attention mechanisms
1.0.0
Este repositório inclui implementações de camada personalizada para toda uma família de mecanismos de atenção, compatíveis com a integração Tensorflow e Keras. Os mecanismos de atenção transformaram o cenário da tradução da máquina e sua utilização em outros domínios do processamento e compreensão da linguagem natural estão aumentando dia a dia. Em um sentido mais amplo, eles pretendem eliminar a compressão desvantajosa e a perda de informações nas RNNs. Estes se originam devido à codificação de comprimento fixo de estados ocultos derivados de sequências de entrada por camadas recorrentes nos modelos de sequência a sequência. As camadas deste repositório podem ser usadas para tarefas de sequência muitas para muitas e muitas para um . As aplicações incluem classificação de sentimentos , geração de texto , tradução da máquina e resposta a perguntas . Também vale a pena mencionar que este projeto será implantado em breve como um pacote Python. Verifique a subseção contribuinte sobre como contribuir para este projeto.
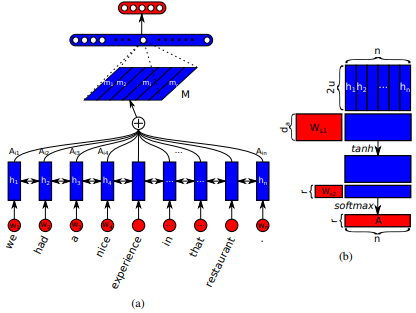
Introduzido pela primeira vez em longas redes de memória de curto prazo para leitura de máquinas por Jianpeng Cheng et al. A idéia é relacionar posições diferentes do mesmo espaço de estado oculto derivado da sequência de entrada, com base no argumento de que vários componentes juntos formam a semântica geral de uma sequência. Essa abordagem reúne essas informações posicionadas de maneira diferente através da atenção de vários lúpulos . Esta implementação em particular segue uma sentença auto-atenta estruturada incorporada por Zhouhan Lin et al. onde os autores propõem uma métrica de perda adicional para regularização para evitar os problemas de redundância da matriz de incorporação se o mecanismo de atenção sempre fornecer pesos de anotação semelhantes.
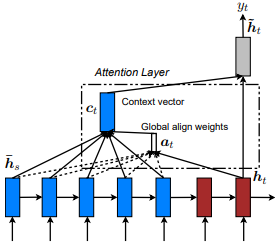
Introduzido pela primeira vez na tradução da máquina neural, aprendendo em conjunto a alinhar e traduzir por Dzmitry Bahdanau et al. A idéia é derivar um vetor de contexto com base em todos os estados ocultos do codificador RNN. Portanto, diz -se que esse tipo de atenção atende a todo o espaço do estado de entrada.
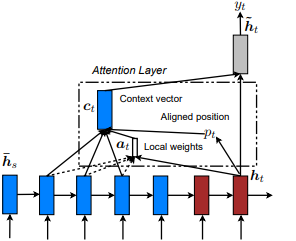
Introduzido pela primeira vez no show, participe e diga: geração de legenda da imagem neural com atenção visual de Kelvin Xu et al. e adaptado ao PNL em abordagens eficazes para a tradução da máquina neural baseada em atenção por Minh-Thang Luong et al. A idéia é eliminar o custo atento da atenção global, concentrando -se em um pequeno subconjunto de tokens em estados ocultos, derivados da sequência de entrada. Esta janela é proposta como [p_t-D, p_t+D] onde D=width , e desconsideramos as posições que cruzam os limites da sequência. A posição alinhada, p_t , é decidida através de a) Alinhamento monotônico: definir p_t=t , ou b) alinhamento preditivo : definir p_t = S*sigmoid(FC1(tanh(FC2(h_t))) em que as camadas totalmente conectadas são as matrizes de peso treinável. Desde a rendição de um indicador e o valor integral tf.cast() Uma posição alinhada no valor da flutuação e usa a distribuição gaussiana para ajustar p_t pesos de atenção de todos os estados ocultos da fonte em vez de h_s a janela h_t . Em seguida, escolha as posições top @window_width para criar o vetor de contexto e zero o restante. Atualmente, essa opção é apenas para cenários muitos para um.
Introduzido pela primeira vez em redes de atenção hierárquica para classificação de documentos por Zichao Yang et al. A idéia é refletir a estrutura hierárquica que existe nos documentos. O artigo original propõe uma abordagem de baixo para cima aplicando mecanismos de atenção sequencialmente nos níveis de palavras e frases, mas também é aplicável uma abordagem de cima para baixo (por exemplo, níveis de palavras e caracteres). Portanto, diz -se que esse tipo de mecanismos comparece diferencialmente a um conteúdo cada vez menos importante ao construir a representação do documento.
Cada função está tentando calcular uma pontuação de alinhamento, dada a um estado oculto de destino ( h_t ) e dos estados ocultos de origem ( h_s ).
| Nome | Fórmula para | Definido por |
|---|---|---|
| Produto Dot | Luong et al. (2015) | |
| Produto DOT em escala | Vaswani et al. (2017) | |
| Em geral | Luong et al. (2015) | |
| Concat | Bahdanau et al. (2015) | |
| Localização | Luong et al. (2015) |
onde H é o número de estados ocultos dados pelo codificador RNN e onde W_a e v_a são matrizes de peso treináveis.
tf.keras.layers.Layer() .__init__() de cada classe personalizada chama o método de inicialização de seus pais e define atributos adicionais específicos para cada camada.get_config() chama o método de configuração de seus pais e define atributos personalizados introduzidos com a camada.build() , ele contém parâmetros treináveis. Veja a camada Attention() , por exemplo, a retropagação dos sinais de perda que entra para dar mais cuidado e, portanto, indica uma alteração nos pesos da camada.call() é a operação real que é realizada nos tensores de entrada.compute_output_shape() são evitados para espaçamento. Essas camadas podem ser conectadas aos seus projetos (sejam modelos de idiomas ou outros tipos de RNNs) em segundos, assim como qualquer outra camada de tensorflow com integração Keras. Veja o exemplo de uso geral abaixo, por exemplo:
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from layers import Attention
X = Input(shape=(sequence_length,), batch_size=batch_size) # define input layer for summary
## Token Embedding (Pretrained or Not) ##
embedding = Embedding(input_dim=vocabulary_size, output_dim=embedded_dimensions)(X)
## Encoding Recurrent Layers ##
encoder = LSTM(units=recurrent_units, return_sequences=True)(embedding) # keep timesteps
## Decoding with Attention ##
decoder, attention_weights = Attention(context='many-to-one', alignment_type=attention_type, model_api='functional')(encoder)
## Prediction Layer ##
Y = Dense(units=vocabulary_size, activation='softmax')(decoder)
onde alignment_type é um dos 'global' , 'local-m' , 'local-p' e 'local-p*' . Para obter atenção, chame a camada SelfAttention(size=attention_size) .
Verifique abaixo os subtópicos para obter mais exemplos, análises e comparações. Para comparação justa, todos os modelos comparados utilizam parâmetros semelhantes. Por exemplo, um tamanho em lote de 100 e várias épocas de 20 foram preferidas em alguns exemplos.
Você pode encontrar um exemplo de classificação de sentimentos (muitos para um, binário) no conjunto de dados do IMBD Reviews Inside examples/sentiment_classification.py . Este exemplo compara três modelos distintos de tf.keras.Model() ( API funcional ) (todo o nível da palavra) e visa medir a eficácia da camada de auto-ataque implementada em relação ao modelo convencional de MLP (perceptron de várias camadas). Consulte a tabela abaixo para métricas:
| ID do modelo | Precisão binária de validação máxima |
|---|---|
| Modelo de perceptron de várias camadas simples | 0,8730 |
| Modelo de perceptron de várias camadas simples com auto-distribuição (não pegamista) | 0,8907 |
| Modelo de perceptron de várias camadas simples com auto-atimento (penalizado) | 0,8870 |
Você pode encontrar um exemplo de geração de texto (muitos para um) no conjunto de dados Shakespeare dentro examples/text_generation.py . Este exemplo compara três modelos distintos de tf.keras.Model() ( API funcional ) (todos no nível do caractere) e visa medir a eficácia das camadas de atenção e auto-distribuição implementadas sobre os modelos LSTM convencionais (memória de longo prazo). Consulte a tabela abaixo para métricas:
| ID do modelo | Precisão categórica de validação máxima |
|---|---|
| Modelo LSTM | 0,5953 |
| Modelo LSTM com auto-distribuição (não penalizada) | 0.6049 |
| Modelo LSTM com Atenção Local-P* | 0,6234 |
Você pode encontrar um exemplo de classificação de documentos (notícias) (muitos para um, multi-classe) no conjunto de dados da Reuters Inside examples/document_classification.py . Este exemplo compara quatro modelos distintos de tf.keras.Model() ( API funcional ) (todo o nível da palavra) e visa medir a eficácia das camadas de atenção e auto-distribuição implementadas sobre os modelos LSTM convencionais (memória de longo prazo). Consulte a tabela abaixo para métricas:
| ID do modelo | Precisão categórica de validação máxima |
|---|---|
| Modelo LSTM | 0,7210 |
| Modelo LSTM com auto-distribuição (não penalizada) | 0,7790 |
| Modelo LSTM com atenção global | 0,7496 |
| Modelo LSTM com Atenção Local-P* | 0,7446 |
Você pode encontrar um exemplo de tradução da máquina (muitos para muitos) sobre o conjunto de dados em inglês para espanhol em examples/machine_translation.py . Este exemplo segue o exemplo de tradução da máquina do TensorFlow com algumas adaptações. Ele compara quatro modelos distintos de tf.keras.Model() ( API funcional ) (todo o nível da palavra) e visa medir a eficácia da camada de atenção implementada. Consulte a tabela abaixo para métricas:
| ID do modelo | Precisão categórica de validação máxima |
|---|---|
| Modelo de codificador-decodificador | 0,8848 |
| Modelo de codificador-decodificador com atenção global | 0,8860 |
| Modelo de codificador-decodificador com atenção local-m | 0,9524 |
| Modelo de codificador-decodificador com atenção local-p | 0,8873 |
Seja bugs que você encontrou, preocupações de desempenho ou qualquer tipo de entrada que você tenha em mente, este é o momento perfeito para compartilhá -los! Verifique CONTRIBUTING.md para obter mais informações e diretrizes sobre este tópico.


