attention mechanisms
1.0.0
Этот репозиторий включает в себя пользовательские реализации слоев для целого семейства механизмов внимания, совместимых с интеграцией Tensorflow и Keras. Механизмы внимания изменили ландшафт машинного перевода, и их использование в других областях обработки и понимания естественного языка увеличивается день ото дня. В более широком смысле они стремятся устранить невыгодное сжатие и потерю информации в RNN. Они происходят из-за кодирования скрытых состояний, полученных из входных последовательностей, рецидивирующими слоями в моделях последовательности к последовательности. Слои в этом репозитории могут использоваться как для задач, так и для последовательностей для многих к одному . Приложения включают классификацию настроений , генерацию текста , машинный перевод и ответ на вопросы . Стоит также упомянуть, что этот проект скоро будет развернут в качестве пакета Python. Проверьте подраздел , как внести свой вклад в этот проект.
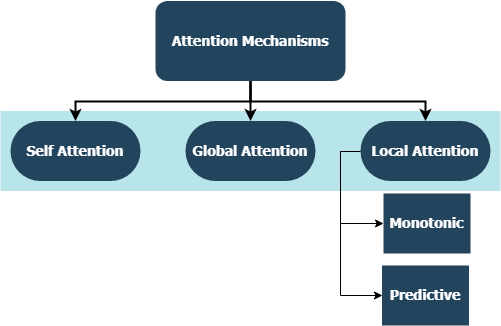
Впервые представлены в длинных кратковременных сетях памяти для чтения машин Jianpeng Cheng et al. Идея состоит в том, чтобы связывать разные позиции одного и того же скрытого пространства состояний, полученного из входной последовательности, на основе аргумента, что множественные компоненты вместе образуют общую семантику последовательности. Этот подход объединяет эту информацию по -разному позиционируемой с помощью множественного внимания хмеля . Эта конкретная реализация следует за структурированным самоотражающим предложением, встраиваемое Zhouhan Lin et al. Если авторы предлагают дополнительную метрику потери для регуляризации, чтобы предотвратить проблемы избыточности матрицы встраивания, если механизм внимания всегда обеспечивает сходные веса аннотации.
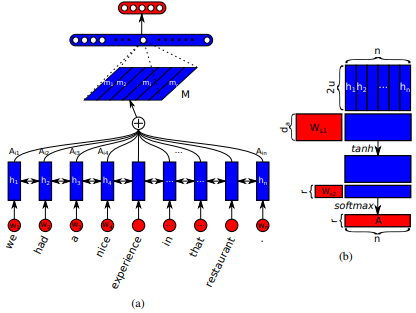
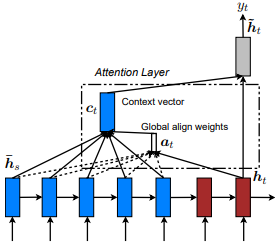
Впервые введено в перевод нервной машины путем совместного обучения для выравнивания и перевода Dzmitry Bahdanau et al. Идея состоит в том, чтобы вывести вектор контекста, основанный на всех скрытых состояниях энкодера RNN. Следовательно, говорят, что этот тип внимания увлекается всем пространством входных состояний.
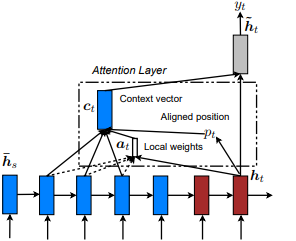
Впервые представлены в Show, посетите и расскажите: генерация подготовительных подготовителей нейронного изображения с визуальным вниманием Кельвина Сюй и соавт. и адаптирован к NLP в эффективных подходах к переводу на основе внимания нейронной машины Minh-Thang Luong et al. Идея состоит в том, чтобы устранить внимательную стоимость глобального внимания, вместо этого сосредоточившись на небольшом подмножестве токенов в скрытых состояниях, полученных из входной последовательности. Это окно предлагается как [p_t-D, p_t+D] где D=width , и мы игнорируем положения, которые границы перекрестной последовательности. Выровненная позиция, p_t , определяется либо через A) монотонное выравнивание: SET p_t=t , или B) прогнозирующее выравнивание : SET p_t = S*sigmoid(FC1(tanh(FC2(h_t))) , где полностью подключенные слои являются обучаемыми весовыми матрицами. Вместо этого значения, а не TF., а не tf.cast() а не в целях. Выровненное значение положения по плаванию и использует гауссовое распределение для регулировки p_t внимания всех скрытых состояний источника вместо h_s , чтобы нарезать h_t окно. Затем выберите Top @window_width Positions, чтобы построить контекстный вектор, а остальные - остальное. В настоящее время этот вариант является доступным только для сценариев.
Впервые представлены в иерархических сетях внимания для классификации документов Zichao Yang et al. Идея состоит в том, чтобы отразить иерархическую структуру, которая существует в документах. Оригинальная статья предлагает подход снизу вверх, применяя механизмы внимания последовательно на уровне слов и предложений, но также применим подход сверху вниз (например, уровни слов и символов). Следовательно, говорят, что этот тип механизмов дифференциально присутствует на более и менее важном контенте при конструировании представления документа.
Каждая функция пытается вычислить оценку выравнивания, указанную целевым скрытым состоянием ( h_t ) и исходными скрытыми состояниями ( h_s ).
| Имя | Формула для | Определяется |
|---|---|---|
| Точечный продукт | Luong et al. (2015) | |
| Масштабированный точечный продукт | Vaswani et al. (2017) | |
| Общий | Luong et al. (2015) | |
| Конг | Bahdanau et al. (2015) | |
| Расположение | Luong et al. (2015) |
где H - это количество скрытых состояний, данных энкодером RNN, и где W_a и v_a являются обучаемыми матрицами веса.
tf.keras.layers.Layer() .__init__() каждого пользовательского класса вызывает метод инициализации своего родителя и определяет дополнительные атрибуты, специфичные для каждого уровня.get_config() вызывает метод конфигурации своего родителя и определяет пользовательские атрибуты, введенные с слоем.build() , то он содержит обучаемые параметры. Например, принять слой Attention() , обратное распространение сигналов потерь, которые вводят, чтобы обеспечить большую помощь и, следовательно, указывает на изменение весов слоя.call() - это фактическая операция, которая выполняется на входных тензорах.compute_output_shape() избегаются для расстояния. Эти слои могут быть подключены к вашим проектам (будь то языковые модели или другие типы RNN) в течение нескольких секунд, как и любой другой тензорфлоу-слой с интеграцией Keras. См. Пример общего назначения, например:
from tensorflow.keras.layers import Input, Embedding, LSTM, Dense
from layers import Attention
X = Input(shape=(sequence_length,), batch_size=batch_size) # define input layer for summary
## Token Embedding (Pretrained or Not) ##
embedding = Embedding(input_dim=vocabulary_size, output_dim=embedded_dimensions)(X)
## Encoding Recurrent Layers ##
encoder = LSTM(units=recurrent_units, return_sequences=True)(embedding) # keep timesteps
## Decoding with Attention ##
decoder, attention_weights = Attention(context='many-to-one', alignment_type=attention_type, model_api='functional')(encoder)
## Prediction Layer ##
Y = Dense(units=vocabulary_size, activation='softmax')(decoder)
где alignment_type является одним из 'global' , 'local-m' , 'local-p' и 'local-p*' . Для собственного внимания вызовите слой SelfAttention(size=attention_size) .
Проверьте ниже подтопики для получения дополнительных примеров, анализов и сравнений. Для справедливого сравнения все сравниваемые модели используют аналогичные параметры. Например, размер партии 100 и ряд эпох 20 были предпочтительнее в некоторых примерах.
Вы можете найти пример классификации Comminiment Classification (много-один, бинарный) пример на набор данных IMBD внутри examples/sentiment_classification.py . В этом примере сравниваются три различные модели tf.keras.Model() ( функциональный API ) (все слова) и направлены на измерение эффективности реализованного уровня самостоятельного прихода по сравнению с обычной моделью MLP (Multi-Layer Perceptron). Обратитесь к таблице ниже для метрик:
| Идентификатор модели | Максимальная валидация двоичная точность |
|---|---|
| Простая многослойная модель персептрона | 0,8730 |
| Простая многослойная модель Perceptron с самоуничтожением (непреднамеренная) | 0,8907 |
| Простая многослойная модель Perceptron с самоуничтожением (наказанная) | 0,8870 |
Вы можете найти пример генерации текста (много-один) на наборе данных Шекспира внутри examples/text_generation.py . В этом примере сравниваются три различные модели tf.keras.Model() ( функциональный API ) (все символ) и направлены на измерение эффективности реализованных слоев внимания и самостоятельного присмотра над обычными моделями LSTM (длинная краткосрочная память). Обратитесь к таблице ниже для метрик:
| Идентификатор модели | Максимальная категориальная точность валидации |
|---|---|
| Модель LSTM | 0,5953 |
| Модель LSTM с самоуверенностью (непреднамеренная) | 0,6049 |
| Модель LSTM с вниманием | 0,6234 |
Вы можете найти пример классификации документа (новости) (много-один, многокласс) пример на наборе данных Reuters внутри examples/document_classification.py . В этом примере сравниваются четыре различные модели tf.keras.Model() ( функциональный API ) (все слова) и направлены на измерение эффективности реализованных слоев внимания и самостоятельного присмотра над обычными моделями LSTM (длинная краткосрочная память). Обратитесь к таблице ниже для метрик:
| Идентификатор модели | Максимальная категориальная точность валидации |
|---|---|
| Модель LSTM | 0,7210 |
| Модель LSTM с самоуверенностью (непреднамеренная) | 0,7790 |
| Модель LSTM с глобальным вниманием | 0,7496 |
| Модель LSTM с вниманием | 0,7446 |
Вы можете найти пример машинного перевода (от многих ко многим) на наборе данных по английскому и испаниям внутри examples/machine_translation.py . Этот пример в значительной степени следует за примером машинного перевода Tensorflow с некоторыми адаптациями. Он сравнивает четыре различные модели tf.keras.Model() ( функциональный API ) (все уровень слова) и направлен на измерение эффективности реализованного уровня внимания. Обратитесь к таблице ниже для метрик:
| Идентификатор модели | Максимальная категориальная точность валидации |
|---|---|
| Модель энкодера-декодера | 0,8848 |
| Модель энкодера-декодера с глобальным вниманием | 0,8860 |
| Модель Encoder-Decoder w/ local-m внимание | 0,9524 |
| Модель Encoder-Decoder w/ local-p внимание | 0,8873 |
Будь то ошибки, с которыми вы столкнулись, проблемы с производительностью или какой -либо вклад, который вы имеете в виду, это идеальное время, чтобы поделиться ими! Проверьте CONTRIBUTING.md для получения дополнительной информации и руководящих принципов по этой теме.


