกรณีที่ผู้เขียนเสนอตัวชี้วัดการสูญเสียเพิ่มเติมสำหรับการทำให้เป็นปกติเพื่อป้องกันปัญหาความซ้ำซ้อนของเมทริกซ์การฝังหากกลไกความสนใจมักจะให้น้ำหนักคำอธิบายประกอบที่คล้ายกันเสมอ
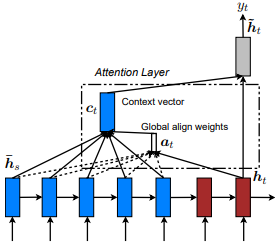
เปิดตัวครั้งแรกใน การแปลเครื่องประสาทโดยการเรียนรู้ร่วมกันเพื่อจัดตำแหน่งและแปล โดย dzmitry Bahdanau และคณะ แนวคิดคือการได้รับเวกเตอร์บริบทตามสถานะที่ซ่อนอยู่ ทั้งหมด ของตัวเข้ารหัส RNN ดังนั้นจึงมีการกล่าวว่าความสนใจประเภทนี้ เข้าร่วม กับพื้นที่สถานะการป้อนข้อมูลทั้งหมด
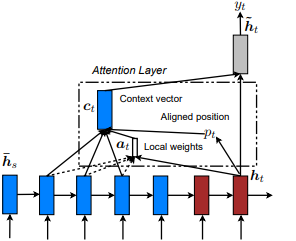
เปิดตัวครั้งแรกใน การแสดงเข้าร่วมและบอก: การสร้างภาพบรรยายภาพด้วยความสนใจทางสายตา โดย Kelvin Xu และคณะ และปรับให้เข้ากับ NLP ใน แนวทางที่มีประสิทธิภาพในการแปลเครื่องประสาทตามความสนใจ โดย Minh-Thang Luong และคณะ แนวคิดคือการกำจัดค่าใช้จ่ายที่เอาใจใส่ในระดับโลกโดยมุ่งเน้นไปที่ชุดย่อยขนาดเล็กของโทเค็นในสถานะที่ซ่อนอยู่ที่ได้รับจากลำดับอินพุต หน้าต่างนี้ถูกเสนอเป็น [p_t-D, p_t+D] โดยที่ D=width และเราไม่สนใจตำแหน่งที่ข้ามลำดับลำดับ ตำแหน่งที่ได้รับการจัดตำแหน่ง p_t ถูกตัดสินใจผ่าน a) การจัดตำแหน่งแบบ monotonic: set p_t=t หรือ b) การจัดตำแหน่งการทำนาย : set p_t = s*sigmoid ( tf.cast() p_t = S*sigmoid(FC1(tanh(FC2(h_t))) ซึ่งเป็นชั้นที่เชื่อมต่อกันอย่างสมบูรณ์ ได้รับตำแหน่งตำแหน่งลอยตัวและใช้การกระจายแบบเกาส์เพื่อปรับ น้ำหนัก p_t สนใจของสถานะที่ซ่อนอยู่ทั้งหมดแทนที่จะหั่น h_t h_s จากนั้นเลือกตำแหน่ง @window_width เพื่อสร้างบริบทเวกเตอร์และเป็นศูนย์ส่วนที่เหลือ ขณะนี้ตัวเลือกนี้เป็นเพียงการใช้งานได้สำหรับสถานการณ์แบบหลายต่อหนึ่งเท่านั้น
เปิดตัวครั้งแรกใน เครือข่ายความสนใจแบบลำดับชั้นสำหรับการจำแนกเอกสาร โดย Zichao Yang และคณะ แนวคิดคือการสะท้อนโครงสร้างลำดับชั้นที่มีอยู่ภายในเอกสาร กระดาษต้นฉบับเสนอวิธีการ จากล่างขึ้นบน โดยใช้กลไกความสนใจตามลำดับที่ระดับคำและประโยค แต่วิธีการ จากบนลงล่าง (เช่นระดับคำและระดับตัวละคร) ก็ใช้ได้เช่นกัน ดังนั้นกลไกประเภทนี้จึงถูกกล่าวว่าเข้าร่วมเนื้อหาที่สำคัญมากขึ้นและน้อยลงเมื่อสร้างการแสดงเอกสาร
แต่ละฟังก์ชั่นกำลังพยายามคำนวณคะแนนการจัดตำแหน่งที่ได้รับสถานะ Hidden State ( h_t ) และแหล่งที่ซ่อนของแหล่งที่มา ( h_s )
| ชื่อ | สูตรสำหรับ | กำหนดโดย |
|---|---|---|
| ผลิตภัณฑ์ DOT | Luong et al. (2015) | |
| ผลิตภัณฑ์ DOT ที่ปรับขนาด | Vaswani และคณะ (2017) | |
| ทั่วไป | Luong et al. (2015) | |
| การต่อ | Bahdanau และคณะ (2015) | |
| ที่ตั้ง | Luong et al. (2015) |
โดยที่ H คือจำนวนสถานะที่ซ่อนอยู่โดยตัวเข้ารหัส RNN และที่ W_a และ v_a เป็นเมทริกซ์น้ำหนักที่ฝึกอบรมได้
tf.keras.layers.Layer()__init__() ของแต่ละคลาสที่กำหนดเองเรียกวิธีการเริ่มต้นของผู้ปกครองและกำหนดคุณลักษณะเพิ่มเติมเฉพาะสำหรับแต่ละเลเยอร์get_config() เรียกใช้วิธีการกำหนดค่าของพาเรนต์และกำหนดคุณลักษณะที่กำหนดเองที่แนะนำด้วยเลเยอร์build() จะมีพารามิเตอร์ที่สามารถฝึกอบรมได้ ใช้ Attention() เลเยอร์ตัวอย่างเช่น backpropagation ของสัญญาณการสูญเสียซึ่งอินพุตเพื่อให้การดูแลมากขึ้นและด้วยเหตุนี้บ่งบอกถึงการเปลี่ยนแปลงของน้ำหนักของเลเยอร์call() คือการดำเนินการจริงที่ดำเนินการบนเทนเซอร์อินพุตcompute_output_shape() หลีกเลี่ยงการเว้นระยะ เลเยอร์เหล่านี้สามารถเสียบเข้ากับโครงการของคุณ (ไม่ว่าจะเป็นแบบจำลองภาษาหรือ RNN ประเภทอื่น ๆ ) ภายในไม่กี่วินาทีเช่นเดียวกับเลเยอร์ TensorFlow อื่น ๆ ที่มีการรวม Keras ดูตัวอย่างอเนกประสงค์ด้านล่าง:
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from layers import Attention
X = Input(shape=(sequence_length,), batch_size=batch_size) # define input layer for summary
## Token Embedding (Pretrained or Not) ##
embedding = Embedding(input_dim=vocabulary_size, output_dim=embedded_dimensions)(X)
## Encoding Recurrent Layers ##
encoder = LSTM(units=recurrent_units, return_sequences=True)(embedding) # keep timesteps
## Decoding with Attention ##
decoder, attention_weights = Attention(context='many-to-one', alignment_type=attention_type, model_api='functional')(encoder)
## Prediction Layer ##
Y = Dense(units=vocabulary_size, activation='softmax')(decoder)
โดยที่ alignment_type เป็นหนึ่งใน 'global' , 'local-m' , 'local-p' และ 'local-p*' เพื่อความสนใจตนเองให้เรียกเลเยอร์ SelfAttention(size=attention_size) แทน
ตรวจสอบด้านล่างย่อยสำหรับตัวอย่างเพิ่มเติมการวิเคราะห์และการเปรียบเทียบ สำหรับการเปรียบเทียบที่เป็นธรรมโมเดลเปรียบเทียบทั้งหมดใช้พารามิเตอร์ที่คล้ายกัน ตัวอย่างเช่นขนาดแบทช์ 100 และจำนวนของยุค 20 เป็นที่ต้องการในบางตัวอย่าง
คุณสามารถค้นหาการจำแนกประเภทความเชื่อมั่น (แบบหลายต่อหนึ่งไบนารี) บน IMBD รีวิวชุดข้อมูลภายใน examples/sentiment_classification.py ตัวอย่างนี้เปรียบเทียบโมเดล tf.keras.Model() ( API ที่ใช้งานได้ ) สามแบบที่แตกต่างกัน (ทุกระดับคำ) และมีจุดมุ่งหมายเพื่อวัดประสิทธิภาพของเลเยอร์การใส่ใจในตัวเองที่นำไปใช้กับโมเดล MLP แบบดั้งเดิม (Multi Layer Perceptron) อ้างถึงตารางด้านล่างสำหรับตัวชี้วัด:
| ID รุ่น | ความแม่นยำในการตรวจสอบความถูกต้องสูงสุดของไบนารี |
|---|---|
| รุ่น Perceptron แบบหลายชั้นอย่างง่าย | 0.8730 |
| โมเดล Perceptron แบบหลายชั้นอย่างง่ายพร้อมด้วยตนเอง | 0.8907 |
| แบบจำลอง Perceptron แบบหลายชั้นอย่างง่ายพร้อมด้วยตนเอง (ถูกลงโทษ) | 0.8870 |
คุณสามารถค้นหาตัวอย่างการสร้างข้อความ (หลายต่อหนึ่ง) ในชุดข้อมูลเช็คสเปียร์ภายใน examples/text_generation.py ตัวอย่างนี้เปรียบเทียบโมเดล tf.keras.Model() ( API ที่ใช้งานได้ ) ที่แตกต่างกันสามแบบ (ระดับอักขระทั้งหมด) และมีจุดมุ่งหมายเพื่อวัดประสิทธิภาพของความสนใจที่นำไปใช้ อ้างถึงตารางด้านล่างสำหรับตัวชี้วัด:
| ID รุ่น | ความแม่นยำในการตรวจสอบความถูกต้องสูงสุด |
|---|---|
| รุ่น LSTM | 0.5953 |
| LSTM Model W/ การตั้งใจด้วยตนเอง (ไม่ใช่ Penalized) | 0.6049 |
| รุ่น LSTM w/ local-p* ความสนใจ | 0.6234 |
คุณสามารถค้นหาการจำแนกประเภทเอกสาร (ข่าว) (ตัวอย่างหลายแบบหลายชั้น) บนชุดข้อมูลของ Reuters ภายใน examples/document_classification.py ตัวอย่างนี้เปรียบเทียบโมเดล tf.keras.Model() (API) (ฟัง ก์ชั่น API ) ที่แตกต่างกันสี่แบบ (ทุกระดับคำ) และมีจุดมุ่งหมายเพื่อวัดประสิทธิภาพของความสนใจที่นำไปใช้ อ้างถึงตารางด้านล่างสำหรับตัวชี้วัด:
| ID รุ่น | ความแม่นยำในการตรวจสอบความถูกต้องสูงสุด |
|---|---|
| รุ่น LSTM | 0.7210 |
| LSTM Model W/ การตั้งใจด้วยตนเอง (ไม่ใช่ Penalized) | 0.7790 |
| รุ่น LSTM พร้อมความสนใจทั่วโลก | 0.7496 |
| รุ่น LSTM w/ local-p* ความสนใจ | 0.7446 |
คุณสามารถค้นหาตัวอย่างการแปลของเครื่อง (หลายต่อหลาย) ในชุดข้อมูลภาษาอังกฤษถึงสเปนภายใน examples/machine_translation.py ตัวอย่างนี้ค่อนข้างติดตามตัวอย่างการแปลของเครื่อง Tensorflow ด้วยการปรับตัว มันเปรียบเทียบสี่ tf.keras.Model() ( API ที่ใช้งานได้ ) แบบจำลอง (ระดับคำทั้งหมด) และมีจุดมุ่งหมายเพื่อวัดประสิทธิภาพของเลเยอร์ความสนใจที่นำไปใช้ อ้างถึงตารางด้านล่างสำหรับตัวชี้วัด:
| ID รุ่น | ความแม่นยำในการตรวจสอบความถูกต้องสูงสุด |
|---|---|
| โมเดลเครื่องเข้ารหัส | 0.8848 |
| โมเดลตัวเข้ารหัส Decoder พร้อมความสนใจทั่วโลก | 0.8860 |
| โมเดลตัวเข้ | 0.9524 |
| โมเดลตัวเข้ารหัส Decoder พร้อมความสนใจในท้องถิ่น | 0.8873 |
ไม่ว่าจะเป็นข้อบกพร่องที่คุณพบความกังวลด้านประสิทธิภาพหรือการป้อนข้อมูลใด ๆ ที่คุณมีอยู่ในใจนี่เป็นเวลาที่เหมาะสำหรับการแบ่งปัน! ตรวจสอบ CONTRIBUTING.md สำหรับข้อมูลเพิ่มเติมและแนวทางในหัวข้อนี้


